参考:https://www.cnblogs.com/ywjfx/p/11352892.html
1、pom.xml添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-boot-hadoop-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--Lombok简化代码-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!-- hadoop依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2、application.yml文件
server: port: 8877 hadoop.name-node: hdfs://localhost:9000 hadoop.namespace: /mydir #log日志 logging: level: com: hadoop: demo: dao: debug
3、HdfsUtils.java
package com.example.demo; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.hdfs.DistributedFileSystem; import org.apache.hadoop.hdfs.protocol.DatanodeInfo; import java.io.IOException; import java.net.URI; /** * hdfs基本操作 */ @Slf4j public class HdfsUtils { /** * 获取文件系统 * @param hdfsUri nameNode地址 如"hdfs://10.10.1.142:9000" * @return */ public static FileSystem getFileSystem(String hdfsUri) { //读取配置文件 Configuration conf = new Configuration(); // 文件系统 FileSystem fs = null; if(StringUtils.isBlank(hdfsUri)){ // 返回默认文件系统 如果在 Hadoop集群下运行,使用此种方法可直接获取默认文件系统 try { fs = FileSystem.get(conf); } catch (IOException e) { log.error("", e); } }else{ // 返回指定的文件系统,如果在本地测试,需要使用此种方法获取文件系统 try { URI uri = new URI(hdfsUri.trim()); fs = FileSystem.get(uri,conf); } catch (Exception e) { log.error("", e); } } return fs; } /** * 创建文件目录 * * @param hdfsUri * @param path */ public static void mkdir(String hdfsUri, String path) { try { // 获取文件系统 FileSystem fs = getFileSystem(hdfsUri); if(StringUtils.isNotBlank(hdfsUri)){ path = hdfsUri + path; } // 创建目录 fs.mkdirs(new Path(path)); //释放资源 fs.close(); } catch (IllegalArgumentException | IOException e) { log.error("", e); } } /** * 删除文件或者文件目录 * * @param path */ public static void rmdir(String hdfsUri,String path) { try { // 返回FileSystem对象 FileSystem fs = getFileSystem(hdfsUri); if(StringUtils.isNotBlank(hdfsUri)){ path = hdfsUri + path; } // 删除文件或者文件目录 delete(Path f) 此方法已经弃用 fs.delete(new Path(path),true); // 释放资源 fs.close(); } catch (IllegalArgumentException | IOException e) { log.error("", e); } } /** * 根据filter获取目录下的文件 * * @param path * @param pathFilter * @return String[] */ public static String[] listFile(String hdfsUri, String path,PathFilter pathFilter) { String[] files = new String[0]; try { // 返回FileSystem对象 FileSystem fs = getFileSystem(hdfsUri); if(StringUtils.isNotBlank(hdfsUri)){ path = hdfsUri + path; } FileStatus[] status; if(pathFilter != null){ // 根据filter列出目录内容 status = fs.listStatus(new Path(path),pathFilter); }else{ // 列出目录内容 status = fs.listStatus(new Path(path)); } // 获取目录下的所有文件路径 Path[] listedPaths = FileUtil.stat2Paths(status); // 转换String[] if (listedPaths != null && listedPaths.length > 0){ files = new String[listedPaths.length]; for (int i = 0; i < files.length; i++){ files[i] = listedPaths[i].toString(); } } // 释放资源 