简介
有时候,我们天真无邪的使用urllib库或Scrapy下载HTML网页时会发现,我们要提取的网页元素并不在我们下载到的HTML之中,尽管它们在浏览器里看起来唾手可得。
这说明我们想要的元素是在我们的某些操作下通过js事件动态生成的。举个例子,我们在刷QQ空间或者微博评论的时候,一直往下刷,网页越来越长,内容越来越多,就是这个让人又爱又恨的动态加载。
爬取动态页面目前来说有两种方法
- 分析页面请求
- selenium模拟浏览器行为
1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除JS选项卡还有可能在XHR选项卡中,当然也可以通过其它抓包工具),如下图
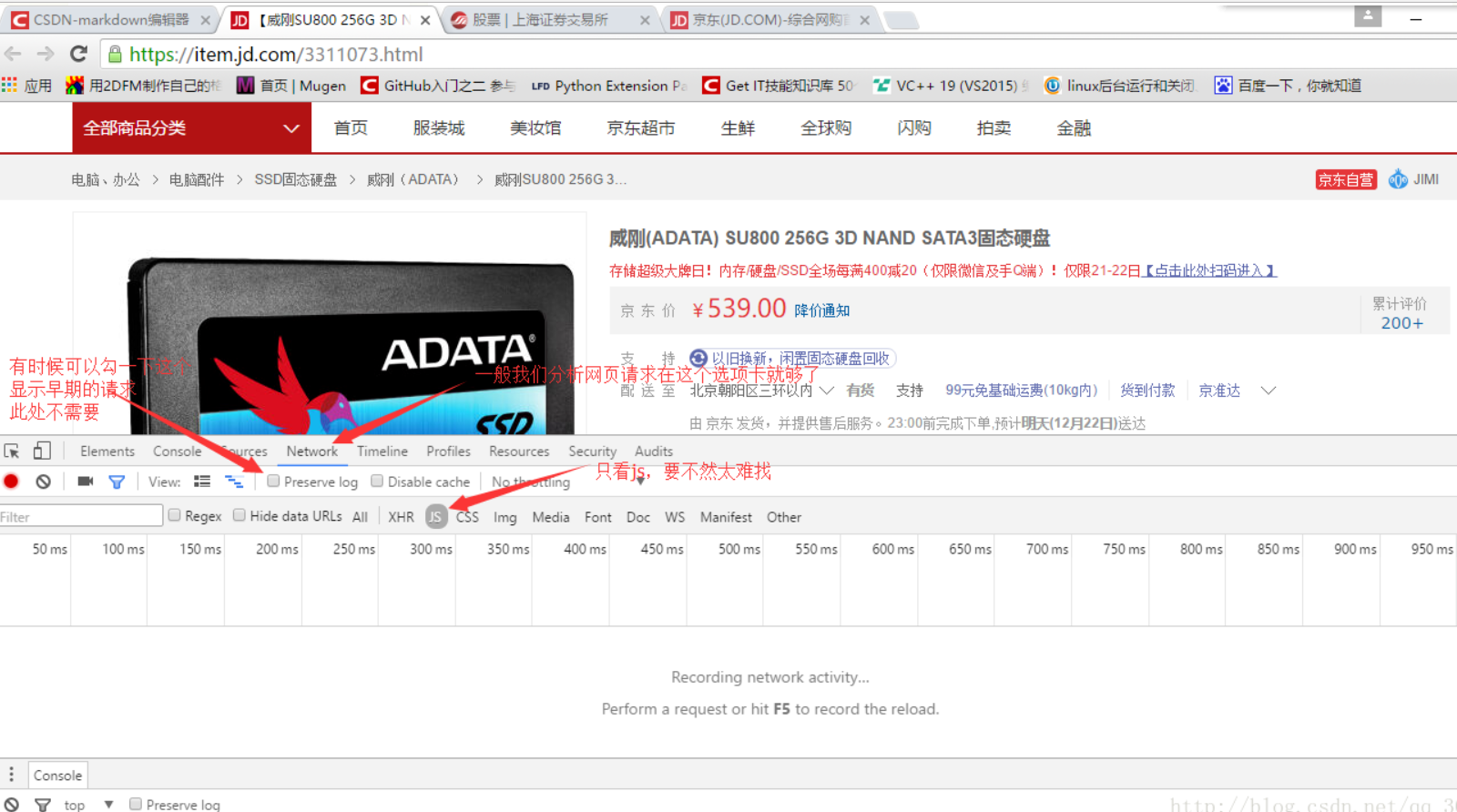
然后,我们来拖动右侧的滚动条,这时就会发现,开发者工具里出现了新的js请求(还挺多的),不过草草翻译一下,很容易就能看出来哪个是取评论的,如下图
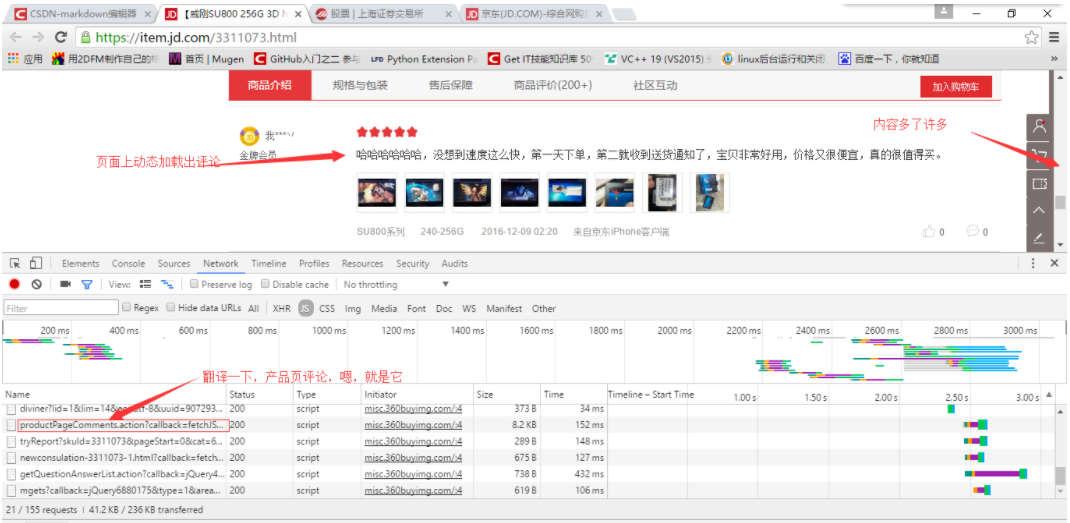
好,复制出js请求的目标url

在浏览器中打开,发现我们想要的数据就在这里,如下图
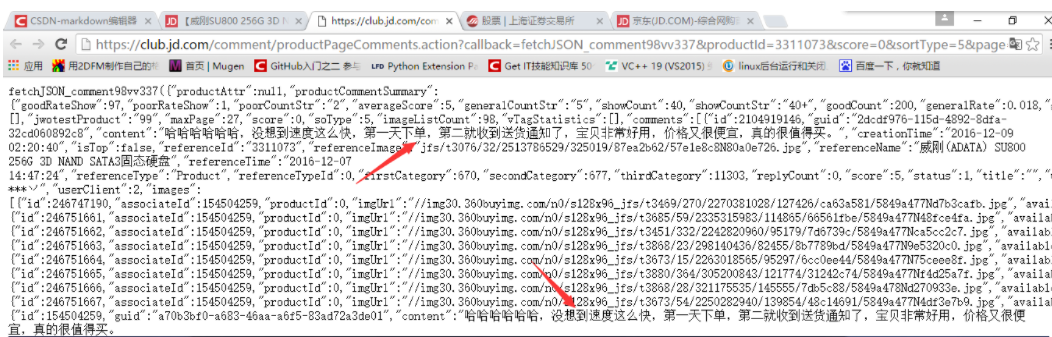
这整个页面是一个json格式的数据,对于京东来说,当用户下拉页面时,触发一个js事件,向服务器发送上面的请求取数据,然后通过一定的js逻辑把取到的这些json数据填充到HTML页面当中。对于我们Spider来说,我们要做的就是把这些json数据整理提取。
在实际应用中,当然我们不可能去每个页面里找出来这个js发起的请求目标地址,所以我们需要分析这个请求地址的规律,一般情况下规律是比较好找的,因为规律太复杂服务方维护也难。
2.selenium模拟浏览器行为
对于动态加载,能看到Selenium+Phantomjs的强大。打开网页查看网页源码(注意不是检查元素)会发现要爬取的信息并不在源码里面。也就是说,从网页源码无法通过解析得到数据。Selenium+Phantomjs的强大一方面就在于能将完整的源码抓取到
例子:在豆瓣电影上根据给出的名字搜索对应的信息
#-*- coding:utf-8 -*- import sys from selenium import webdriver from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup reload(sys) sys.setdefaultencoding('utf-8') url = 'https://movie.douban.com/' #这个路径就是你添加到PATH的路径 driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe') driver.get(url) #在搜索框上模拟输入信息并点击 elem = driver.find_element_by_name("search_text") elem.send_keys("crazy") elem.send_keys(Keys.RETURN) #得到动态加载的网页 data = driver.page_source soup = BeautifulSoup(data, "lxml") # 进行匹配 for i in soup.select("div[class='item-root']"): name = i.find("a", class_="title-text").text pic = i.find("img").get('src') url = i.find("a").get('href') rate = "" num = "" if i.find("span", class_="rating_nums") is None: print name.encode("gbk", "ignore"), pic, url else: rate = i.find("span", class_="rating_nums").text num = i.find("span", class_="pl").text print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")