作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
相信大家都有在腾讯视频上看过视频,那大家是否知道腾讯视频里有个【热搜榜】,它是用户们所搜索的视频热度排行榜。
那么今天我们就来爬爬看,大家都在腾讯视频上看些什么!
【腾讯视频热搜榜】

首先,热搜榜分成了【全部】 【总榜单】 【电视剧】 【综艺】 【动漫】 【少儿】 【电影】 【纪录片】 【娱乐】 【明星】 【游戏】 【音乐】 【热点】十三个模块进行统计,
我从中抽取了几个我们平时看得比较多的模块进行分析,先来看下总榜单的数据~大家大部分是在看些什么!
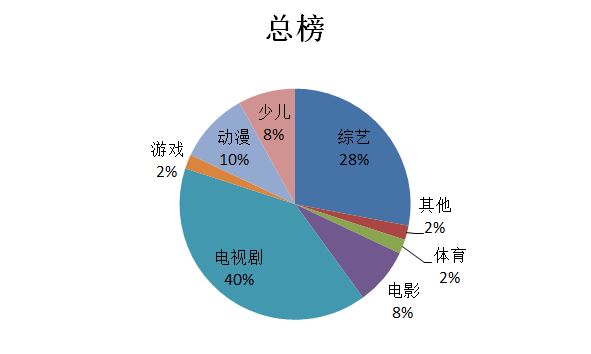
数据显示:占比最大的果然还是电视剧,紧跟着的就是综艺,剩下的基本比例差不多。
另外,总榜排行的前三的分别是最近很火的综艺:1.王牌对王牌 第四季 2.创造营 还有电视剧 3.都挺好
既然综艺那么多人看,那么我们就来看看大家都在看些什么综艺,哪些综艺最受观众们欢迎呢?
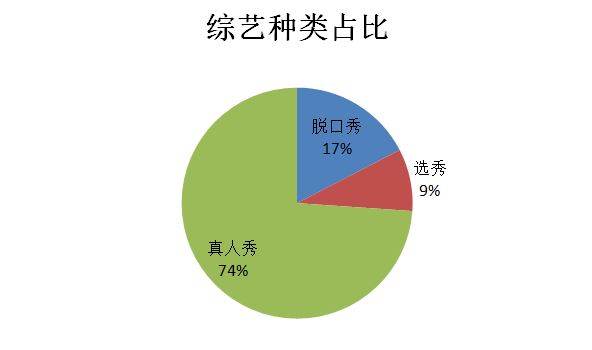
最受欢迎的还是真人秀综艺,看来比起配有固定台词的节目,更加喜欢现场直播,没有剧本的真人秀节目!
虽然最近的选秀节目创造营很火,但毕竟这种选秀节目在中国还是比较少,所以占比并不大。
之后我们来看看有关于电视剧类型的词云图,看看哪些电视剧最受大众欢迎!

可见映入眼帘的是“古装”、“家庭”、“爱情”、“奇幻”这几个关键词偏大众喜欢,这就是大众偏爱的电视剧类型。
像前阵子单单是古装片爆红的就不下五部:《延禧攻略》、《东宫》、《香蜜沉沉烬如霜》、《皓镧传》、《宫心计2深宫计》等等,
因此也能解释为什么现在的导演都喜欢拍这些类型的剧!因为观众爱看~
看完电视剧,我们再来看看电影吧!
以下是电影类型的词云图:

