Unix操作系统内核结构报告
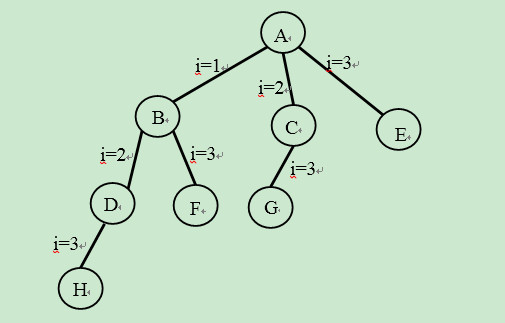
1、有一个程序的代码如下:
main()
{
int i ;
for(i=0; i<3; i++)
fork();
}
请问该程序运行时共建立了多少个进程?请用进程家族树来画出父子进程之间的关系。
解:一共建立了7个进程。
2、UNIX 系统中用“最近最少使用(LRU)” 算法来构建数据缓冲池。如果核心采用“先进先出(FIFO)”算法来构建缓冲池,则对缓冲区算法 getblk 来说,会造成功能上的区别主要有哪些?
解:getblk是把缓冲区分配给磁盘块的一个算法。用LRU或FIFO构建数据缓冲池时,主要是对空闲链表上的缓冲区的使用与释放的维护。
当用LRU时,getblk分配一个缓冲区的时候,每次从空闲链表的表头取下一个,当释放缓冲区时,若缓冲区有效且缓冲区非“旧”时,将该缓冲区放在空闲链表表尾,当缓冲区内容无效为“旧”时,将该缓冲区挂到表头。如果给该块分配缓冲区时,发现有缓冲区已经在散列队列里了,如果这块空闲,那么将这块也从空闲列表中取下来,用完之后再挂到空闲列表表尾。这样使得没有使用的或最长时间没有使用的缓冲区得到首先使用,这样满足进程的局部性原理,能够避免对缓冲区的重复申请。
当用FIFO时,getblk分配缓冲区则在一个先进先出的一个缓冲区队列上操作,即先使用的缓冲区会被再次首先使用。比如这里还是从表头操作,当用getblk从空闲链表表头得到一个缓冲区,使用完之后,挂到表尾。在每次重复使用并释放之后时不会改变其在空闲链表的位置,空闲链表在后序的getblk中将依次被使用。如果请求I/O的进程比较多,且请求同一块数据的进程多次getblk,那么由于以FIFO来构建数据缓冲池,会使得进程后续还要经常使用的缓冲区被其它进程使用,造成频繁的重新分配缓冲区,使得系统效率变低。
3、引用计数值为 2 的系统打开文件表(file 表)表项就一定表示有两个进程在共享该读写指针吗?为什么?
解:不一定。
UNIX系统open打开文件的过程通常是,首先在核心找到内存中的索引节点后,检查打开文件的许可权,然后为该文件在文件表中分配一个表项。在文件表表项中有一个指针,指向被打开文件的索引节点,还有一个域,指示文件中的偏移量,也就是核心预期下次读or写操作的地方。另外在用户文件描述符表中分配一个表项并记下该表项的索引,用户文件描述符表项指向对应的全局文件表中的表项。
每次open调用都导致在用户描述符表和核心文件表中分配一个唯一表项。但在核心的内存索引节点表中,每个文件和表项是一一对应的。
文件表中表项的引用计数值为2表示的含义是有2个用户文件描述符项指向该文件表表项,即有两个文件描述符共享偏移指针。
当只有一个进程的时候也可以使文件表表项引用计数值为2。例如当进程本来有一个文件描述符,通过系统调用dup将该文件描述符复制,返回一个新文件描述符,并且对应的文件表项引用计数+1。此时新描述符与旧描述符指向同一个文件表表项,该表项引用计数为2。
4、在变长目录项的目录结构中,每个目录项的长度都可能是不同的。请用伪代码设计一个简要的目录项申请(dir_get)和目录项释放(dir_release)的算法。
解:
#define MAXNAMLEN 255
struct direct{
long d_into; //目录i节点号
short d_reclen; //目录从起始位置到该目录项起始长度
short d_namelen; //目录项名字长度
char d_name[MAXNAME+1]; //名字字符串,+1为串结束符
}
stuct direct *p=(direct *)malloc(sizeof(direct)*100);
算法:dir_get
输入:目录名或路径名加新的目录项(eg:../lw/unix/works)
输出:(新的目录项)返回成功or失败
{
If(路径名)
{
namei(路径名),
分割出来目录名;
}
struct newdir= new direct;
在找到的相应目录表末尾中增加一项,
newdir.d_into=当前目录i节点号,
newdir.d_reclen=当前目录尾指针所指地址-目录起始地址+1,
newdir.d_namelen=sizeof(long)+2*sizeof(short)+sizeof(“目录名”),
newdir.d_name=”目录名”;
*(目录表项尾指针+1)=newdir;
目录表项尾指针=p+newdir.namelen;
回收newdir;
if(失败)
return -1;
return 0;
}
算法:dir_release
输入:目录名or路径名
输出:(删除目录名)成功or失败
{
If(路径名)
{
namei(路径名),
分割出来目录名;
}
找到相应的该目录索引节点,指针d指向该目录项;
获取结构中的目录项长度;
清空该项;
*指针d=*(指针d+目录项长度);//将删去目录项之后的那个目录项移动到前面,与该目录项合并
d.namelen=d.namelen+删去的目录项长度;
if(成功)
return 0;
return -1;
}
5、下面是一个捕俘“子进程死”软中断信号的程序:
#include <signal.h>
main()
{
extern catcher();
signal(SIGCLD, catcher);
if(fork() == 0)
exit();
pause(); /* 挂起执行,直到收到一个信号 */
}
catcher()
{
printf(“parent caught sig ”);
signal(SIGCLD, catcher);
}
该程序像许多软中断信号捕俘程序一样,在收到软中断信号后,重新设置软中断信号捕俘函数。请问该程序的运行结果可能是什么?
解:软中断信号通知进程发生了异步事件。本题是与进程终止相关的软中断信号。当进程退出时或当进程以子进程死(SIGCLD)为参数调用系统调用 signal时,发送这类软中断信号。内核仅当一个进程从核心态返回用户态时才处理软中断信号。
SIGCHLD 的语义为:子进程死的中断信信号,当用signal注册捕获该信号时,父进程需要调用一个 wait 函数来清理处于僵尸状态的子进程。(signal可以理解为,给该进程说明了哪些中断可以被保留在进程表的软中断信号域中)
程序运行可能有两种可能结果:
程序首先使用系统调用 signal 来捕俘“子进程死”软中断信号并打印父进程捕俘到信号(parent caught sig),然后调用 fork()创建一个子进程,此时子进程与父进程并发运行。
1、 若父进程先运行,父进程执行pause()先被挂起等待收到一个软中断信号;此时子进程执行exit(),成为僵尸状态,并发出一个软中断信号;父进程捕获到软中断信号时,执行catcher函数,定义完SIGCHLD所处理的方式之后,父进程执行完毕。
2、 若子进程先运行,即先调用exit()成为僵尸进程,则父进程收到子进程死的信号,执行了一次catcher(),并清理相应进程表项然后又重新注册了对子进程死的中断信号的捕获,然后父进程进入挂起状态,由于没有子进程死的中断信号的到来所以父进程将一直挂起。
6、硬盘读写完毕后,核心试图唤醒所有等待读写硬盘的睡眠进程。如果此时并没有这类睡眠进程,会发生什么情况?
解:内核通过保持一个称为数据缓冲区高速缓冲的内部数据缓冲区池来试图减少对磁盘的存取频率。高速缓冲含有最近被使用过的磁盘快的数据。当I/O完成时,磁盘控制器中断处理机,由磁盘中断处理程序唤醒正在睡眠的进程。如果此时没有这类睡眠进程,说明它们不再需要改缓冲区,内核将释放该缓冲区,以便其他进程能存取它。
内核会唤醒正在等待“无论哪个缓冲区变为空闲”这一事件发生的所有进程;唤醒正在等待“这个缓冲区变为空闲”这一事件所发生的所有进程。
7、终端驱动程序主要是使用了行规则系统来缓冲和处理进程与终端之间的数据I/O。如果进程与终端之间的数据 I/O 也通过数据缓冲区高速缓冲系统,而不是用行规则系统,将会发生什么情况?
解:行规则的作用是对输入和输出的数据进行解释,标准方式下,行规则把输入或输出的数据转化成标准形式,在原始方式下,只在进程和终端传送数据,不做转换。CPU的缓存主要是为CPU和内存提供一个高速的数据缓存区域。CPU读取数据的顺序是:先在缓存中寻找,找到后就直接进行读取,如果未能找到,才从主内存中进行读取。L1高速缓存也叫一级高速缓存,主要用于暂存CPU指令和数据,不同CPU的L1高速缓存各不相同。L1高速缓存对CPU的性能影响较大,其容量越大,CPU的性能也就越高。L2高速缓存也叫二级缓存,主要用于存放电脑运行时操作系统的指令、程序数据和地址指针等。CPU生产商都尽最大可能加大L2高速缓存的容量,并使其与CPU在相同频率下工作,来达到提高CPU性能的效果。缓存比内存的速度快。
故将行规则换成高速缓存以后,将在进程和终端极大提高数据传输速度,但不能对输入和输出的数据进行解释。这样用户和进程之间的数据传输速度过快,但接收的数据不是标准形式,不能读懂,还需要重新解释后才能使用。
8、假设要用“公平共享调度”策略来构建一个半实时半分时的进程调度系统,使得该系统既能在一定程度上满足快速响应(实时)进程的调度,又能适合普通分时进程的调度。请简述主要设计思想。
解:采用时间片轮转算法可以在一定程度上实现公平公正,因此在大家优先级等同的时候使用时间片轮转算法进行调度。但当系统中有迫切需求,需要系统能够及时响应的时候,可以由系统给改时间赋予一个高优先级,比如普通进程的优先级为0,系统优先级为5.系统转而执行高优先级的进程,直到改事件结束后,再判断系统中是否存在比普通优先级高的进程,如果有则执行,如果没有,则别的进程使用时间片轮转调度算法。