首先介绍一下 libSVM的数据格式
Label 1:value 2:value ….
Label:是类别的标识,比如上节train.model中提到的1 -1,你可以自己随意定,比如-10,0,15。当然,如果是回归,这是目标值,就要实事求是了。
Value:就是要训练的数据,从分类的角度来说就是特征值,数据之间用空格隔开
比如: -15 1:0.708 2:1056 3:-0.3333
需要注意的是,如果特征值为0,特征冒号前面的(姑且称做序号)可以不连续。如:
-15 1:0.708 3:-0.3333
表明第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度。我们平时在matlab中产生的数据都是没有序号的常规矩阵,所以为了方便最好编一个程序进行转化。
怎样生成libsvm所用的数据格式
第一种方法 使用FormatDataLibsvm.xls
运行FormatDataLibsvm.xls(注意这时会有一个关于“宏已禁宏”的安全警示,点击“选项”,选择“启用此内容”,确定即可);
1,先运行FormatDataLibsvm.xls然后将数据粘贴到sheet1的topleft单元。
2、 打开data.xls,(注:网上很多的介绍都是直接将数据粘贴到sheet1的topleft单元),要特别注意的是这时候的数据排列顺序应该是:
条件属性a 条件属性b ... 决策属性
7 5 ... 2
4 2 ... 1
3、"工具"-->"宏"-->执行下面有一个选项(FormatDatatoLibsvm)-->执行,要选中这个然后点击“运行” ,这时候数据讲变成:
决策属性 条件属性a 条件属性b ...
2 1:7 2:5 ...
1 1:4 2:2 ...
等数据转换完成后,将该文件保存为.txt文件。这时数据转换的问题就解决了。
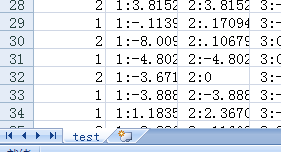
用excel打开 一定要删掉sheet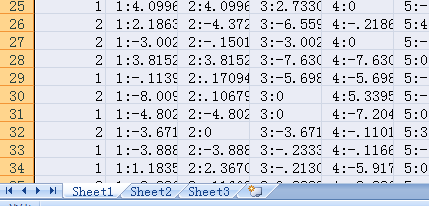
如下图所示
第二种方法
可以利用weka来转换,用weka打开csv文件,再将文件重新保存为libsvm格式。方便简单,经我测试的结果也是一致的。这个方法很好,多列属性也可行。
如果出现错误,请将sheet删掉
第三种种方法
.txt格式->svm格式的转换(该段转自http://blog.csdn.net/lztao82/article/details/7495258)
首先说明的是,这里所提的.txt文本数据是指数据文件带有逗号、空格、顿号、分号等数据分离符号的数据文件。因为其用符号来分离,导致所有数据项都归类为一个属性,无法实现上面2步骤的格式输入,也就无法实现正确结果格式的输出了。
为了解决该问题,转换该过程与上面一过程的最大不同就在于:在打开该.txt文件的时候根据文本数据本身的数据特点将其所包含的逗号、分号、制表符等数据分离的符号去掉;具体的做法是:转换运行FormatDataLibsvm.xls,“文件”->“打开”->选择要打开的data,txt文件,接着在文本导入向导中根据data.txt文件本身的数据特点选择“原始数据类型(分隔符号)”;接着选择分隔符号的类型(目地是使得该数据分成独立的一列列数据,分离成功的话,在数据预览中将可以看到一列列分离独立的数据) :选择“列数据格式”(常规)->完成;
这时候只要调整上面"一"过程的数据格式,重复其后面的步骤2、3操作即可。
第三种方法
其实libsvm所需的数据也可以自己生成~比如我之前是利用图像的颜色特征进行图像分割,先用程序读取RGB值然后保存在txt文件中就可以了~只不过要注意保存的格式
如何使用这些数据
以简单的使用为例
在用libsvm自带的一个例子heart_scale.mat时,一切正常~
load heart_scale.mat(此处无分号)
train = heart_scale_inst;
train_label=heart_scale_label;
test=train;
test_label=train_label;
model=svmtrain(train_label,train,'-c 2 -g 0.01');
[predict_label,accuracy]=svmpredict(test_label,test,model);
但是在我们用自己的例子时出现了问题~
因为train = heart_scale_inst;是用的mat文件的特征列
train_label=heart_scale_label;用的是mat文件的标签列
而我们生成的txt或者mat文件还没有进行赋值所以一开始进行赋值就可以了~
A=[newmat(1:2288,1:3)];%特征列
B=[newmat(1:2288,4)];%标签列
train = A;
train_label=B;