MySQL(DQL)
基础查询
SELECT
字段列表(字段1,字段2,字段3)
FROM
表明列表(表1,表2,表3)
WHERE
条件列表
GROUP BY
分组列表
HAVING
分组之后的条件
ORDER BY
排序
LIMIT
分页限定
一、条件查询
运算符
-
常用于
WHERE子句后面的条件 -
< , > ,<=,>=,=,<> -
BETWEEN...AND... -
IN(集合) -
LIKE- 占位符
_:单个任意字符%:多个任意字符
- 占位符
-
IS NULL -
AND 或 && -
OR 或 || -
NOT 或 !
二、排序查询
- 语法:
ORDER BY字段 排序方式ORDER BY排序字段1 排序方式1,排序字段2 排序方式2- 排序方式:
ASC:升序,默认的DESC:降序
- 注意:如果有多个排序条件,则当前边的条件一样时,才会判断第二个条件
三、分组查询
- 语法:
GROUP BY分组字段 - 注意
- 分组之后查询的字段最好只包括分组字段、聚合函数
WHERE和HAVING的区别WHERE在分组之前限定,如果不满足条件,则不参与分组及查询;HAVING在分组之后限定,如果不满足条件,则不查询WHERE子句不能跟聚合函数,HAVING可以进行聚合函数的判断,DISTINCT:在表中,可能会包含重复值,该关键词用于返回唯一不同的值。
- 聚合函数(常用于
GROUP BY从句的SELECT查询中)COUNT- 一般选择非空的列:主键
COUNT(*)总记录数
MAX、MIN、SUM、AVG- 注意:聚合函数的计算排除NULL值
- 可选择不包含非空的列进行计算
- 可使用
IFNULL(字段, NULL时默认的值)函数
- 分组之后查询的字段最好只包括分组字段、聚合函数
四、分页查询
-
语法:
LIMIT开始的索引,每页查询的条数 -
公式:开始的索引 = (当前页码 - 1) * 每页显示的条数
-
每页显示3条记录
-
SELECT * FROM table_name LIMIT 0, 3 -- 第一页 SELECT * FROM table_name LIMIT 3, 3 -- 第二页 SELECT * FROM table_name LIMIT 6, 3 -- 第三页
-
-
五、多表查询
-
笛卡尔积
- 有两个集合A、B,取这两个集合组成的所有情况(A*B)
- 要完成多表查询,需要消除无用的数据查询
-
多表查询
-
目的:消除无用的数据查询
-
分类:
-
内连接查询(查询交集部分)
-
隐式内连接:使用
WHEWE消除无用数据-
SELECT t1.*, t2.department FROM t_user t1, -- 从表 t_department t2 -- 主表 WHERE t1.dpt_id = t2.id; -- t1.dpt_id为从表的外键,t2.id为主表的主键
-
-
显式内连接
-
SELECT t1.*, t2.department FROM t_user t1 INNER JOIN t_department t2 ON t1.dpt_id = t2.id
-
-
-
外连接查询(查询交集部分及LEFT左表/RIGHT右表NULL部分)
-
左连接:
LEFT JOIN查询左表t1所有内容以及t1和t2的交集内容-
SELECT t1.*, t2.department FROM t_user t1 LEFT JOIN t_department t2 ON t1.dpt_id = t2.id
-
-
右连接:将上面的
LEFT JOIN改为RIGHT JOIN,查询右表t2所有内容以及t1和t2的交集内容
-
-
子查询
-
概念:查询中嵌套查询,将嵌套的查询结果作为条件或虚拟表。
-
子查询结果是单行单列:可作为条件,使用<、>、=等运算符判断
-
SELECT * FROM t_uesr WHERE t_uesr.money > ( SELECT AVG( USER.money ) FROM t_uesr );
-
-
子查询结果是单行多列:可作为条件,使用IN运算符判断
-
SELECT * FROM t_uesr WHERE t_uesr.dpt_id IN (SELECT t_department.id FROM t_department WHERE t_department.department IN ( '技术部', '销售部' ));
-
-
子查询结果是多行多列:可作为一张虚表参与查询
-
