XML概述:
概念:
可扩展的标记语言。
功能:
- 作为数据本地存储的格式。(已淘汰)作为结构化存储的方式,不如数据库效率高。目前一部分移动设备中还在使用。
- 作为网络中传输数据的格式。(已淘汰)作为网络传输的格式,在目前以移动互联网为主的环境中,格式太大,所以已被JSON格式替代。
- 作为配置文件的格式存储配置信息(主要功能)
语法
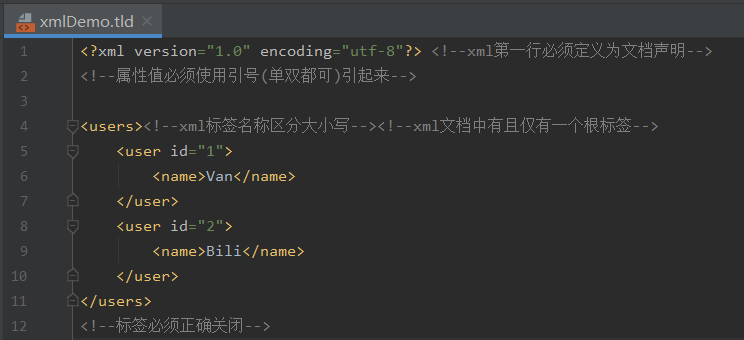
文本
内部的数据会忽略特殊字符,原样输出
约束
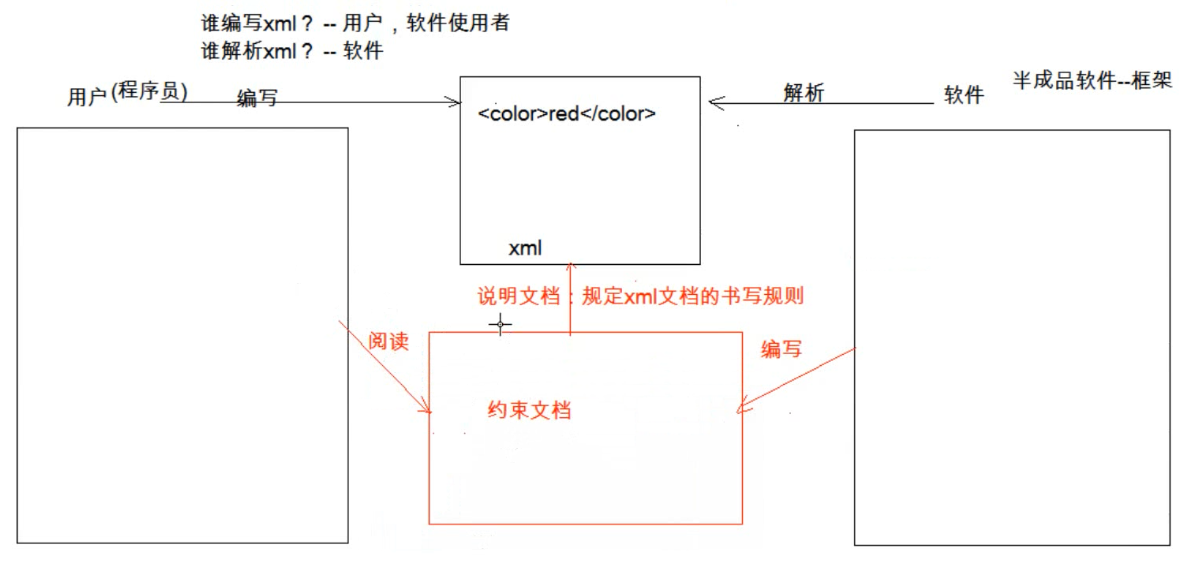
定义xml文档中可以出现的标签、属性及取值范围等限制条件
作用:
开发阶段,我们都是引入别人写好的约束文件使用。
报错:当我们编写或属性写错时可以有友好的提示
开发时的代码提示:提升开发效率。
约束分类:
dtd(逐渐淘汰)老牌的约束技术,有独立的语法。限制规则比较少
schema(新兴)在约束文档中
约束文档:

xmlns:xsd="http://www.w3.org/2001/XMLSchema"定义当前文档为约束文档,可以指定约束的规则
targetNamespace目标名称空间, 用于指定当前文档的名称空间。类似于java代码中的package关键字。
此处一旦定义了名称空间,那么在实例文档中引入当前约束文件时,必须指定该名称空间。
实例文档:
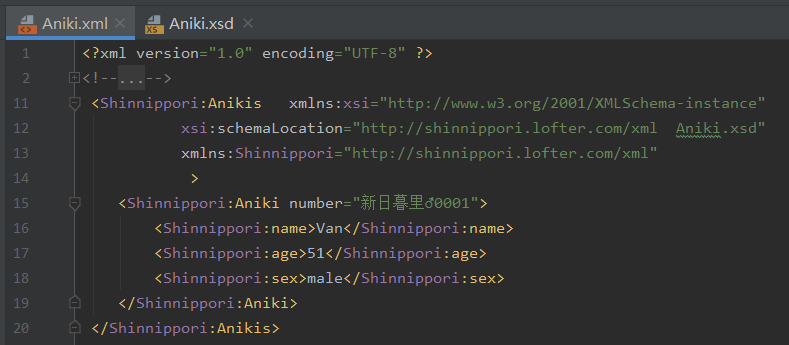
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"定义当前文档为实例文档,表示当前文档是被约束的,使用约束文件
xsi:schemaLocation="http://shinnippori.lofter.com/xml Aniki.xsd"引入名称空间http://shinnippori.lofter.com/xml,
实例文档中,除了w3c的约束之外,第三方自定义的约束,必须指定约束文件的地址Aniki.xsd(这里恰好是在一层目录内)。
格式:在schemaLocation中,依次编写key和value,key为名称空间的全名,value为约束文件的路径
如: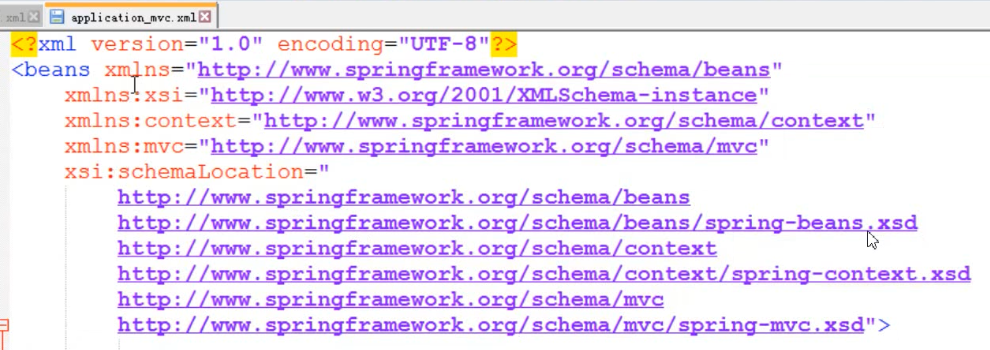
这里的名称空间/命名空间http://shinnippori.lofter.com/xml不是URL,是URI。