fs.close(); } catch (IllegalArgumentException | IOException e) { log.error("", e); } return files; } /** * 文件上传至 HDFS * @param hdfsUri * @param delSrc 指是否删除源文件,true为删除,默认为false * @param overwrite * @param srcFile 源文件,上传文件路径 * @param destPath hdfs的目的路径 */ public static void copyFileToHDFS(String hdfsUri,boolean delSrc, boolean overwrite,String srcFile,String destPath) { // 源文件路径是Linux下的路径,如果在 windows 下测试,需要改写为Windows下的路径,比如D://hadoop/djt/weibo.txt Path srcPath = new Path(srcFile); // 目的路径 if(StringUtils.isNotBlank(hdfsUri)){ destPath = hdfsUri + destPath; } Path dstPath = new Path(destPath); // 实现文件上传 try { // 获取FileSystem对象 FileSystem fs = getFileSystem(hdfsUri); fs.copyFromLocalFile(srcPath, dstPath); fs.copyFromLocalFile(delSrc,overwrite,srcPath, dstPath); //释放资源 fs.close(); } catch (IOException e) { log.error("", e); } } /** * 从 HDFS 下载文件 * * @param srcFile * @param destPath 文件下载后,存放地址 */ public static void getFile(String hdfsUri, String srcFile,String destPath) { // 源文件路径 if(StringUtils.isNotBlank(hdfsUri)){ srcFile = hdfsUri + srcFile; } Path srcPath = new Path(srcFile); Path dstPath = new Path(destPath); try { // 获取FileSystem对象 FileSystem fs = getFileSystem(hdfsUri); // 下载hdfs上的文件 fs.copyToLocalFile(srcPath, dstPath); // 释放资源 fs.close(); } catch (IOException e) { log.error("", e); } } /** * 获取 HDFS 集群节点信息 * * @return DatanodeInfo[] */ public static DatanodeInfo[] getHDFSNodes(String hdfsUri) { // 获取所有节点 DatanodeInfo[] dataNodeStats = new DatanodeInfo[0]; try { // 返回FileSystem对象 FileSystem fs = getFileSystem(hdfsUri); // 获取分布式文件系统 DistributedFileSystem hdfs = (DistributedFileSystem)fs; dataNodeStats = hdfs.getDataNodeStats(); } catch (IOException e) { log.error("", e); } return dataNodeStats; } /** * 查找某个文件在 HDFS集群的位置 * * @param filePath * @return BlockLocation[] */ public static BlockLocation[] getFileBlockLocations(String hdfsUri, String filePath) { // 文件路径 if(StringUtils.isNotBlank(hdfsUri)){ filePath = hdfsUri + filePath; } Path path = new Path(filePath); // 文件块位置列表 BlockLocation[] blkLocations = new BlockLocation[0]; try { // 返回FileSystem对象 FileSystem fs = getFileSystem(hdfsUri); // 获取文件目录 FileStatus filestatus = fs.getFileStatus(path); //获取文件块位置列表 blkLocations = fs.getFileBlockLocations(filestatus, 0, filestatus.getLen()); } catch (IOException e) { log.error("", e); } return blkLocations; } /** * 判断目录是否存在 * @param hdfsUri * @param filePath * @param create * @return */ public boolean existDir(String hdfsUri,String filePath, boolean create){ boolean flag = false; if (StringUtils.isEmpty(filePath)){ return flag; } try{ Path path = new Path(filePath); // FileSystem对象 FileSystem fs = getFileSystem(hdfsUri); if (create){ if (!fs.exists(path)){ fs.mkdirs(path); } } if (fs.isDirectory(path)){ flag = true; } }catch (Exception e){ log.error("", e); } return flag; } }
