这一篇我们简单的介绍一下Python学习的基本知识--》Python文件是如何运行、Python文件打开通常会有两行注释,那么这两行注释是什么;上篇提到的字节码,这些字节码都存储在哪?即pyc文件。
一、运行:
在D:python_test 目录下创建hello.py文件,其内容如下:
1 #! /user/bin/local/ python
2 # -*- coding:utf-8 -*-
3
4 print("hello world")
在Windows下运行Python文件,通常有两种方式:
一、打开终端---> C:Program FilesPython36python3.exe D:python_testhello.py,即输入Python3的运行路径+文件路径,即可运行python文件。
二、运行Python解释器 -->即打开C:Program FilesPython36python.exe执行python文件。
而在Python内部执行过程如下图:
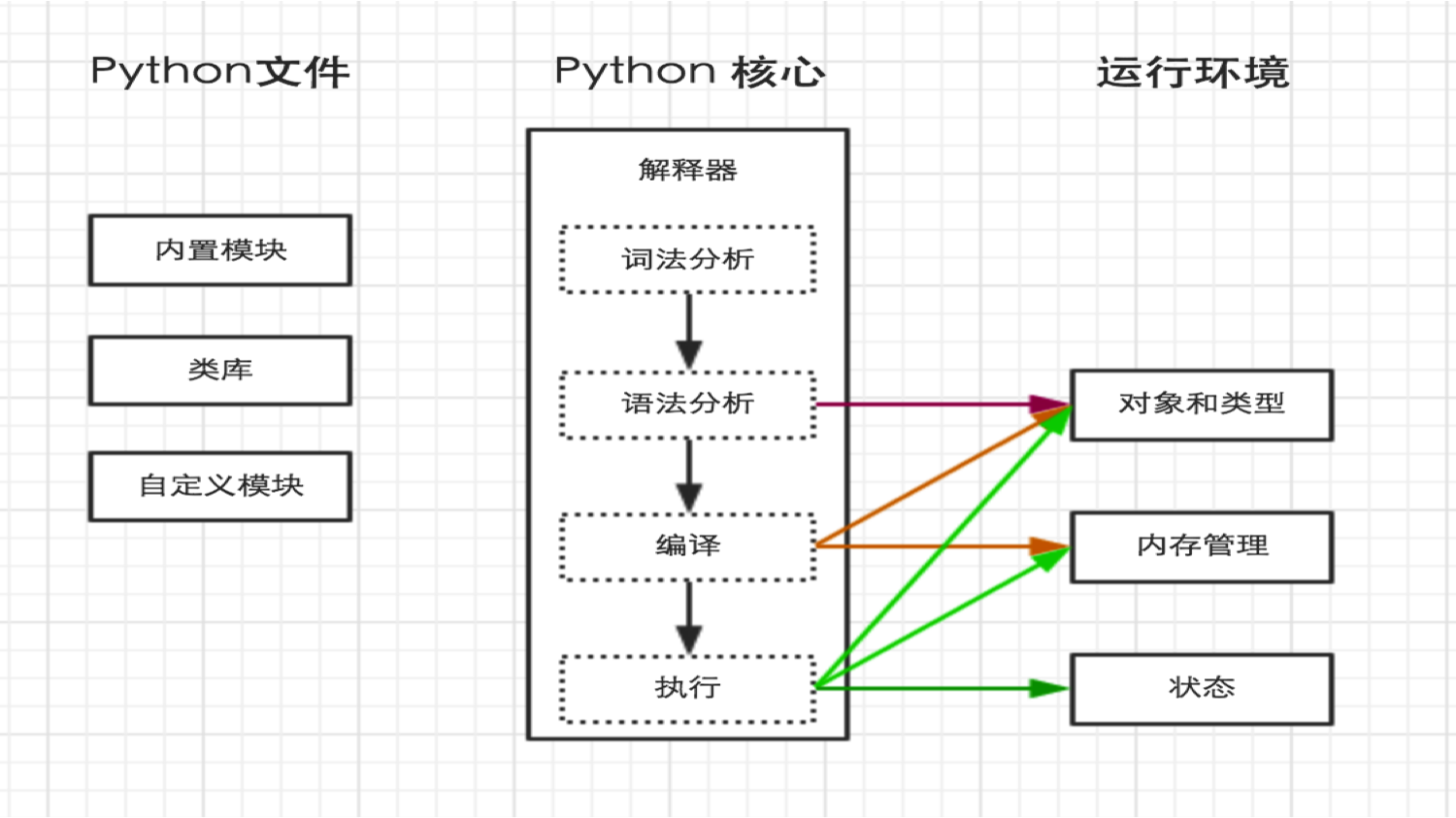
二、文件行
当我们打开Python文件时,通常会在文件的头部会有 #!/user/bin/local python,例:
#! /user/bin/local python
print(" hello world")
这意味着在Linux下执行时,打开文件时先读取首行,并通过其找到python解释器的路径,以此来执行该文件。若直接在Linux终端输入 :
>>> python hello.py
则加不加该句则无所谓。
而针对使用以下方法打开python文件时,这时候写上Python解释器执行路径是非常有必要的:
>>> ./hello.py
即直接执行该文件,但打开是需注意文件的权限,若其他用户无法打开该文件,通过该命令--> chmod o+x hello.py来修改文件执行。
三、编码
当我们打开python文件,除了会写明python解释器的执行路径,还通常会表明读取该文件是以何种编码执行:
# -*- coding:utf-8 -*-
print("hello world")
