(一)内存管理
内存管理指的是executor的内存管理。
1. 内存分类--堆内存和堆外内存
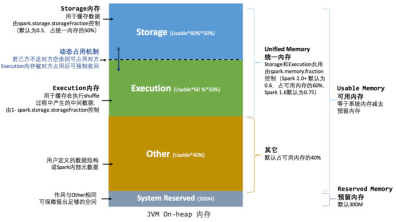
内存分类分为 堆内存和堆外内存。堆内存分为存储storage内存、execution运算内存、other内存。比例是6:2:2
堆内存:Executor内存管理是建立在JVM内存管理之上的。JVM内存就是堆(on-heap)内存。Spark堆JVM内存做了更加详细的划分,以充分利用堆内存。
堆外内存:spark还引入了堆外(off-heap)内存,直接在工作节点的系统内存中开辟空间。可以减少节省堆内存
堆内存是受JVM统一管理。Gc释放内存。堆外内存是直接向节点的操作系统申请和释放。主动申请和主动释放。换句话说。堆外内存我们可以完全控制申请、使用和释放的节奏。
堆内存是spark释放之后,等待JVM的GC。所以,spark释放后,可能仍然没有释放。而spark认为已经释放了。所以,堆内存可能实际的内存大小小于预估的内存大小。

存储内存storage:缓存RDD和广播Broadcast所占用的内存。
执行内存execution:存储执行shuffle中的中间数据。
Other内存:用户定义的数据结构或spark内部的元数据。
2. 内存空间分配
(1) 静态内存管理
存储内存、执行内存和其它内存的大小在spark的运行过程中是固定的。6-2-2

堆外内存的统计是准确的。无需预留空间。
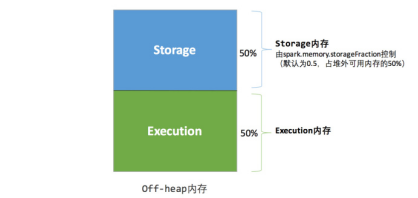
(2) 统一内存管理
存储内存和执行内存公享同一块空间。可以动态的占用对方的空闲区域。
3. 存储内存管理
RDD 有血缘依赖,RDD的转换是惰性的,只有在Action操作的时候才会被触发。所以,如果一个RDD被多次使用,没有缓存的话,就需要多次根据血缘关系加载,重复计算。因此,就需要对多次重复计算的RDD,第一次运行cache或者persist方法,在缓存中持久化这个RDD。
Cache和Persist的区别:cache 是存储级别为MEMORY_ONELY的Persist。
4. 执行内存管理
5. 广播变量、累加器
广播变量:广播变量允许编程者在每个Executor上保留外部数据的只读变量,而不是给每个任务发送一个副本。广播变量是每个executor一份。一个executor的所有task共享一份只读变量。
累加器:累加器是存在driver端,只允许被相关操作累加的变量。Spark提供多个节点对一个共享变量进行共享型的操作。
(二)SPARK 性能调优
1. 常规性能优化
(1) 最优资源配置:
根据环境的资源情况,尽可能多的使用资源。
(2) RDD优化
① 不同分支,相同运算。避免RDD的重复计算。RDD不同分支的相同运算尽量在父RDD中一次计算。类似面向对象中,子类相同的方法应该向上转移到父类中去。
② 相同分支,多次运算。增加持久化:对多次计算的RDD添加缓存。持久化到内存。
③ RDD尽早做Filter:和优化sql类似,优先减少操作的数据集。
(3) 并行度调节
并行度指的是各个stage中Task的数量。并行度的合理设置是需要和资源匹配的。Task应该是executor中core的倍数。一般推荐的是。Task的数量是core的2-3倍。
(4) 使用广播变量
如果task需要使用外部变量,每个task都回备份一份数据。造成资源浪费。可以使用广播这些外部变量。每个executor保存一份。每个task使用自己所在executor的变量。
2. 算子调优
(1) mapPartitions
Map和mapPartitions 的区别:map函数会对每条数据进行遍历读取。MapPartitions 会一个分区数据一次取全部,然后在内存中处理。
MapPartitions一次加载,容易造成OOM。
(2) foreachPartition
ForeachPartition 一般用在数据写入数据库。使用foreachPartition可以经每次操作公用的操作放在foreachPartition中。比如:数据库连接,可以每个分区做一次连接。而不需要每条数据做一次连接。
(3) filter与coalesce的配合使用
假设原始数据分配均匀。通过filter之后(不同分区可能过滤掉的数据大小不一),数据量上有倾斜。可以通过coaleasce或者 repartition重新分区。
(4) repartition解决SparkSQL低并行度问题
Spark Sql 加载原始文件成RDD的分区数 是原始分区数。可能和当前spark的资源数不匹配。这是大概率事件。所以,需要通过reparttition函数对其重分区。让并行度和资源数匹配。
(5) reduceByKey本地聚合
ReduceByKey 会在map端会先对本地的数据进行combine操作,然后将数据写入给下个stage的每个task创建的文件中。增加数据的聚合程度,较少数据量,从而提高效率。
3. shuffle调优
(1) 调节map端缓冲区大小
调节map端缓冲区大小。可以减少数据溢写的小文件个数。较少IO,从而调高效率。
(2) 调整reduce端拉去缓冲区大小
Reduce端缓冲区大小调整,可以影响到拉去数据的次数。较少网络传输的次数,从而提高效率。
(3) 调整reduce拉取数据间隔等待时间
适当调整reduce拉取数据间隔的等待时间
4. 数据倾斜
(1) Reduce join 转 map join
大小表Join。小表小于12M,对小表采用broadcast。将小表数据转成外部变量数据。通过广播变量到每个executor上。在map阶段就可以进行join。从而从根本上避免了shuffle。
(2) 对个别key对应数据量大的问题
可以将rdd通过过滤分为两个子rdd。分别处理之后,再合并。场景:[工作中,通常key为null或者”” ,在repatitions 的时候,会将这些特殊的数据在重分区的时候,人为的造成了数据倾斜]。
5. 个人经验
(1) 相同维度的计算,一次扫描,多次同时计算
Rdd的计算过程中,全表扫描是很耗时间的。所以,尽量渐少扫描的过程。能在同一个统计维度中能计算的,尽量在一次计算中去统计。应用场景【在相同的聚合条件中:对不同的字段进行计算,产生不同的指标】