xml为了避免元素冲突,可以给元素加一个特别的前缀,但是必须给这个前缀定义一个命名空间,也就是必须用xmlns属性给这个前缀加一个特别的名字。这个名字必须是个URI。解析器不会用这个URI来查找信息,所以它可以是没有意义的,但实际上企业通常把命名空间指向一个真的含有相关信息的网址。
并可以为该名称空间起一个别名。xmlns:Shinnippori="http://shinnippori.lofter.com/xml"
一个xml中可以引入多个约束文件。类似于java中的import
一个xml中,最多可以有一个名称空间可以省略别名的定义。
解析:操作xml文档,将文档中的数据读取到内存中
操作xml文档
- 解析(读取):将文档中的数据读取到内存中
- 写入:将内存中的数据保存到xml文档中。持久化的存储
解析xml的方式:
DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树
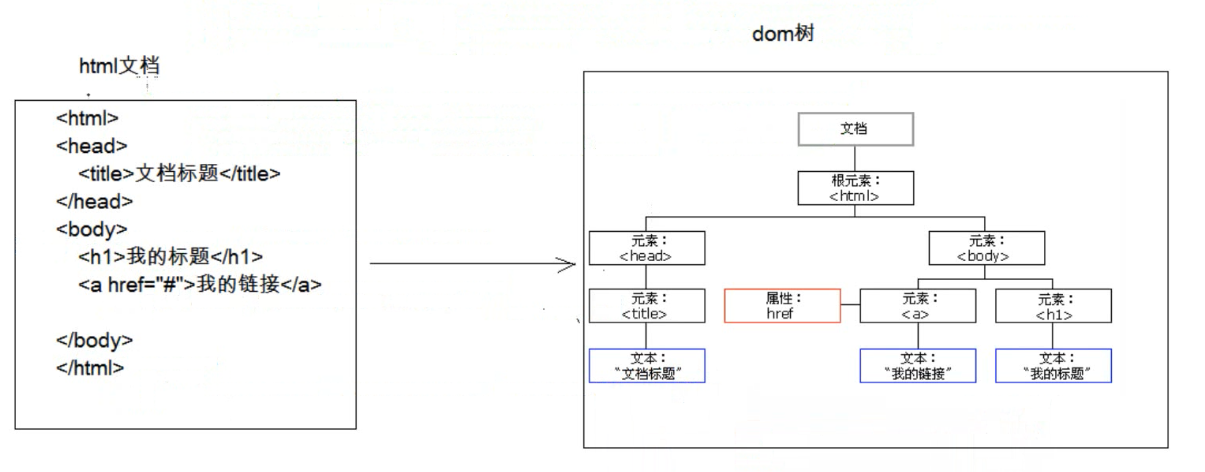
优点:操作方便,可以对文档进行增删改查的所有操作,速度比较快
缺点:占用内存比较多,并不适用于内存比较紧张的环境。
SAX:逐行读取,基于事件驱动的。
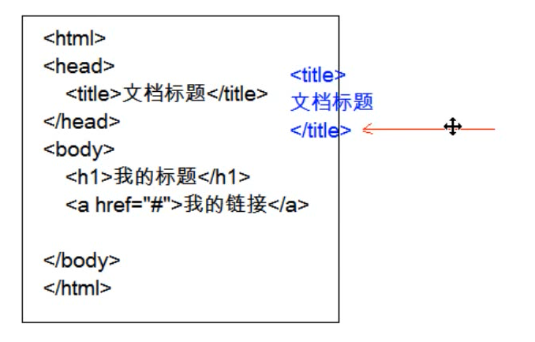
优点:占用内存非常少,每次只加载一行数据
缺点:只能读取,不能增删改,速度比较慢
实际上,很多xml解析的工具,在实现时,会同时采用这两种解析方式
xml常见的解析器:
1. JAXP:sun公司提供的解析器,支持dom和sax两种思想
2. DOM4J:一款非常优秀的解析器
3. Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
4. PULL:Android操作系统内置的解析器,sax方式的。
Jsoup使用步骤:
- 导入jar包
- 获取Document对象
- 获取对应的标签Element对象
- 获取数据
代码:
//2.1获取student.xml的path
String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象 Element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
对象的使用:
1. Jsoup:工具类,可以解析html或xml文档,返回Document
