摘要
我们提出一些YOLO的更新!我们做了一些小的改进使它更好。我们还训练了一个新的相当好的网络。它比上次更大,但是更准确。不用担心它仍然很快。320x320的YOLOv3运行时间是22ms且有28.2mAP,这和SSD的准确率一样,但是比SSD快3倍。当我们从以往的0.5IOU的mAP检测度量来看,YOLOv3是相当好的。它在Titan X上以51ms实现了57.9$AP_{50}$的性能,与RetinaNet的198ms、57.5$AP_{50}$相比,相似的性能但是快了3.8倍。与往常一样,所有的代码都在https://pjreddie.com/yolo/.
1 介绍
你知道吗?有时候你只是糊弄了一年。我今年没有做很多研究。花了太多时间在推特上。玩了一点GANs。去年我留下了一点动力[12][1];我设法对YOLO做了一些改进。但是诚实地说,没有什么特别有趣的事,只是一点小的改变让它更好。我也帮助其他人做了一点研究。
事实上,那就是今天带给我们的。我们有一个终稿deadline[4],并且我们需要引用一些我对YOLO做的一些随机更新,但是我没有来源。所以准备了一个技术报告!
关于技术报告的好处是他们不需要介绍,你们都知道我们为什么在这。因此这篇介绍的结尾将为论文的其余部分提供路标。首先我们将告诉你YOLOv3的处理方式。然后我们将告诉你我们如何做的。我们也将告诉你一些我们努力做却没有效果的工作。最终我们将考虑这一切意味着什么。
2 处理方式
因此这是YOLOv3的处理方式:我们采取了很多其他人的好想法。我们也训练了一个比其他人更好的分类网络。我们将带你从头走一遍整个系统以便你可以完全理解它。
2.1 边界框预测
和YOLO9000一样我们的系统用维度聚类预测边界框作为锚点框【15】。该网络为每一个边界框预测四个坐标$t_{x}$,$t_{y}$,$t_{w}$,$t_{h}$。如果cell偏离图像的左上角$(c_{x},c_{y})$并且边界框的先验宽和高是$p_{w}$,$p_{h}$,那么预测如下:
$b_{x}=sigma(t_{x})+c_{x}$
$b_{y}=sigma(t_{y})+c_{y}$
$b_{w}=p_{w}e^{t_{w}}$
$b_{h}=p_{h}e^{t_{h}}$
训练时我们用平方差之和(SSE)作为损失函数。如果对于坐标预测的真值是$hat{t_{*}}$(从真值框计算得到),我们的梯度是真值减去预测值:$hat{t_{*}}-t_{*}$。这个真值可以很容易通过反推上面的公式得到。
YOLOv3用逻辑回归为每一个边界框预测一个objectness score。如果一个先验边界框覆盖真值目标超过先验边界框这应该是1。如果先验真值框不是最好的但是确实覆盖一个真值目标超过某些阈值我们仍然忽视,像[17]一样。我们用0.5作为阈值。不像[17]我们的系统仅为每一个真值目标赋予一个先验边界框。如果一个先验真值框没有赋予一个真值目标,它的损失函数仅计算objectness,不计算coordinate和class预测。
2.2 类别预测
每一个框用多标签分类预测边界框可能包含的类别。我们没有使用softmax因为我们发现对于一个好的性能是不必要的,替代地我们简单地使用独立的逻辑回归。在训练期间我们使用binary cross-entropy损失函数。
当我们转移到其它像Open Images Dataset【7】的复杂领域,这个方法是有帮助的。在这个数据集中有许多重叠的标签(例如Women和Person)。每一个框只有一个类别,用一个softmax加强了该假设且这是不复合实际情况的。一个多标签的方法更适合对数据建模。
2.3 跨尺度预测
YOLOv3使用3种不同尺度来预测框。我们的系统用一个相似于特征金字塔【8】的概念,从这些尺度来提取特征。在基础特征提取器上我们加了几个卷积层。这些层的最后预测一个3维的向量来编码bounding box,objectness和class预测。在COCO实验中【10】我们每个尺度预测3个框,因此张量是NxNx[3*(4+1+80)],包括4个bounding box偏移量,1个objectness预测和80个class预测。
接下来我们取两层前的特征并且用2x来上采样。我们也取网络更前面的层和上采样的特征用concatenation来融合。这个方法让我们从上采样特征得到更有意义的语义信息以及从更前面的特征图中获得细粒度信息。然后我们添加几个卷积层来处理这个结合的特征图,并且最终预测一个相似的张量,尽管现在是两倍的尺寸。
我们再次执行相同的设计来预测最终尺度的方框。因此我们对第3种尺度的预测得益于所有先前所有的计算和从前面网络中的细粒度特征。
我们仍然用k-means聚类来决定边界框先验。我们就随意地选择了9个聚类中心和3个尺度的排序,然后跨尺度地均匀分割它们。在COCO数据集上9个聚类中心是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
2.4 特征提取
我们用一个新的网络来进行特征提取。我们的新网络是用于YOLOv2,Darknet-19的网络和新的残差网络的一个混合方法。我们的网路连续地使用3x3和1x1的卷积但是也使用了一些shortcut connections,并且它是意义重大的。它有53个卷积层,因此我们称它Darknet-53!
这个新网络比Darknet-19更强大并且仍然比RestNet-101和ResNet-152更高效。这里是一些ImageNet的结果:
每一个网络都用相同的设置进行训练,并以256x256和single crop accuracy进行测试。运行时间在Titan X上用256x256进行衡量。因此Darknet-53可以与最先进的算法相媲美但是拥有更少的浮点运算和更快的速度。Darknet-53比ResNet-101更好并且快1.5倍。Darknet-53与ResNet-152有相似的性能并且快了2倍。
Darknet-53也实现了每秒最高的衡量浮点运算。这意味着网络结构更好地利用了GPU,使它更高效地评估因此更快速。这里主要是因为ResNet层太多并且效率不高。
2.5 训练
我们仍然训练没有硬性负面挖掘的全部图像。我们用多尺度训练,大量数据增强,批量归一化,所有的标准方法。我们用Darknet神经网络框架进行训练和测试【14】。
3 我们怎么做
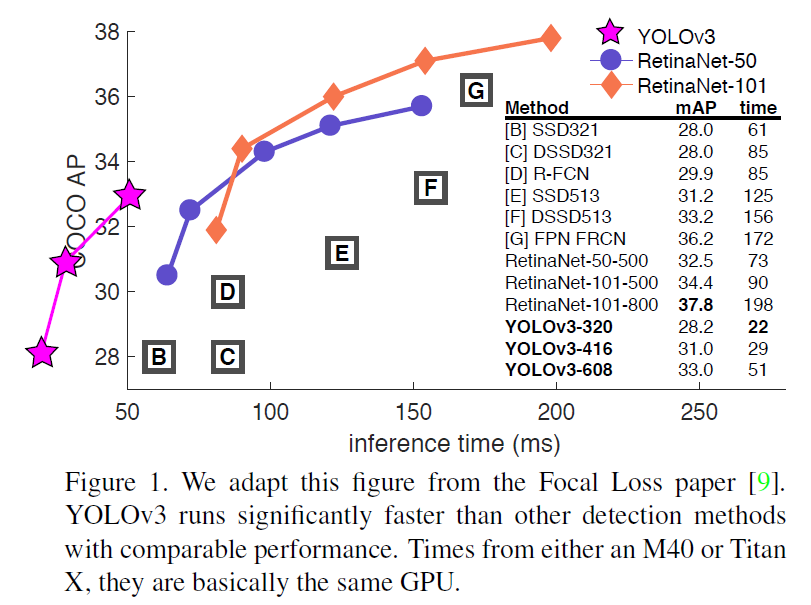
YOLOv3非常好!看table3。就COCOs而言,奇怪的平均mAP指标和SSD变体相当但是快了3倍。在这个指标上它仍然有一点落后其它的模型如RetinaNet。
然而,当我们在IOU=0.5处看mAP旧的检测度量时(或表中的$AP_{50}$),YOLOv3是相当健壮的。它几乎可以和RetinaNet相媲美并且远胜于SSD的变体。这表明YOLOv3是一款非常强大的检测器,且擅长为目标产生像样的框。然而,随着IOU阈值增加性能显著降低表明YOLOv3努力地获得能对齐目标的框。
以前的YOLO难以检测小目标。然而,现在我们看到了这种趋势的逆转。随着新的多尺度预测我们看到YOLOv3具有较高的$AP_{s}$性能。然而,它在中等和更大的尺寸目标上性能相对较差。需要更多的研究来了解这点。
当我们在$AP_{50}$指标上画出accuracy vs speed的曲线时,我们看到YOLOv3与其它系统相比有明显的优势。也就是说,更快更好。
4 我们尝试但是没有起作用的工作
我们在研究YOLOv3时尝试了很多工作。许多都没有用。这里是我们可以记起的一些。
Anchor box x,y偏移量预测。