4、HadoopConfig.java
package com.example.demo; import lombok.extern.slf4j.Slf4j; import org.apache.hadoop.fs.FileSystem; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.net.URI; @Configuration @ConditionalOnProperty(name="hadoop.name-node") @Slf4j public class HadoopConfig { @Value("${hadoop.name-node}") private String nameNode; /** * Configuration conf=new Configuration(); * 创建一个Configuration对象时,其构造方法会默认加载hadoop中的两个配置文件, * 分别是hdfs-site.xml以及core-site.xml,这两个文件中会有访问hdfs所需的参数值, * 主要是fs.default.name,指定了hdfs的地址,有了这个地址客户端就可以通过这个地址访问hdfs了。 * 即可理解为configuration就是hadoop中的配置信息。 * @return */ @Bean("fileSystem") public FileSystem createFs() throws Exception{ //读取配置文件 org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration(); conf.set("fs.defalutFS", nameNode); conf.set("dfs.replication", "1"); FileSystem fs = null; //conf.set("fs.defaultFS","hdfs://ns1"); //指定访问hdfs的客户端身份 //fs = FileSystem.get(new URI(nameNode), conf, "root"); // 文件系统 // 返回指定的文件系统,如果在本地测试,需要使用此种方法获取文件系统 try { URI uri = new URI(nameNode.trim()); fs = FileSystem.get(uri,conf,"root"); } catch (Exception e) { log.error("", e); } System.out.println("fs.defaultFS: "+conf.get("fs.defaultFS")); return fs; } }
5、HadoopTemplate.java
package com.example.demo; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.autoconfigure.condition.ConditionalOnBean; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; import java.io.IOException; @Component @ConditionalOnBean(FileSystem.class) @Slf4j public class HadoopTemplate { @Autowired private FileSystem fileSystem; @Value("${hadoop.name-node}") private String nameNode; @Value("${hadoop.namespace:/}") private String nameSpace; @PostConstruct public void init(){ existDir(nameSpace,true); } public void uploadFile(String srcFile){ copyFileToHDFS(false,true,srcFile,nameSpace); } public void uploadFile(boolean del,String srcFile){ copyFileToHDFS(del,true,srcFile,nameSpace); } public void uploadFile(String srcFile,String destPath){ copyFileToHDFS(false,true,srcFile,destPath); } public void uploadFile(boolean del,String srcFile,String destPath){ copyFileToHDFS(del,true,srcFile,destPath); } public void delFile(String fileName){ rmdir(nameSpace,fileName) ; } public void delDir(String path){ nameSpace = nameSpace + "/" +path; rmdir(path,null) ; } public void download(String fileName,String savePath){ getFile(nameSpace+"/"+fileName,savePath); } /** * 创建目录 * @param filePath * @param create * @return */ public boolean existDir(String filePath, boolean create){ boolean flag = false; if(StringUtils.isEmpty(filePath)){ throw new IllegalArgumentException("filePath不能为空"); } try{ Path path = new Path(filePath); if (create){ if (!fileSystem.exists(path)){ fileSystem.mkdirs(path); } } if (fileSystem.isDirectory(path)){ flag = true; } }catch (Exception