即表明该文件以utf-8的编码方式进行编码的,而在Python2中,默认是以ASCII码的编码方式进行编码的,故需加上这句来告诉Python解释器是以utf-8的编码方式进行编码的。
而在Python3中,文件的编码方式默认为utf-8编码方式。故加不加这句都无所谓。
常见的编码方式有以下几种:
ASCII码:ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
以下为ASCII码表:
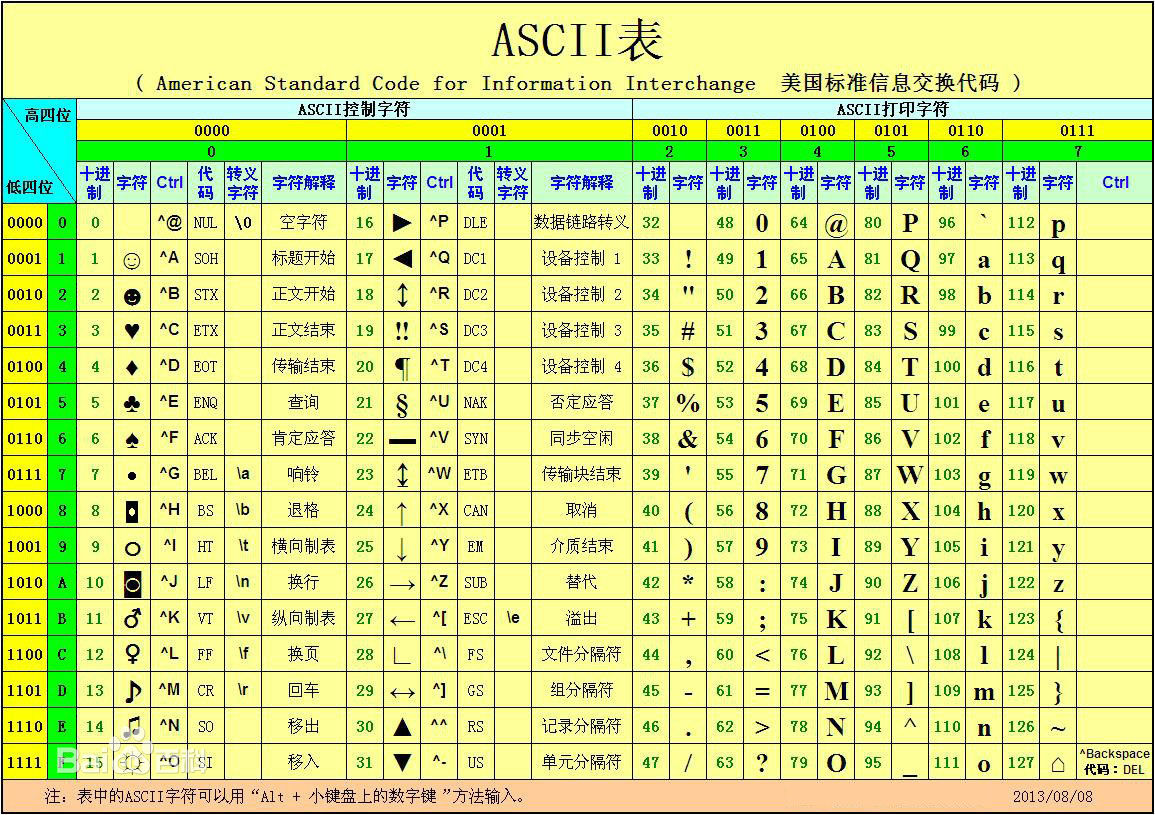
需要注意的是:大写的英文字母即 A~Z--->二进制转十进制后为 65~90。
小写的英文字母即 a~z--->二进制转十进制后为 97~122.
GBK编码 -->GBK编码为GB2312编码的扩展,GBK全名为汉字内码扩展规范,英文名Chinese Internal Code Specification。K 即是“扩展”所对应的汉语拼音(KuoZhan)中“扩”字的声母。
它规定一个中文为两个字节。
Unicode编码-->Unicode-->万国码,即当许多国家开始使用计算机,无论是中国的GBK还是日本的JIS等都无法同时进行编码,容易出现乱码等问题,例如想用八国语言
来写一篇文章,这样无论是GBK还是JIS都无法实现,故发明了Unicode,它包含了各种国家的编码方式,它规定一个字符用两个或者两个以上的字节来表示。
utf-8编码-->它是Unicode编码的压缩和优化,由于Unicode规定一个字符用两个或者两个以上的字节表示,故以前美国人使用ASCII码的时候,一个英文用一个字节来表示,因此浪费了许多内存空间,故由此便
出现了utf-8,它规定一个英文用一个字节表示,一个中文用三个字节表示。
等等。。
四、注释
当行注释---> #
多行注释 --> ''' ''' 或者 """ """,注也可使用多行注释来代表多行字符串。例如

#这是当行注释 ''' 这代表多行注释 第一句python代码---》hello world
''' info =''' name ='Little_five' age ='22' ''
五、 pyc 文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
记得我们上篇介绍C语言和Python、以及Java的区别时提到:
C语言为编译型语言--》代码编译得到机器码,机器码在CPU上直接执行。
Python为编译型还是解释型并不明确,姑且为解释型。---》代码编译得到字节码,再通过虚拟机执行字节码转换成机器码,最后由CPU执行。
而这里所说的字节码便便被存储在pyc文件内。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
六、变量
声明变量:变量即为值可以变化的量,由于值存储在内存中,故需要取出该值则需要一个指针,指向该内存地址能够取出该内存中的值,而这个指针就是变量名。
1 #! /user/bin/local python 2 #-*- coding:utf-8 -*- 3 4 name = 'Little-five
上述代码声明了一个变量,变量名为: name,变量name的值为:"Little-five"
变量的作用:昵称,其代指内存里某个地址中保存的内容
声明变量名的规则:
1、变量只能使用数字、字母、下划线‘_’
2、数字不能作为变量名的开头
3、以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'
4、同时需注意的是尽量不使用常用的类名、模块名等作为变量名
#!/usr/bin/local python # -*- coding: utf-8 -*- name ="little_five" _name ='xiaowu'
七、输入
input--->将用户输入的值变为字符串,并且可以将其赋值给某个变量名。例如:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name = input("please enter your name--->:")
print(name)