* parse:解析html或xml文档,返回Document
* parse(File in, String charsetName):解析xml或html文件的。
* parse(String html):解析xml或html字符串
* parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
2. Document:文档对象。代表内存中的dom树
* 获取Element对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
3. Elements:元素Element对象的集合。可以当做 ArrayList<Element>来使用
4. Element:元素对象
1. 获取子元素对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
2. 获取属性值
* String attr(String key):根据属性名称获取属性值
3. 获取文本内容
* String text():获取文本内容
* String html():获取标签体的所有内容(包括字标签的字符串内容)
5. Node:节点对象
* 是Document和Element的父类
快捷查询方式:
1. selector:选择器
使用的方法:Elements select(String cssQuery)
语法:参考Selector类中定义的语法,selector的语法和css的选择器语法保持一致,使用选择器方式获取xml中的元素,这种方式不通用
2. XPath:XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
使用Jsoup的Xpath需要额外导入jar包。
查询w3cshool参考手册,使用xpath的语法完成查询
代码:
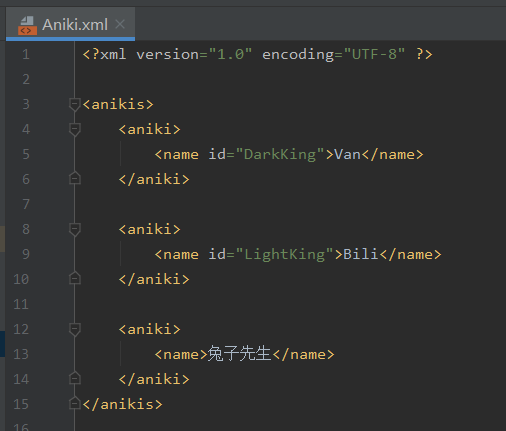


/ 代表绝对路径
// 代表无论层级下的路径
* 通配符,代表所有
/AAA/BBB[1]中括号中可以指定某个集合中的编号,从1开始
/AAA/BBB[last()]获取集合的最后一个
//BBB[@id]指定带有某个属性的元素
//BBB[@id='b1']选择某个属性等于指定值的元素
返回的是List<JXNode>或者JXNode,JXNode可以直接调用getElement转为原始的Element对##