2017-2018-1 20155310 《信息安全系统设计基础》第十四周学习总结
教材学习内容总结
第十一章 网络编程
11.1 客户端 - 服务器编程模型
每个网络应用程序都是基于客户端 - 服务器模型的
•采用这种模型,一个应用是由一个服务器进程
和一个或多个客户端进程组成。
•服务器管理某种资源,并且通过操作这种资源为它的客户端提供某种服务。 •WEB服务器,代表客户端检索,执行磁盘内容。
•FTP服务器,为客户端进行存储和检索。
•电子邮件服务器,为客户端进行读和更新。
•客户端-服务器模型中的基本操作是事务(transaction).
•一个客户端-服务器事务由四步组成
•客户端需要服务的时候,向服务器发送请求,发送一个事务。
•服务器收到请求后,解释它,并以适当方式操作它的资源。
•服务器给客户端发送一个响应,并等待下一个请求。
•客户端收到响应并处理它。
11.2 网络
客户端和服务端通常运行在不同的主机上,并且通过计算机网络的硬件和软件资源来通信。
•对于一个主机而言,网络只是又一种I/O设备,作为数据源和数据接收方。
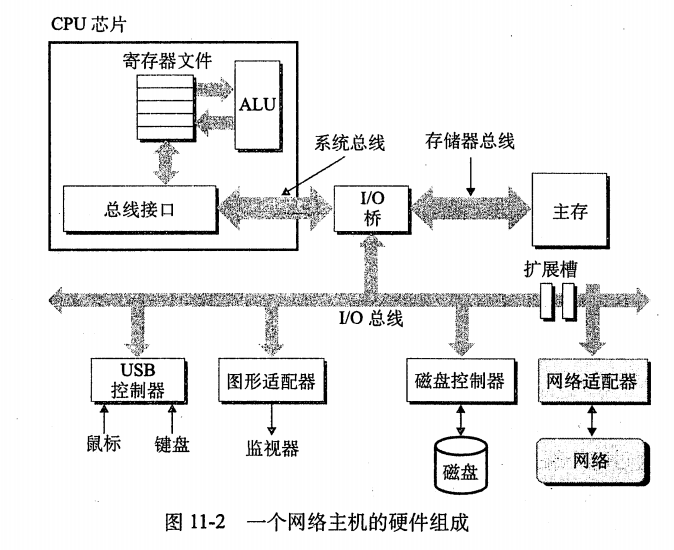
•对于物理上而言,网络是一个按照地理远近组成的层次系统。
•最低层是LAN(Local Area Network,局域网):在一个建筑或校园范围内。
•迄今为止,最流行的LAN技术是以太网(Ethernet).
•由Xerox PARC公司在20世纪70年代中期提出。
•以太网被证明是适应力极强的,从3 MB/s到10 GB/s。
•一个以太网段(Ethernet segment) •
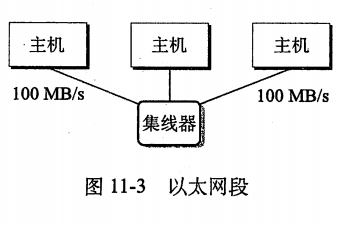
•包括一些电缆(通常是双绞线)和一个叫做集线器的小盒子。
•每根电缆都有相同的最大位带宽 •典型的是100MB/s或者1GB/S.
•一端连接在主机的适配器,一端连接到集线器的一个端口。
•集线器不加分辨地将从一个端口收到的每个位复制到其他所有端口上。
•因此每台主机都能看到每个位。
•以太网段通常跨越一些小的区域。
•例如某建筑物的一个房间或一个楼层。
扩展介绍以太网
每个以太网适配器(网卡)都有一个全球唯一的48位地址,它存储在这个适配器的ROM上(MAC)。
•一台主机可以发送一段位,称为帧(frame),到这个网段内其他任何主机。 •每个帧包括 •一些固定数量的头部(header)位•用于表示此帧的源,和目的地址以及此帧的长度。
•此后就是数据位的有效载荷。
•每个主机适配器都能看到这个帧,但是只有目的主机实际读取它。
使用一些电缆和叫做网桥(bridge)的小盒子,多个以太网段可以连接称较大的局域网,称为桥接以太网(bridged Ethernet)。
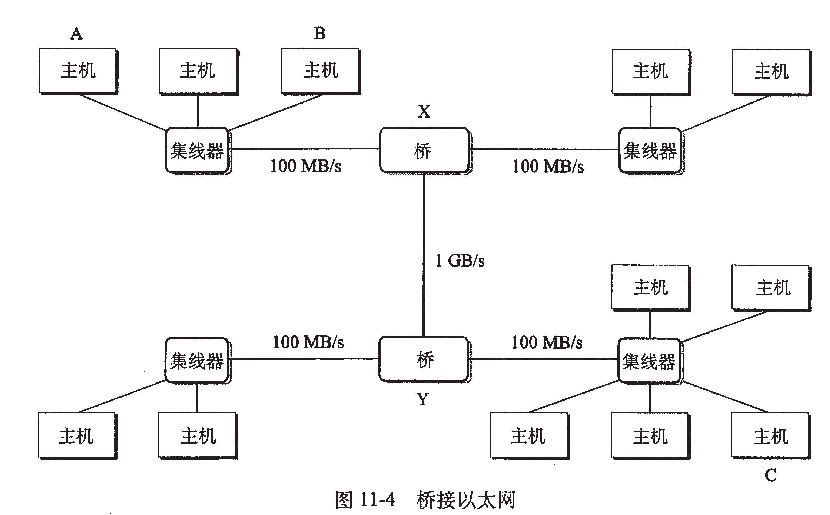
•一些电缆连接网桥与网桥,或者 网桥与集线器。
•这些电缆的带宽可以是不同的。

在层次的更高级别,多个不兼容的局域网可以通过叫做路由器(router)的特殊计算机连接起来,组成一个internet(互联网络)
Internet和internet
我们总是用小写字母的internet表示一般概念,大写的Internet表示一种具体实现,如全球IP因特网。
•WAN(Wide-Area Network,广域网)
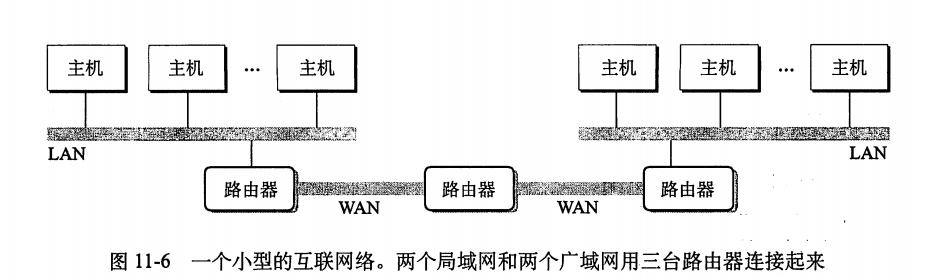
互联网至关重要的特性是:
•它能由采用完全不同和不兼容技术的各种局域网和广域网组成。
Q:如何能够让某台源主机跨过所有这些不兼容的网络发送数据位到另一台目的主机呢?
A:解决办法是一层运行在每台主机和路由器上的协议软件,消除不同网络之间的差异。
•这个软件实现一种协议:控制主机和路由器如何协调工作来实现数据传输。 •必须提供两种基本能力:
•命名机制 •每台主机会被分配至少一个互联网地址(internet address),这个地址唯一标识了这台主机。
•传送机制 •协议通过定义一种把数据位捆扎成不连续的片(称为包)的方式。 •一个包是由包头和有效载荷组成的。 •包头 •包的大小
•源主机和目的主机地址
•有效载荷包括从源主机发出的数据位

一个客户端运行在主机A上,主机A与LAN1相连,它发送了一串数据字节到运行在主机B上的服务器端,主机B则连接在LAN2上。有如下8个步骤。
1.运行在主机A上的客户端进行系统调用,从客户端的虚拟地址空间拷贝到内核缓冲区。
2.主机A上的协议软件通过在数据前附加互联网络包头和LAN1帧头,创建了一个LAN1的帧。 •互联网包头寻址到互联网主机B。(最终目的)
•LAN1帧头寻址到路由器。(中转站)
•封装 •LAN1帧的有效载荷是互联网络包。
•互联网络包的有效载荷是实际的用户数据。
•这种封装是基本的网络互联方法之一。
3.LAN1适配器拷贝该帧到网络上。
4.帧到达路由器,路由器的LAN1适配器从电缆上读取它,并传送到协议软件中。
5.路由器从互联网包头中提取处目的互联网络地址,用它作为路由器的索引,确定向哪里转发这个包。 •路由器剥落旧的LAN1的帧头,加上寻址到主机B的新的LAN2帧头,并把得到的帧传送到适配器。
6.路由器的LAN2适配器拷贝该帧到网络
7.帧到达主机B时,它的适配器从电缆上读到此帧,并将它传送到协议软件。
8.最后,主机B上的协议软件剥落包头和帧头。服务器进行一个读取这些数据的系统调用。
当然,在这里,我们掩盖了许多非常艰难的问题。
•如果不同的网络有不同帧大小的最大值,该怎么办。
•路由器如何知道往哪里转发帧。
•网络拓扑变化的时候,如何通知路由器。
•包丢失了,会如何?
虽然如此,我们也能大概了解到互联网络思想的精髓。
11.3 全球IP 因特网
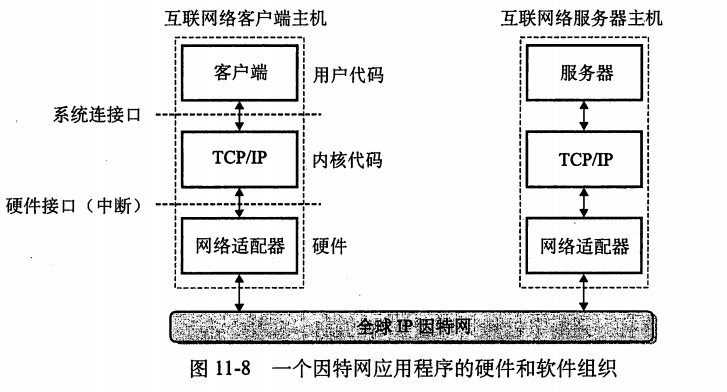
每台因特网主机都运行实现TCP/IP协议 (Transmission Control Protocol/Intelnet Protocol,传输控制协议/互联网络协议)的软件,几乎所有计算机系统都支持这个协议。
•因特网的客户端和服务端混合使用套接字接口函数和Unix I/O函数来进行通信。
•套接字函数典型地是作为会陷入内核的系统调用来实现的,并调用各种内核模式的TCP/IP函数。
TCP/IP协议实际上一个协议族,每一个协议提供不同的功能。
•例 •IP协议提供基本的命名方法,和传递机制。 •这种传递机制能够从一台因特网主机往其他主机发送包,也叫做数据报(datagram)
•IP机制从某种意义上是不可靠的,如果数据报在网络丢失或重复,并不会试图恢复。 •UDP(Unreliable Datagram Protocol,不可靠数据报协议)稍微扩展了IP协议。 •这样,包可以在进程间,而不是主机间传送。
•TCP是一个构建在IP之上的复杂协议,提供了进程间可靠地全双工(双向)的连接。
为了简化讨论
•我们将TCP/IP看作是一个单独的整体协议。
•不讨论它的内部工作,只讨论TCP和IP为应用程序提供的基本功能。
•不讨论UDP
从程序员的角度,我们可以把因特网看作世界范围内主机的集合,满足一下特性。
•主机集合被映射为一组32位的IP地址。
•这组IP地址可以被映射为一组称为因特网域名(Internet domain name)的标示符。
•因特网主机上的进程能够通过连接和任何其他主机上的进程通信。
11.3.1 IP地址
一个IP地址就是一个32位无符号整数。网络程序将IP地址存放在一个IP地址结构中。
/* Internet address structure */
struct in_addr{
unsigned int s_addr;
}
为什么要用结构来存放标量IP地址
是早期的不幸产物,但是现在更改太迟了。
主机字节序,和网络字节序
因为因特网主机可以有不同的主机字节顺序
TCP/IP为任意整数数据项定义了统一的网络字节顺序(network byte order)(大端,x86是小端)。
Unix提供下面这样的函数实现转换。

IP地址通常是以一种称为点分十进制表示法来表示的
•这里,每个字节(8位)都是由它的十进制表示(0~255),并且用句点和其他字节间分开。
•在Linux系统上,你能够使用hostname命令来确定你自己主机的点分十进制:
linux> hostname -i
10.174.204.145
•可以使用inet_aton和inet_ntoa函数来实现两者之间互相转换。

11.3.2 因特网域名
方便人们记忆的对于IP的映射就是域名。
域名集合形成了一个层次结构,每个域名编码了它在层次中的位置。
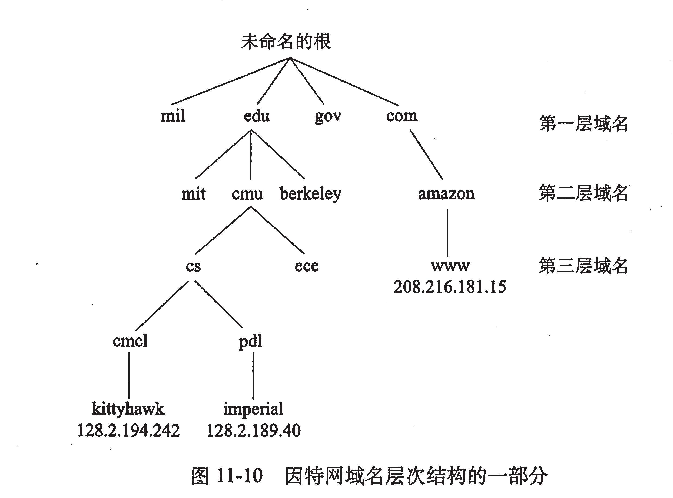
•叶子结点反向到根的路径就是域名。
•层次结构第一层 : 未命名的根结点
•层次结构第二层 : 一级域名(first-level domain name)
•由非盈利组织ICANN(Internet Corporation for Assigned Names and Numbers,因特尔分配名字数字协会)定义。
•常见的一级域名:com,edu,gov,org和net。
•层次结构第三层: 二级域名(second-level) •例如:cmu.edu。
•这些域名是由ICANN的各个授权代理按照先到先服务的基础分配的。
•一旦一个组织得到一个二级域名,那么它就可以在这个子域中创建任何新的域名了。
因特网定义了域名集合和IP地址直接的映射。
•HOSTS.TXT •直到1988年,这个映射都是通过一个叫做HOSTS.TXT的文本文件来手工维护的。
•DNS: •之后,通过分布世界范围内的数据库(DNS,Domain Name System,域名系统),来维护的。
•DNS数据库由上百万的主机条目结构(host entry structure)组成的。
•定义了一组域名(一个官方名字和一个别名)和一组IP地址之间的映射。

因特网应用程序通过调用 gethostbyname和gethostbyaddr函数,从DNS数据库中检索任意的主机条目。

每台主机都有本地定义的域名localhost
•这个域名总是映射本地送回地址(loopback address) :127.0.0.1。
•localhost名字为引用运行在同一机器上的客户端和服务端提供了一种便利和可移植的方式。

11.3.3 因特网连接
Internet服务端和客户端通过在连接上发送和接收字节流来通信。
•从连接一对进程的意义上而言,连接是点对点的。
•从数据可以同时双向流动的角度来说,它是全双工的。
•并且从由源进程发出的字节流最终被目的进程按照发送的数据接收来说,它是可靠的
一个套接字是连接的一个端点。
•每个套接字都有相应的套接字地址。 •是由一个IP地址和一个16位的整数端口组成的,用地址:端口来表示。
•当客户端发起一个连接请求时,客户端套接字地址中的端口由内核自动分配的。 •称为临时端口
•然后,服务器套接字地址中的端口通常是某个知名的端口,和这个服务相对应的。 •例如: •Web服务器通常使用端口80
•电子邮件服务器使用端口25
•在Unix机器上,文件/etc/services 包含一张这台机器提供的服务和他们的知名端口号的综合列表。
一个连接是由它两端的套接字地址唯一确定的。
•这对套接字地址叫做套接字对(socket pair),由下列元组来表示: •(cliaddr:cliport,servaddr:servport)

11.4 套接字接口
套接字接口(socket interface)是一组函数,他们和Unix I/O函数结合起来,用以创建网络应用。
给出一个典型的客户端-服务器事务的上下文中套接字接口概述,以此导向。


11.4.1 套接字地址结构
不同的角度:
•从Unix内核角度来看,一个套接字就是通信的一个端点。
•从Unix程序来看,套接字就是一个有相应描述符的打开文件。

Internet的套接字地址(Internet-sytle)存放在上图所示的类型为sockaddr_in的16字节结构中。
•sin_family成员是AF_INET,ipv4还是ipv6。
•sin_port成员是一个16位的端口号。
•sin_addr成员就是一个32位的IP地址。
•IP地址和端口号总是以网络字节顺序(大端法)存放的。
•sin_zero 是填充,使得sockaddr_in和sockaddr一样大。
sockaddr_in给程序员操作的,sockaddr交由套接字函数使用的,两者可以直接强制转换。

11.4.2 socket函数
客户端和服务端使用socket函数来创建一个套接字描述符(socket descriptor)
跟open差不多
#include<sys/types.h>
#include<sys/socket.h>
int socket(int domain, int type ,int protocol);
返回:若成功则为非负描述符,出错为-1
我们总是带这样的参数调用socket函数:
clientfd = Socket(AF_INET,SOCK_STREAM,0);
•AF_INET表面我们在使用IPV4协议。
•SOCK_STREAM表示这个套接字是Internet连接的一个端点。
•socket返回的clientfd描述符,仅仅是部分打开,还不能用于读写。
•如何完成打开套接字的工作,取决于我们是客户端还是服务器。
•下一节描述我们是客户端时如何打开套接字。
11.4.3 connect函数
客户端通过调用connect函数来建立和服务器的连接
#include<sys/socket.h>
int connect(int sockfd,struct sockaddr *serv_addr,int addrlen);
返回:若成功则为0,若出错则为-1
connect函数试图于套接字地址为serv_addr的服务器建立一个因特网连接.
•其中addrlen是sizeof(sockaddr_in).
•connect函数会阻塞,一直到连接成功建立或是发生错误。
•如果成功,sockfd描述符就可以读写了。
•并且得到链接是由套接字对(x:y,serv_addr.sin_addr,serv_addr.sin_port)刻画的。 •其中x是客户端IP地址,而y表示临时端口。
•它唯一地确立了客户端主机上的客户端进程。
11.4.4 open_clientfd函数
open_cilentfd是socket和connect的包装函数(不是系统自带)
#include <csapp.h>
int open_clientfd(char *hostname, int port);
返回:若成功则为描述符,若`Unix`出错则为-1,DNS出错则为-2.
open_clientfd函数和运行在hostname上的服务器建立一个连接,并在知名端口port上监听连接请求。
•它返回一个打开的套接字描述符。
•该描述符准备好了,可以用Unix I/O函数做输入和输出。

11.4.5 bind函数
剩下的套接字函数bind,listen和accept被服务器用来和客户端建立链接。
#include<sys/socket.h>
int bind(int sockfd,struct sockaddr *my_addr,int addrlen);
//返回: 若成功则为0,若出错则为-1
bind函数告诉内核将my_addr中的服务器套接字地址和套接字描述符sockfd联系起来。
•参数addrlen就是sizeof(sockaddr_in)
?
11.4.6 listen函数(主动套接字->监听套接字)
客户端是发起连接请求的主动实体。服务器是等待来自客户端连接请求的被动实体。
•默认情况下,内核会认为socket函数创建的描述符对应于主动套接字(active socket). •它存在于一个连接的客户端。
•服务器调用listen告诉内核,描述符是被服务器而不是客户端使用的
#include<sys/socket.h>
int listen(int sockfd,int backlog);
返回:若成功则为0,若出错则为-1
listen函数将sockfd从一个主动套接字转化为一个监听套接字(listenning socket)。
•该套接字可以接收来自客户端的连接请求。
•backlog参数暗示了内核在开始拒绝连接请求之前,应该放入队列中等待的未完成连接请求的数量。
•backlog参数的确切含义要求对TCP/IP协议的理解,这超出了我们的讨论的范围。
•通常我们会把它设置成一个较大的值,比如1024。
11.4.7 open_listenfd函数
用socket,bind和listen函数结合称open_listenfd的包装函数。
服务器可以用它来创建一个监听描述符。
#include<csapp.h>
int open_listenfd(int port)
返回:若成功则为描述符,若Unix出错则为-1
open_listenfd函数打开和返回一个监听描述符
•这个描述符准备好在知名端口port上接收请求。

•创建listenfd套接字描述符。
•使用setsockopt函数来配置服务器,使得它能被立即中止和重启。
•默认地,一个重启的服务器将在大约30秒内拒绝客户端的连接请求,严重阻碍调试。
•接下来,初始化服务器的套接字地址结构。
•用INADDR_ANY来告诉内核这个服务器将接收任何IP地址到端口port的请求。 •INADDR_ANY通配符地址就是指定地址为0.0.0.0的地址
•调用blind,listen。将其转换为监听套接字。
11.4.8 accept函数

•用于从已完成连接队列队头返回下一个已完成连接。 •如果已完成连接为空,那么进程进入阻塞(假定套接字为默认的阻塞方式)
•返回三个值 •已连接标示符
•客户端地址
•客户度地址长度
监听描述符和已连接描述符之间的区别是很多人迷惑。
•监听描述符是作为客户端连接请求的一个端点。
•它被创建一次,并存在于服务器的整个生命周期。
•已连接描述符是客户端和服务器之间已经建立起来的连接的一个端点。
•服务器每次接收连接请求时都会创建一次。
•它只存在于服务器为一个客户端服务的过程中。
11.5 WEB服务器
Web服务器
Web服务器使用HTTP协议(Hypertext Transfer Protocol,超文本传输协议)和它们的客户端(浏览器等)彼此通信。 一个 Web 客户端(即浏览器) 打开一个到服务器的因特网连接,并且发出请求内容(浏览器向服务器请求静态或者动态的内容)后服务器响应所请求的内容,然后关闭连接。浏览器读取这些内容,并把它显示在屏幕上。对静态内容的请求是通过从服务器磁盘取得文件并把它返回给客户端来服务的;对动态内容的请求是通过在服务器上一个子进程的上下文中运行一个程序并将它的输出返回给客户端来服务的。
CGI标准提供了一组规则,来管理客户端如何将程序参数传递给服务器。服务器如何将这些参数以及其他信息传递给子进程,以及子进程如何将它的输出发送回客户端。
Web内容可以用一种叫做 HTML(Hypertext Markup Language,超文本标记语言)的语言来编写。一个 HTML 程序(页)包含指令(标记),它们告诉浏览器如何显示这页中的各种文本和图形对象。
课下作业:
11.6
A.Web内容可以用一种叫做 HTML(Hypertext Markup Language,超文本标记语言)的语言来编写。一个 HTML 程序(页)包含指令(标记),它们告诉浏览器如何显示这页中的各种文本和图形对象。
B. 用火狐浏览器输出结果:
另外,如果要存成文件的话,可能需要另存为?
C. A的结果可以表明,浏览器使用HTTP/1.1
D. 请求行和报头如下:
GET /clockwise.gif HTTP/1.1
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:20.0) Gecko/20100101 Firefox/20.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
User-Agent: 系统以及浏览器情况
Accept:可以接受的媒体;
Accept-Encoding:可以接受的编码方案;
Accept-Language:能够接受的语言;
11.7
在get_filetype函数里面添加:
else if(strstr(filename, ".mpg") || strstr(filename, ".mp4"))
strcpy(filetype, "video/mpg");
11.8
并没有想到很好的方法。
因为结束子进程之前,我们不可以关闭已连接描述符。这就导致我们还是得让serve_dynamic或者是doit函数或者main函数中要等待子进程结束。迭代服务器的设计让这个问题变得比较无聊。
在main函数之前加入代码:
int chdEnded ;
#include <signal.h>
void child_signal(int sig)
{
pid_t pid;
while((pid = waitpid(-1, NULL, WNOHANG)) > 0)
;
chdEnded = 1;
}
在main函数中添加语句 signal(SIGCHILD, child_handle);
每次accept之前,让chdEnded = 0;
并且在doit()中的serve_dynamic之后添加:
while(!chdEnded) pause();//or do sth
删掉serve_dynamic里的wait(NULL);
11.9
serve_static中的存储器映射语句改为:
srcfd = open(filename, O_RDONLY, 0);
srcp = (char*)malloc(sizeof(char)*filesize);
rio_readn(srcfd, srcp, filesize);
close(srcfd);
rio_writen(fd, srcp, filesize);
free(srcp);
11.10
HTML文件:
<html>
<body>
<form name="input" action="cgi-bin/adder" method="get">
Num1: <input type="text" name="num1"/> <br/>
Num2: <input type="text" name="num2"/> <br/>
<input type="submit" value="Submit"/>
</form>
</body>
</html>
因为提交的表单里面有参数名字(num1=x&num2=y),所以要修改相应的adder.c:
int parseNum(char *s)
{
int i = strlen(s) - 1;
while(i>0 && s[i-1]>='0'&&s[i-1]<='9' )
i--;
return atoi(s+i);
}
int main(void) {
char *buf, *p;
char arg1[MAXLINE], arg2[MAXLINE], content[MAXLINE];
int n1=0, n2=0;
/* Extract the two arguments */
if ((buf = getenv("QUERY_STRING")) != NULL) {
p = strchr(buf, '&');
*p = 0;
strcpy(arg1, buf);
strcpy(arg2, p+1);
n1 = parseNum(arg1);
n2 = parseNum(arg2);
}
/* Make the response body */
sprintf(content, "Welcome to add.com: ");
sprintf(content, "%sTHE Internet addition portal.
<p>", content);
sprintf(content, "%sThe answer is: %d + %d = %d
<p>",
content, n1, n2, n1 + n2);
sprintf(content, "%sThanks for visiting!
", content);
/* Generate the HTTP response */
printf("Content-length: %d
", (int)strlen(content));
printf("Content-type: text/html
");
printf("%s", content);
fflush(stdout);
exit(0);
}
11.11
想到的办法就是定义一个变量rmtd,表示请求的方法。
在client_error,serve_static和serve_dynamic中添加一个参数mtd(改的地方也比较多),表示方法。如果mtd为HEAD,就只打印头部。
11.12
还是使用rmtd表示方法。
这里需要改的还有读取报头。
用POST方法,表单的参数是在报头之后。
报头中有一项是Content-Length,读取出来,在报头读完之后,接着读取Content-Length个字节(注意最后添0),这些字节就是form用post方法提交的数据。
主要修改的就是doit方法和read_request方法。
下面的程序只能针对参数为文本的情况,且参数总长度最大不超过MAXLINE。
#define M_GET 0
#define M_POST 1
#define M_HEAD 2
#define M_NONE (-1)
void doit(int fd)
{
int is_static;
int rmtd = 0;
struct stat sbuf;
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];
char filename[MAXLINE], cgiargs[MAXLINE];
rio_t rio;
/*for post*/
int contentLen;
char post_content[MAXLINE];
/* Read request line and headers */
rio_readinitb(&rio, fd);
rio_readlineb(&rio, buf, MAXLINE);
sscanf(buf, "%s %s %s", method, uri, version);
printf("%s %s %s
", method, uri, version);
if(strcmp(method, "GET") == 0) rmtd = M_GET;
else if(strcmp(method, "POST") == 0) rmtd = M_POST;
else if(strcmp(method, "HEAD") == 0) rmtd = M_HEAD;
else rmtd = M_NONE;
if (rmtd == M_NONE) {
clienterror(fd, method, "501", "Not Implemented",
"Tiny does not implement this method", rmtd);
return;
}
contentLen = read_requesthdrs(&rio, post_content, rmtd);
/* Parse URI from GET request */
is_static = parse_uri(uri, filename, cgiargs);
if (stat(filename, &sbuf) < 0) {
clienterror(fd, filename, "404", "Not found",
"Tiny couldn't find this file", rmtd);
return;
}
if (is_static) {/* Serve static content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode)) {
clienterror(fd, filename, "403", "Forbidden",
"Tiny couldn't read the file", rmtd);
return;
}
serve_static(fd, filename, sbuf.st_size, rmtd);
}
else {/* Serve dynamic content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IXUSR & sbuf.st_mode)) {
clienterror(fd, filename, "403", "Forbidden",
"Tiny couldn't run the CGI program", rmtd);
return;
}
if(rmtd == M_POST) strcpy(cgiargs, post_content);
serve_dynamic(fd, filename, cgiargs, rmtd);
}
}
int read_requesthdrs(rio_t *rp, char* content, int rmtd)
{
char buf[MAXLINE];
int contentLength = 0;
char *begin;
rio_readlineb(rp, buf, MAXLINE);
while(strcmp(buf, "
")) {
rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
if(rmtd == M_POST && strstr(buf, "Content-Length: ")==buf)
contentLength = atoi(buf+strlen("Content-Length: "));
}
if(rmtd == M_POST){
contentLength = rio_readnb(rp, content, contentLength);
content[contentLength] = 0;
printf("POST_CONTENT: %s
", content);
}
return contentLength;
}
11.13
为了测试EPIPE错误,我在read_requesthdrs里面添加了sleep(5)。
于是,在浏览器里请求之后,立即断开。进程出现错误:
GET /add.html HTTP/1.1
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:20.0) Gecko/20100101 Firefox/20.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Segmentation fault
bnuzhanyu@ubuntu:~/CSAPP11$
为了解决这个问题,我用了setjmp和longjmp。
当进程捕捉到SIGPIPE时,进入一个信号处理函数:
jmp_buf buf;
void epipe_signal(int sig)
{
longjmp(buf, 1);
}
而在main函数中,doit部分需要这样改:
rc = setjmp(buf);
if(rc == 0) {
doit(connfd);
close(connfd);
}
这样做虽然能解决这个问题,然而,如果是在子进程中longjmp(也就是adder里sleep(5)时,浏览器关闭了),那么会不会有问题呢?
为了测试,我又在adder中加入了sleep(5)。
并且setjmp后面的语句改为:
if(rc == 0) {
printf("rc=%d pid=%d
", rc, getpid());
doit(connfd);
close(connfd);
}
else printf("rc=%d pid=%d
", rc, getpid());
结果是,当我在adder的sleep期间关闭浏览器,没有输出rc的消息。
后来想起来,输出已经被重定向了,而且是子进程和父进程的输出都被重定向了(没懂为什么都重定向了)。即,当浏览器再次请求时,rc=0也不会输出。
后来在setjmp后添加了dup2(2,1),即将标准输出重定向到标准错误,就可以看见输出了。
奇怪的是,pid都是main的pid。这是不是说明,在子进程中调用longjmp仍然可以回到父进程。那么子进程去哪儿了呢?这个问题还是需要研究一下。
今天测试了一下,子进程的longjmp还是在子进程中。
所以,现在不知道之前那个程序为什么一直输出main的pid,这太奇怪了。
这也就证明我上面的写法是不正确的。
但是,想一想,觉得如果是在子进程中遇到关闭描述符的问题,那么可以直接退出这个进程啊,因为没必要再让这个进程存活下去了。所以,只要简单地判断当前进程是不是子进程,如果是,则exit,如果不是,则longjmp。
先用一个变量mainpid在主函数开始时赋值为getpid();
if(getpid() == mainpid) longjmp(buf,1); else exit(0);