SELECT * FROM t_uesr t1, ( SELECT * FROM t_department WHERE department.id <= 2 ) t2 WHERE t1.dpt_id = t2.id;
-
-
-
-
约束
-
概念:对表中的数据进行限定,保证数据的正确性、有效性、完整性
-
分类:
- 主键约束:
primary key - 非空约束:
not null - 唯一约束:
unique - 外键约束:
foreign key
- 主键约束:
-
唯一约束
-
注意:唯一约束可以有null值,但是只能有一条记录为null
-
在创建表时,添加唯一约束
-
CREATE TABLE test ( id INT, phone VARCHAR ( 11 ) UNIQUE );
-
-
删除唯一约束
-
ALTER TABLE test DROP INDEX phone;
-
-
创建表后,添加唯一约束
-
ALTER TABLE test MODIFY phone VARCHAR(11) UNIQUE;
-
-
-
主键约束
-
注意:
- 含义:非空且唯一
- 一张表只能有一个字段为主键
- 主键即表中记录的唯一标识
-
建表时,添加主键
-
CREATE TABLE test ( id INT PRIMARY KEY AUTO_INCREMENT, phone VARCHAR ( 11 );
-
-
删除主键
-
ALTER TABLE test DROP PRIMARY KEY;
-
-
建表后,添加主键
-
ALTER TABLE test MODIFY id INT PRIMARY KEY AUTO_INCREMENT;
-
-
-
外键约束
-
注意:
-
建表时,添加外键
-
CREATE TABLE 表名(... 外键列, constraint 外键名称 foreign key (外键列名称)references 主表名称(主表列名称));
-
-
删除外键
-
ALTER TABLE 表名 DROP foreign key 外键列名称;
-
-
建表后添加外键
-
ALTER TABLE 表名 ADD constraint 外键名称 foreign key (外键列名称)references 主表名称(主表列名称);
-
-
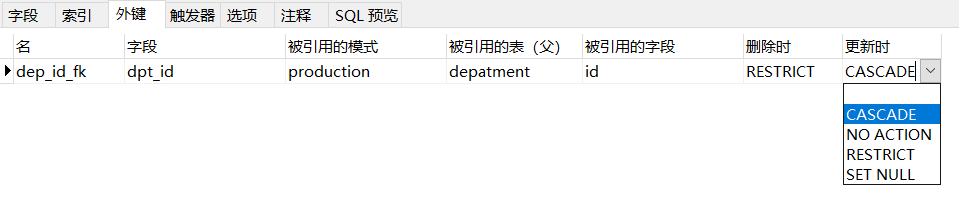
-
级联操作
-
主表的更新引起子表的更新
-
语法
-
ALTER TABLE 表名 ADDconstraint 外键名称 foreign key (外键列名称)references 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE
-
-
分类
- 级联更新:
ON UPDATE CASCADE - 级联删除(危险):
ON DELETE CASCADE
- 级联更新:
-
-
数据库设计
多表之间的关系
-
分类
- 一对一:人和身份证
- 一对多(多对一):部门和员工
- 多对多:学生和课程,一个学生可以选择多门课程,一门课程可被多个学生选择
-
实现关系:
-
一对一:
- 可以在任意一方添加唯一外键指向另一方的主键,一般来说,一对一直接放在一张表处理就可以了
-
一对多(多对一):
- 如果部门和员工
- 实现方式:在多的一方创建外键,指向一的一方的主键
-
多对多:
-
学生和课程
多对多关系的实现需要借助第三张表,该表至少包含两个字段,这两个字段最为第三张表的外键,分别指向两张表的主键
-
-
-
数据库设计的范式
- 概念:设计数据库时,遵循的一些规范。目前关系型数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF),越高的范式数据库冗余越小
- 第一范式:每一列都是不可分割的原子数据项
- 第二范式:在第一范式的基础上,消除非主属性对主码的部分函数依赖
- 第三范式:在第二范式的基础上,消除传递依赖
- 依赖的概念
- 函数依赖:通过A属性/属性组的值,可以确定唯一B的属性值,则称B依赖于A
- 完全函数依赖:如果A是一个属性组,则B属性值的确定需要完全依赖A属性组中所有的值
- 部分函数依赖:果A是一个属性组,则B属性值的确定只需要完全依赖A属性组中某些的值
- 传递函数依赖:B依赖于A,C依赖于B,则称C传递函数依赖于A
- 码:在一张表中,一个属性/属性组,被其他所有属性完全依赖,则称这个属性/属性组为码
- 主属性:码属性组中所有的属性
- 非主属性:除去码属性组的中属性的所有属性