一、MongoDB介绍
MongoDB是一个基于分布式文件存储 [1] 的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
二、MongoDB用法
-
1、MongoDB的增删改查
###########查 切换数据库:use test 注意:当该数据库不存在则会创建一个新的数据库 查看当前数据库:db 查看所有的数据库:show databases(简写dbs) 查看该数据库下的所有集合:show collections(show tables) 查看某个集合的内容:db.collection.find() ###########增 `db.test1.insert({_id:'5f618bd390edf95aa3cc6f81',name:'alex'})` #注意,当_id已存在时会报错 `db.test1.save({_id:"5f618bd390edf95aa3cc6f81", name:"alex1",age:18})` # 注意:当_id不存在时则新增,存在则更新 ###########删 `db.dropDatabase()` # 删除当前数据库 `db.test.remove({name:"xiaohong"},{justOne:1})` #默认删除所有满足条件的数据,使用`{justOne:true}`能达到只删除一条的效果 ###########改 `db.update({name:"xiaowang"},{name:"xiaogang"})` #把名字为xiaowang的数据替换成{name:"xiaogang"} `db.test.update({name:"xiaowang"},{$set:{name:"xiaogang"}})` #把{name:"xiaowang"}的name值更新为{name:"xiaogang"} `db.test.update({name:"xiaogang"},{$set:{name:"xiaohong"}},{multi:true})` #`{multi:true}`更新全部
-
2、MongoDB的高级查询
1、查询符合条件:db.collection.find({条件}) `db.stu.find({city:"深圳"})` 2、查询符合条件的一条数据:db.collection.findOne({条件}) `db.stu.findOne({city:"深圳"})` 3、`pretty()` 结果格式化,使数据更直观 `db.stu.find({city:"深圳"}).pretty()` 4、比较运算符 大于:$gt 小于:$lt 大于等于:$gte 小于等于:$lte 不等于:$ne `db.stu.find({age:{$lt:20}})` 4、范围运算符:$in `db.stu.find({age:{$in:[18,19,20]}})` 查询年龄在18-20范围内 5、逻辑运算符 (1)且(and),写多个条件即可 eq:查询年龄为18,并且城市在深圳的学生 `db.stu.find({age:18,city:"深圳"})` (2)或(or),$or eq:查询年龄为18或者城市在深圳的学生 db.stu.find({$or:[{age:18},{city:"深圳"}]}) 6、正则匹配,$regex eq:匹配以“小”为开头的名字的学生 `db.stu.find({name:{$regex:"^小"}})` 7、分页查询:limit和skip eq:查询前两条数据 `db.stu.find().limit(2)` eq:跳过前两条数据 `db.stu.find().skip(2)` 8、投影,选择返回的字段 eq:只显示姓名 `db.stu.find({age:{$lte:20}},{name:1})` 注意:默认_id会显示出来,`{_id:0}`可以不显示 9、排序:sort eq:降序 `db.stu.find().sort({age:1})` eq:升序 `db.stu.find().sort({age:-1})` 10、统计数量:count eq:统计年龄小于等于20或者城市为深圳的学生格式 方法一:`db.stu.find({$or:[{age:{$lte:20}},{city:"深圳"}]}).count()` 方法二:`db.stu.count({$or:[{age:{$lte:20}},{city:"深圳"}]})` 11、去重:distinct eq:查询年龄小于等于20的学生的城市 `db.stu.distinct("city",{age:{$lte:20}})`
-
3.MongoDB的备份和恢复
1、备份mongodump 参数:-h IP地址 --port=端口号 -d 数据库 -o 备份的目录 eq:mongodump --port=38000 -d test -o ~/ 2、恢复mongorestore mongorestore -h hostip -d dbname --dir dirname eq:mongorestore -d test -dir ~/test
-
4.聚合命令
聚合和Linux中的管道一样,即是将上一次的结果传给下一次使用
常用的管道: $group:分组,可用于统计结果 $match:筛选,只分析符合条件的文档 $project:修改输入的文档,如重命名、增加、删除字段,创建计算结果 $sort $limit $skip
-
(1)$group,处理输入的文档并输出
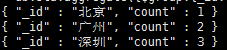
表达式: 1、$sum:求和 eq:统计每个地区的学生个数 `db.stu.aggregate({$group:{_id:"$city",count:{$sum:1}}})`
2、$avg:平均值 eq:统计每个地区的学生的年龄平均值 `db.stu.aggregate(
{$group:{_id:"$city",avg_age:{$avg:"$age"}}}
)`

eq:统计所有学生的总人数和平均年龄
`db.stu.aggregate(
{$group:{_id:"null",sum:{$sum:1},avg_age:{$avg:"$age"}}}
)`

3、$min:取最小值 4、$max:取最大值 5、$push:在结果文档中插入值到数组中 6、$first:取第一个文档 7、$last:取最后一个文档
-
(2)$project,修改格式
eq:统计所有学生的总人数和平均年龄,并且将_id这个字段名改为`city` `db.stu.aggregate( {$group:{_id:"$city",sum:{$sum:1},avg_age:{$avg:"$age"}}},
{$project:{city:"$_id",sum:1,avg_age:1,_id:0}} )`

-
(3)$match,筛选条件
eq:按不同的地区统计出年龄大于18岁的学生的人数,平均年龄 `db.stu.aggregate( {$match:{age:{$gte:18}}}, {$group:{_id:"$city",人数:{$sum:1},平均年龄:{$avg:"$age"}}}, {$project:{_id:0,城市:"$_id",人数:1,平均年龄:1}} )`
-
练习:
原数据:
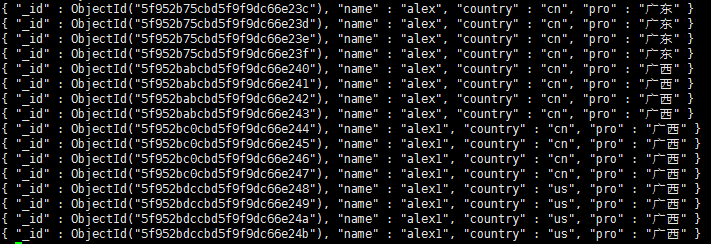
eq:先去重,再统计每个国家的人数
`db.country.aggregate(
{$group:{_id:{country:"$country",pro:"$pro",name:"$name"}}},
{$group:{_id:{country:"$_id.country"},sum:{$sum:1}}}
)`

(4)sort,limit,skip的使用
(1)sort:排序 eq:按城市进行分组,统计每个城市的学生的平均年龄,并排序 `db.stu.aggregate( {$group:{_id:"$city",平均年龄:{$avg:"$age"}}}, {$project:{城市:"$_id",_id:0,平均年龄:1}}, {$sort:{平均年龄:1}} )`
(2)limit:限制
eq:显示前两条数据
`db.stu.aggregate({$limit:2})`
(3)skip
eq:跳过前两条数据
`db.stu.aggregate({$skip:2})`

5.索引操作
建立索引: (1)唯一索引: `db.country.ensureIndex({name:1}{unique:true})` (2)组合索引: `db.country.ensureIndex({name:1,country:1})` 查看索引: `db.country.getIndexes()` 删除索引: `db.country.ensureIndex({name:1,country:1})`