一眼可以看出“喜剧”、“科幻”、“爱情”、“动作”这四个关键词在图中显示最大,也就说明大家都是对这方面的电影有所偏爱。
因此,排行榜上的也都是这几种类型的电影,像排行榜上位于前列的《复仇者联盟》、《飞驰人生》都是属于科幻和喜剧的。
那么这些电影多数是哪里产出的呢?看看电影的分布地区图:
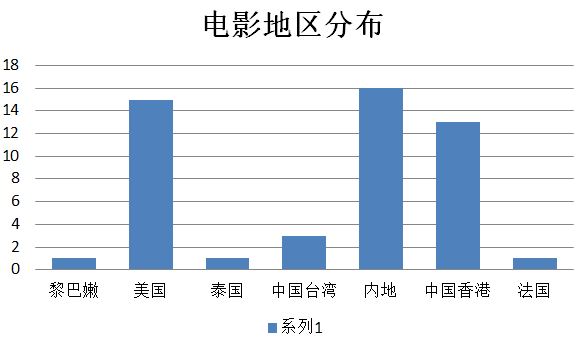
排名最高的内地,其次是美国和香港,这些地方都是我们熟知的拍电影比较有名的地方,
因此大家喜欢的电影大部分都是来自这几个地方。
接下来我们又来看看动漫区的数据,以下是动漫种类柱形图:
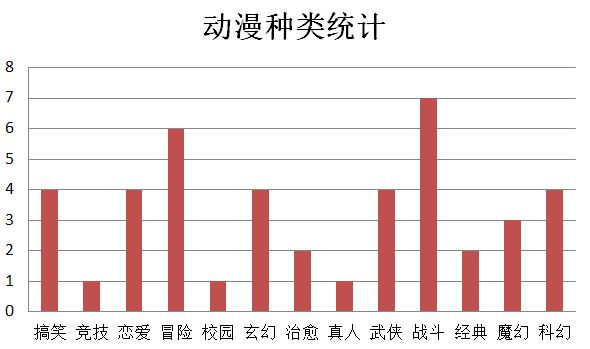
可见比起温馨浪漫的额动漫,热血冒险的动漫更受大家欢迎,因此观看的人也比较多。
像排行榜上前三的《斗罗大陆》、《斗破苍穹特别篇2沙之澜歌》还有《狐妖小红娘》等这些都是冒险、武侠、战斗的动漫。
分析大人所喜欢看的视频之后,我们现在来分析一下小朋友喜欢看的视频有哪些?
看看【少儿】频道里,小朋友都在看什么类型的视频,以下是少儿视频类型的词云图:

所见是一些都是小朋友喜欢的词语“动物”、男孩子喜欢的“战斗冒险”、还有可以和爸爸妈妈一起看的“合家欢”系列的动画片。
像排行榜上的第一位《小猪佩琪》不仅仅是小朋友喜欢看的动画片,在大人里也是十分受欢迎的。
之后我们再看看纪录片的地区分布情况:

其实结果是比较出乎我意料的!本来想着应该基本上都是内地的,但是结果发现只有一半多点是属于内地地区。
第二个占比的是英国,第三是美国。上网查找资料发现这两个国家的纪录片都拍得比较好,因此尽管在国内也有许多人观看。
以上是对腾讯视频中排行榜数据的爬取和分析,从七个角度去分析出大家喜好视频的种类和地区,总结出了大众观看的视频到底是怎么样的。
所用的数据汇总:
表格汇总:
总结:这次的爬虫作业刚好解开了我平时一直存在的疑惑,大家平常上网都在看些什么视频。借着这次作业就爬取了腾讯视频的热搜排行榜。经过这次的数据分析,发现大家都偏爱看电视剧比较多,无论是网剧还是现播剧都备受观众喜爱。除去电视剧,紧接着的就是电影和综艺,占得比例也比较大,看来大家平时看的视频都差不多是这几种类型的视频。
部分主要代码(因为代码有重复部分,下面以爬取【少儿】频道为例):


1 import requests 2 import csv 3 from lxml import etree 4 import pandas as pd 5 import pymysql 6 import random 7 from sqlalchemy import create_engine 8 #爬取【少儿】数据 9 r = requests.get("https://v.qq.com/x/hotlist/search/?channel=106").text 10 selector = etree.HTML(r) 11 li = selector.xpath("/html/body/div[3]/div/div/div[2]/ul/li") 12 d = [] 13 for i in li: 14 c = [] 15 num = i.xpath("./div[1]/span") 16 if num: 17 c.append(num[0].text) 18 title = i.xpath("./div[1]/a") 19 if title: 20 c.append(title[0].text) 21 place = i.xpath("./div[2]/a[1]") 22 if place: 23 c.append(place[0].text) 24 d.append(c) 25 kind = i.xpath("./div[2]/a[2]") 26 if kind: 27 c.append(kind[0].text) 28 29 30 # #爬取【动漫】数据 31 # r = requests.get("https://v.qq.com/x/hotlist/search/?channel=3").text 32 # selector = etree.HTML(r) 33 # li = selector.xpath("/html/body/div[3]/div/div/div[2]/ul/li") 34 # b = [] 35 # for i in li: 36 # c = [] 37 # num = i.xpath("./div[1]/span") 38 # if num: 39 # c.append(num[0].text) 40 # title = i.xpath("./div[1]/a") 41 # if title: 42 # c.append(title[0].text) 43 # place = i.xpath("./div[2]/a[1]") 44 # if place: 45 # c.append(place[0].text) 46 # d.append(c) 47 # kind = i.xpath("./div[2]/a[2]") 48 # if kind: 49 # c.append(kind[0].text) 50 51 # #爬取【电影】数据 52 # r = requests.get("https://v.qq.com/x/hotlist/search/?channel=1").text 53 # selector = etree.HTML(r) 54 # li = selector.xpath("/html/body/div[3]/div/div/div[2]/ul/li") 55 # d = [] 56 # for i in li: 57 # c = [] 58 # num = i.xpath("./div[1]/span") 59 # if num: 60 # c.append(num[0].text) 61 # title = i.xpath("./div[1]/a") 62 # if title: 63 # c.append(title[0].text) 64 # place = i.xpath("./div[2]/a[1]") 65 # if place: 66 # c.append(place[0].text) 67 # d.append(c) 68 # kind = i.xpath("./div[2]/a[2]") 69 # if kind: 70 # c.append(kind[0].text) 71 72 # #爬取【电视剧】数据 73 # r = requests.get("https://v.qq.com/x/hotlist/search/?channel=2").text 74 # selector = etree.HTML(r) 75 # li = selector.xpath("/html/body/div[3]/div/div/div[2]/ul/li") 76 # d = [] 77 # for i in li: 78 # c = [] 79 # num = i.xpath("./div[1]/span") 80 # if num: 81 # c.append(num[0].text) 82 # title = i.xpath("./div[1]/a") 83 # if title: 84 # c.append(title[0].text) 85 # place = i.xpath("./div[2]/a[1]") 86 # if place: 87 # c.append(place[0].text) 88 # d.append(c) 89 # kind = i.xpath("./div[2]/a[2]") 90 # if kind: 91 # c.append(kind[0].text) 92 93 # #爬取【综艺】数据 94 # r = requests.get("https://v.qq.com/x/hotlist/search/?channel=10").text 95 # selector = etree.HTML(r) 96 # li = selector.xpath("/html/body/div[3]/div/div/div[2]/ul/li") 97 # d = [] 98 # for i in li: 99 # c = [] 100 # num = i.xpath("./div[1]/span") 101 # if num: 102 # c.append(num[0].text) 103 # title = i.xpath("./div[1]/a") 104 # if title: 105 # c.append(title[0].text) 106 # place = i.xpath("./div[2]/a[1]") 107 # if place: 108 # c.append(place[0].text) 109 # d.append(c) 110 # kind = i.xpath("./div[2]/a[2]") 111 # if kind: 112 # c.append(kind[0].text) 113 114 # #爬取【总榜单】数据 115 # r = requests.get("https://v.qq.com/x/hotlist/search/?channel=0").text 116 # selector = etree.HTML(r 117 # li = selector.xpath("/html/body/div[3]/div/div/div[2]/ul/li") 118 # d = [] 119 # for i in li: 120 # c = [] 121 # num = i.xpath("./div[1]/span") 122 # if num: 123 # c.append(num[0].text) 124 # title = i.xpath("./div[1]/a") 125 # if title: 126 # c.append(title[0].text) 127 # place = i.xpath("./div[2]/a[1]") 128 # if place: 129 # c.append(place[0].text) 130 # d.append(c) 131 # kind = i.xpath("./div[2]/a[2]") 132 # if kind: 133 # c.append(kind[0].text) 134 135 # 导成csv文件 136 out = open("children.csv","a") 137 csv_writer = csv.writer(out,dialect='excel') 138 csv_writer.writerow(["序号","节目名称","地区","类型"]) 139 for text in d: 140 csv_writer.writerow(text) 141 142 #导成数据库 143 conInfo = "mysql+pymysql://root@host:port/txsp?charset=utf8"#连接数据库 144 engine = create_engine(conInfo,encoding='utf-8') 145 df = pd.DataFrame(d) 146 df.to_sql(name='phb', con=engine, if_exists='append', index=False)#建表