1。先要注册百度API成为开发者,
下面是开发者申请链接:
http://api.fanyi.baidu.com/api/trans/product/index
为方便使用,百度翻译开放平台提供了详细的接入文档,链接如下:
http://api.fanyi.baidu.com/api/trans/product/apidoc
在翻译文档中列出了详细的使用方法,以下是接入文档原文:
例:将apple从英文翻译成中文:
q=apple
from=en
to=zh
appid=2015063000000001
salt=1435660288
平台分配的密钥: 12345678
生成sign:
>拼接字符串1
拼接appid=2015063000000001+q=apple+salt=1435660288+密钥=12345678
得到字符串1 =2015063000000001apple143566028812345678
>计算签名sign(对字符串1做md5加密,注意计算md5之前,串1必须为UTF-8编码)
sign=md5(2015063000000001apple143566028812345678)
sign=f89f9594663708c1605f3d736d01d2d4
完整请求为:
签名sign的生成
通过Python提供的hashlib模块中的hashlib.md5()可以实现签名计算
以接入文档中的字符串为例:
- import hashlib
- m = '2015063000000001apple143566028812345678'
- m_MD5 = hashlib.md5(m)
- sign = m_MD5.hexdigest()
- print 'm = ',m
- print 'sign = ',sign
得到签名之后,按照接入文档中要求,生成URL请求,提交后可返回翻译结果。以下是接入文档提供的字段以及对应描述的截图:
{"from":"en","to":"zh","trans_result":[{"src":"apple","dst":"u82f9u679c"}]}
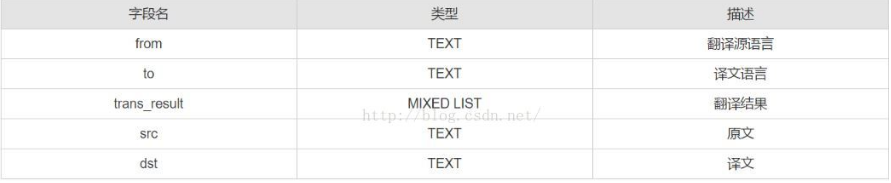
解析返回结果
提交URL后的返回值为json格式,使用json模块可以对结果进行解析:
- import json
- result = '{"from":"en","to":"zh","trans_result":[{"src":"apple","dst":"u82f9u679c"}]}'
- data = json.loads(result)
- print data['trans_result'][0]['dst']
以上就是API调用的所有程序。
--------------------------------------------------------------------------------------------------------------------------------------------------------------
官方给定的demo,经验证,可执行。
# -*- coding:utf-8 -*-
import httplib
import md5
import urllib
import random
import codecs
result = codecs.open('result1', 'w', encoding='utf-8')
appid = '20170406000044276'
secretKey = 'Q6g9YuaGq8Cqp0vnu2Cj'
httpClient = None
myurl = '/api/trans/vip/translate'
q = 'My name is Xiaobing.'
fromLang = 'en'
toLang = 'zh'
salt = random.randint(32768, 65536)
sign = appid + q + str(salt) + secretKey
m1 = md5.new()
m1.update(sign)
sign = m1.hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign
try:
httpClient = httplib.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
sentence = response.read()
print sentence.decode('unicode_escape')
#print sentence.encode('utf-8')
result.write(sentence.decode('unicode_escape'))
except Exception, e:
print e
finally:
if httpClient:
httpClient.close()
result.close()
---------------------------------------重新安装了Python版本3.6.2之后,因为Python的不兼容性,代码改为如下---------------------
import http.client
import hashlib
import json
import urllib
import random
def baidu_translate(content):
appid = '20170406000044276'
secretKey = 'Q6g9YuaGq8Cqp0vnu2Cj'
httpClient = None
myurl = '/api/trans/vip/translate'
q = content
fromLang = 'en' # 源语言
toLang = 'zh' # 翻译后的语言
salt = random.randint(32768, 65536)
sign = appid + q + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(
q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
jsonResponse = response.read().decode("utf-8") # 获得返回的结果,结果为json格式
js = json.loads(jsonResponse) # 将json格式的结果转换字典结构
dst = str(js["trans_result"][0]["dst"]) # 取得翻译后的文本结果
print(dst) # 打印结果
except Exception as e:
print(e)
finally:
if httpClient:
httpClient.close()
if __name__ == '__main__':
while True:
print("请输入要翻译的内容,如果退出输入q")
content = input()
if (content == 'q'):
break
baidu_translate(content)
------------------------------------------------------------------------------------------------------------------------------
单个句子的翻译目前没什么问题 但是替换成翻译一个文档的话 究竟文档的读写应该放在哪里比较效率高?翻译一句 就请求一次吗?还是怎么。。。
文件读写式的翻译:
#-*- coding: utf-8 -*-
import http.client
import hashlib
import json
import urllib
import random
import codecs
def baidu_translate(content):
appid = '20170406000044276'
secretKey = 'Q6g9YuaGq8Cqp0vnu2Cj'
httpClient = None
myurl = '/api/trans/vip/translate'
q = content
fromLang = 'zh' # 源语言
toLang = 'en' # 翻译后的语言
salt = random.randint(32768, 65536)
sign = appid + q + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(
q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
jsonResponse = response.read().decode("utf-8") # 获得返回的结果,结果为json格式
js = json.loads(jsonResponse) # 将json格式的结果转换字典结构
dst = str(js["trans_result"][0]["dst"]) # 取得翻译后的文本结果
print(dst) # 打印结果
return dst
except Exception as e:
print(e)
finally:
if httpClient:
httpClient.close()
if __name__ == '__main__':
inputFile = codecs.open("input.txt", "rb", "utf-8")
outputFile = codecs.open("output.txt","wb","utf-8")
for line in inputFile.readlines():
if line.split():
resultline = ''
content = line.split()
if content == 'q':
break
resultline = baidu_translate(str(content))
outputFile.write(resultline + "
")