e){ log.error("", e); } return flag; } /** * 文件上传至 HDFS * @param delSrc 指是否删除源文件,true为删除,默认为false * @param overwrite * @param srcFile 源文件,上传文件路径 * @param destPath hdfs的目的路径 */ public void copyFileToHDFS(boolean delSrc, boolean overwrite,String srcFile,String destPath) { // 源文件路径是Linux下的路径,如果在 windows 下测试,需要改写为Windows下的路径,比如D://hadoop/djt/weibo.txt Path srcPath = new Path(srcFile); // 目的路径 if(StringUtils.isNotBlank(nameNode)){ destPath = nameNode + destPath; } Path dstPath = new Path(destPath); // 实现文件上传 try { // 获取FileSystem对象 fileSystem.copyFromLocalFile(srcPath, dstPath); fileSystem.copyFromLocalFile(delSrc,overwrite,srcPath, dstPath); //释放资源 // fileSystem.close(); } catch (IOException e) { log.error("", e); } } /** * 删除文件或者文件目录 * * @param path */ public void rmdir(String path,String fileName) { try { // 返回FileSystem对象 if(StringUtils.isNotBlank(nameNode)){ path = nameNode + path; } if(StringUtils.isNotBlank(fileName)){ path = path + "/" +fileName; } // 删除文件或者文件目录 delete(Path f) 此方法已经弃用 fileSystem.delete(new Path(path),true); } catch (IllegalArgumentException | IOException e) { log.error("", e); } } /** * 从 HDFS 下载文件 * * @param hdfsFile * @param destPath 文件下载后,存放地址 */ public void getFile(String hdfsFile,String destPath) { // 源文件路径 if(StringUtils.isNotBlank(nameNode)){ hdfsFile = nameNode + hdfsFile; } Path hdfsPath = new Path(hdfsFile); Path dstPath = new Path(destPath); try { // 下载hdfs上的文件 fileSystem.copyToLocalFile(hdfsPath, dstPath); // 释放资源 // fs.close(); } catch (IOException e) { log.error("", e); } } public String getNameSpace(){ return nameSpace; } }
6、HdfsController.java
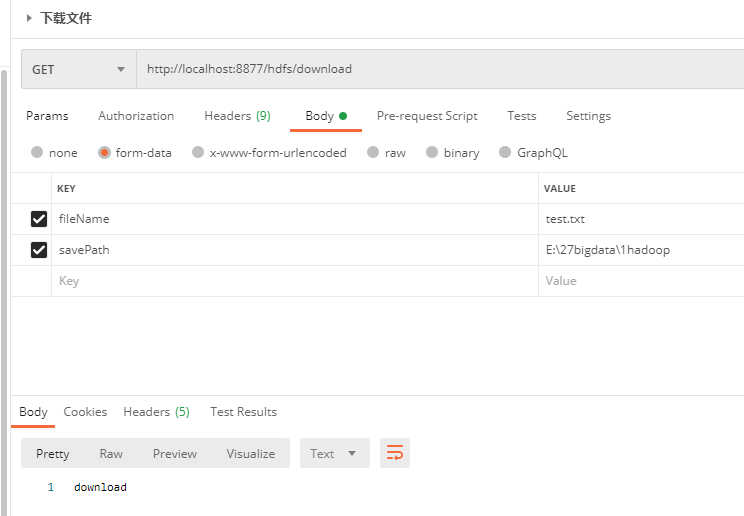
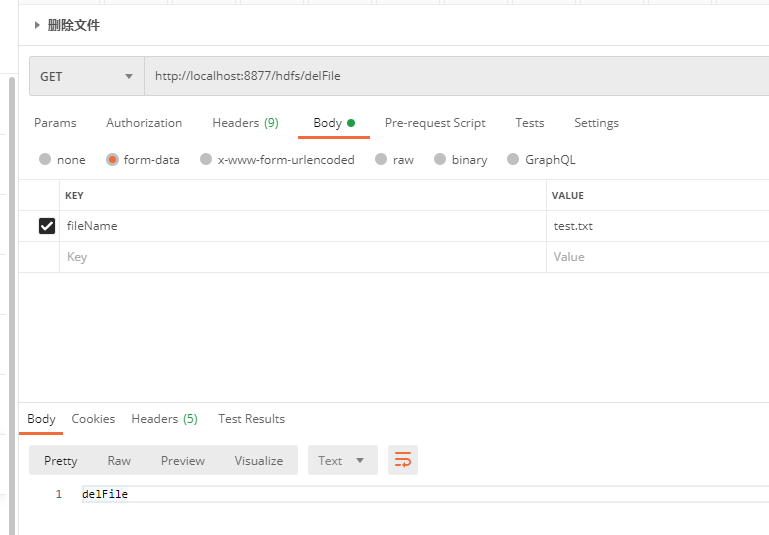
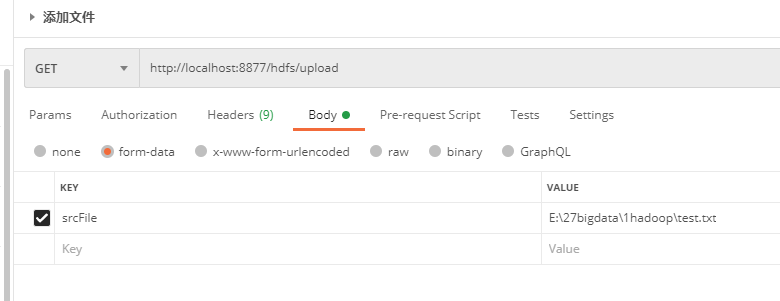
package com.example.demo; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; @RequestMapping("/hdfs") @RestController public class HdfsController { @Autowired private HadoopTemplate hadoopTemplate; /** * 将本地文件srcFile,上传到hdfs * @param srcFile * @return */ @RequestMapping("/upload") public String upload(@RequestParam String srcFile){ hadoopTemplate.uploadFile(srcFile); return "upload"; } @RequestMapping("/delFile") public String del(@RequestParam String fileName){ hadoopTemplate.delFile(fileName); return "delFile"; } @RequestMapping("/download") public String download(@RequestParam String fileName,@RequestParam String savePath){ hadoopTemplate.download(fileName,savePath); return "download"; } }
遇到的问题:
1、上传文件时报错:
There are 0 datanode(s) running and no node(s) are excluded in this operation.
解决方案:
解决方法1:重启linux,再使用start-dfs.sh和start-yarn.sh 重启一下hadoop
解决办法2:找到hadoop安装目录下 hadoop-2.4.1/data/dfs/data里面的current文件夹删除
然后从新执行一下 hadoop namenode -format
2、因为修改了hadoop的环境变量,上传时路径不对。 重启win10后就可以了。
postMan测试:
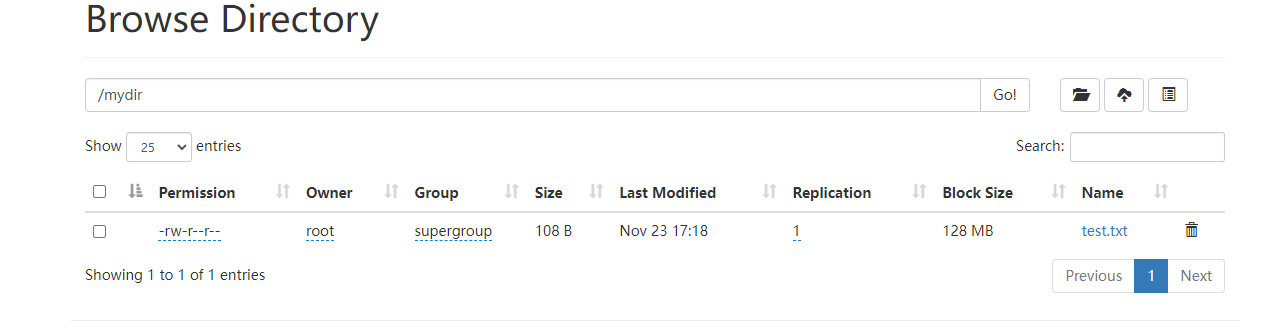
hadoop浏览上传的文件: