Surprise(Simple Python Recommendation System Engine)是一款推荐系统库,是scikit系列中的一个。简单易用,同时支持多种推荐算法(基础算法、协同过滤、矩阵分解等)。
设计surprise时考虑到以下目的:
- 让用户完美控制他们的实验。为此,特别强调 文档,试图通过指出算法的每个细节尽可能清晰和准确。
- 减轻数据集处理的痛苦。用户可以使用内置数据集(Movielens, Jester)和他们自己的自定义 数据集。
- 提供各种即用型预测算法, 例如基线算法, 邻域方法,基于矩阵因子分解( SVD, PMF, SVD ++,NMF)等等。此外, 内置了各种相似性度量(余弦,MSD,皮尔逊......)。
- 可以轻松实现新的算法思路。
- 提供评估, 分析 和 比较 算法性能的工具。使用强大的CV迭代器(受scikit-learn优秀工具启发)以及 对一组参数的详尽搜索,可以非常轻松地运行交叉验证程序 。
1.Surprise安装
pip install numpy
pip install scikit-surprise
在安装之前首先确认安装了numpy模块。
2.基本算法
| 算法类名 | 说明 |
|---|---|
| random_pred.NormalPredictor | 根据训练集的分布特征随机给出一个预测值 |
| baseline_only.BaselineOnly | 给定用户和Item,给出基于baseline的估计值 |
| knns.KNNBasic | 最基础的协同过滤 |
| knns.KNNWithMeans | 将每个用户评分的均值考虑在内的协同过滤实现 |
| knns.KNNBaseline | 考虑基线评级的协同过滤 |
| matrix_factorization.SVD | SVD实现 |
| matrix_factorization.SVDpp | SVD++,即LFM+SVD |
| matrix_factorization.NMF | 基于矩阵分解的协同过滤 |
| slope_one.SlopeOne | 一个简单但精确的协同过滤算法 |
| co_clustering.CoClustering | 基于协同聚类的协同过滤算法 |
其中基于近邻的方法(协同过滤)可以设定不同的度量准则
| 相似度度量标准 | 度量标准说明 |
|---|---|
| cosine | 计算所有用户(或物品)对之间的余弦相似度。 |
| msd | 计算所有用户(或物品)对之间的均方差异相似度。 |
| pearson | 计算所有用户(或物品)对之间的Pearson相关系数。 |
| pearson_baseline | 计算所有用户(或物品)对之间的(缩小的)Pearson相关系数,使用基线进行居中而不是平均值。 |
支持不同的评估准则
| 评估准则 | 准则说明 |
|---|---|
| rmse | 计算RMSE(均方根误差)。 |
| mae | 计算MAE(平均绝对误差)。 |
| fcp | 计算FCP(协调对的分数)。 |
3.Surprise使用
(1)载入自带的数据集
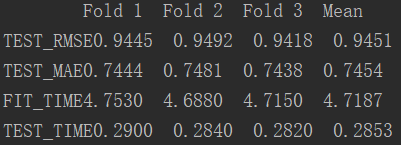
#-*- coding:utf-8 -*- # 可以使用上面提到的各种推荐系统算法 from surprise import SVD from surprise import Dataset, print_perf from surprise.model_selection import cross_validate # 默认载入movielens数据集 data = Dataset.load_builtin('ml-100k') # k折交叉验证(k=3),此方法现已弃用 # data.split(n_folds=3) # 试一把SVD矩阵分解 algo = SVD() # 在数据集上测试一下效果 perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) #输出结果 print_perf(perf)
运行结果:
(2)载入自己的数据集
from surprise import SVD from surprise import Dataset, print_perf, Reader from surprise.model_selection import cross_validate import os # 指定文件所在路径 file_path = os.path.expanduser('data.csv') # 告诉文本阅读器,文本的格式是怎么样的 reader = Reader(line_format='user item rating', sep=',') # 加载数据 data = Dataset.load_from_file(file_path, reader=reader) algo = SVD() # 在数据集上测试一下效果 perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) #输出结果 print_perf(perf)
需要注意:
1.无法识别中文,如果有中文,需要将其转换成ID号再进行操作(以下列出一种简单的转换方式)
2.不能有表头,需要去掉表头和元数据中有中文的列
3.需要修改Reader,line_format 就是数据的列,sep 是分隔方式(表格格式初始分割方式是‘,’)
一种简单的数据转换方式:
#-*- coding:utf-8 -*- # 构建物品id import pandas as pd df = pd.read_csv('train_score.csv', encoding="gbk") # 读取第二列的数据 item_name = df.iloc[:, 1] item = {} item_id = [] num = 0 # 将每个不同的物品与id号进行关联 for i in item_name: if i in item: item_id.append(item[i]) else: item[i] = num item_id.append(num) num += 1 print item_id df['itemId'] = item_id df.to_csv("data.csv", encoding="gbk", index=False)
4.算法调参
这里实现的算法用到的算法无外乎也是SGD等,因此也有一些超参数会影响最后的结果,我们同样可以用sklearn中常用到的网格搜索交叉验证(GridSearchCV)来选择最优的参数。简单的例子如下所示:
# 定义好需要优选的参数网格 param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005], 'reg_all': [0.4, 0.6]} # 使用网格搜索交叉验证 grid_search = GridSearch(SVD, param_grid, measures=['RMSE', 'FCP']) # 在数据集上找到最好的参数 data = Dataset.load_builtin('ml-100k') data.split(n_folds=3) grid_search.evaluate(data) # 输出调优的参数组 # 输出最好的RMSE结果 print(grid_search.best_score['RMSE']) # >>> 0.96117566386 # 输出对应最好的RMSE结果的参数 print(grid_search.best_params['RMSE']) # >>> {'reg_all': 0.4, 'lr_all': 0.005, 'n_epochs': 10} # 最好的FCP得分 print(grid_search.best_score['FCP']) # >>> 0.702279736531 # 对应最高FCP得分的参数 print(grid_search.best_params['FCP']) # >>> {'reg_all': 0.6, 'lr_all': 0.005, 'n_epochs': 10}
GridSearchCV 方法:
# 定义好需要优选的参数网格 param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005], 'reg_all': [0.4, 0.6]} # 使用网格搜索交叉验证 grid_search = GridSearchCV(SVD, param_grid, measures=['RMSE', 'FCP'], cv=3) # 在数据集上找到最好的参数 data = Dataset.load_builtin('ml-100k') # pref = cross_validate(grid_search, data, cv=3) grid_search.fit(data) # 输出调优的参数组 # 输出最好的RMSE结果 print(grid_search.best_score)
1.estimator
选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。
每一个分类器都需要一个scoring参数,或者score方法:
如estimator=RandomForestClassifier(
min_samples_split=100,
min_samples_leaf=20,
max_depth=8,
max_features='sqrt',
random_state=10),
2.param_grid
需要最优化的参数的取值,值为字典或者列表,例如:
param_grid =param_test1,
param_test1 = {'n_estimators':range(10,71,10)}。
3. scoring=None
模型评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',
根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,
需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。
4.n_jobs=1
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值
5.cv=None
交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield产生训练/测试数据的生成器。
6.verbose=0, scoring=None
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
7.pre_dispatch=‘2*n_jobs’
指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,
而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
8.return_train_score=’warn’
如果“False”,cv_results_属性将不包括训练分数。
9.refit :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,
作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
10.iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
进行预测的常用方法和属性
grid.fit():运行网格搜索
grid_scores_:给出不同参数情况下的评价结果
best_params_:描述了已取得最佳结果的参数的组合
best_score_:成员提供优化过程期间观察到的最好的评
5.使用不同的推荐系统算法进行建模比较
from surprise import Dataset, print_perf from surprise.model_selection import cross_validate data = Dataset.load_builtin('ml-100k') ### 使用NormalPredictor from surprise import NormalPredictor algo = NormalPredictor() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf) ### 使用BaselineOnly from surprise import BaselineOnly algo = BaselineOnly() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf) ### 使用基础版协同过滤 from surprise import KNNBasic, evaluate algo = KNNBasic() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf) ### 使用均值协同过滤 from surprise import KNNWithMeans, evaluate algo = KNNWithMeans() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf) ### 使用协同过滤baseline from surprise import KNNBaseline, evaluate algo = KNNBaseline() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf) ### 使用SVD from surprise import SVD, evaluate algo = SVD() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf) ### 使用SVD++ from surprise import SVDpp, evaluate algo = SVDpp() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf) ### 使用NMF from surprise import NMF algo = NMF() perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3) print_perf(perf)
6.movielens推荐实例
#-*- coding:utf-8 -*- from __future__ import (absolute_import, division, print_function, unicode_literals) import os import io from surprise import KNNBaseline from surprise import Dataset import logging logging.basicConfig(level=logging.INFO, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', datefmt='%a, %d %b %Y %H:%M:%S') # 训练推荐模型 步骤:1 def getSimModle(): # 默认载入movielens数据集 data = Dataset.load_builtin('ml-100k') trainset = data.build_full_trainset() #使用pearson_baseline方式计算相似度 False以item为基准计算相似度 本例为电影之间的相似度 sim_options = {'name': 'pearson_baseline', 'user_based': False} ##使用KNNBaseline算法 algo = KNNBaseline(sim_options=sim_options) #训练模型 algo.fit(trainset) return algo # 获取id到name的互相映射 步骤:2 def read_item_names(): """ 获取电影名到电影id 和 电影id到电影名的映射 """ file_name = (os.path.expanduser('~') + '/.surprise_data/ml-100k/ml-100k/u.item') rid_to_name = {} name_to_rid = {} with io.open(file_name, 'r', encoding='ISO-8859-1') as f: for line in f: line = line.split('|') rid_to_name[line[0]] = line[1] name_to_rid[line[1]] = line[0] return rid_to_name, name_to_rid # 基于之前训练的模型 进行相关电影的推荐 步骤:3 def showSimilarMovies(algo, rid_to_name, name_to_rid): # 获得电影Toy Story (1995)的raw_id toy_story_raw_id = name_to_rid['Toy Story (1995)'] logging.debug('raw_id=' + toy_story_raw_id) #把电影的raw_id转换为模型的内部id toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id) logging.debug('inner_id=' + str(toy_story_inner_id)) #通过模型获取推荐电影 这里设置的是10部 toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, 10) logging.debug('neighbors_ids=' + str(toy_story_neighbors)) #模型内部id转换为实际电影id neighbors_raw_ids = [algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors] #通过电影id列表 或得电影推荐列表 neighbors_movies = [rid_to_name[raw_id] for raw_id in neighbors_raw_ids] print('The 10 nearest neighbors of Toy Story are:') for movie in neighbors_movies: print(movie) if __name__ == '__main__': # 获取id到name的互相映射 rid_to_name, name_to_rid = read_item_names() # 训练推荐模型 algo = getSimModle() ##显示相关电影 showSimilarMovies(algo, rid_to_name, name_to_rid)
运行结果:
