awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。
- -F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
- -v var=value 赋值一个用户定义变量,将外部变量传递给awk
- -f scripfile 从脚本文件中读取awk命令
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。 $0 这个变量包含执行过程中当前行的文本内容。 [N] ARGC 命令行参数的数目。 [G] ARGIND 命令行中当前文件的位置(从0开始算)。 [N] ARGV 包含命令行参数的数组。 [G] CONVFMT 数字转换格式(默认值为%.6g)。 [P] ENVIRON 环境变量关联数组。 [N] ERRNO 最后一个系统错误的描述。 [G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。 [A] FILENAME 当前输入文件的名。 [P] FNR 同NR,但相对于当前文件。 [A] FS 字段分隔符(默认是任何空格)。 [G] IGNORECASE 如果为真,则进行忽略大小写的匹配。 [A] NF 表示字段数,在执行过程中对应于当前的字段数。 [A] NR 表示记录数,在执行过程中对应于当前的行号。 [A] OFMT 数字的输出格式(默认值是%.6g)。 [A] OFS 输出字段分隔符(默认值是一个空格)。 [A] ORS 输出记录分隔符(默认值是一个换行符)。 [A] RS 记录分隔符(默认是一个换行符)。 [N] RSTART 由match函数所匹配的字符串的第一个位置。 [N] RLENGTH 由match函数所匹配的字符串的长度。 [N] SUBSEP 数组下标分隔符(默认值是34)。
字符串函数
sub,gsub, gensub区别
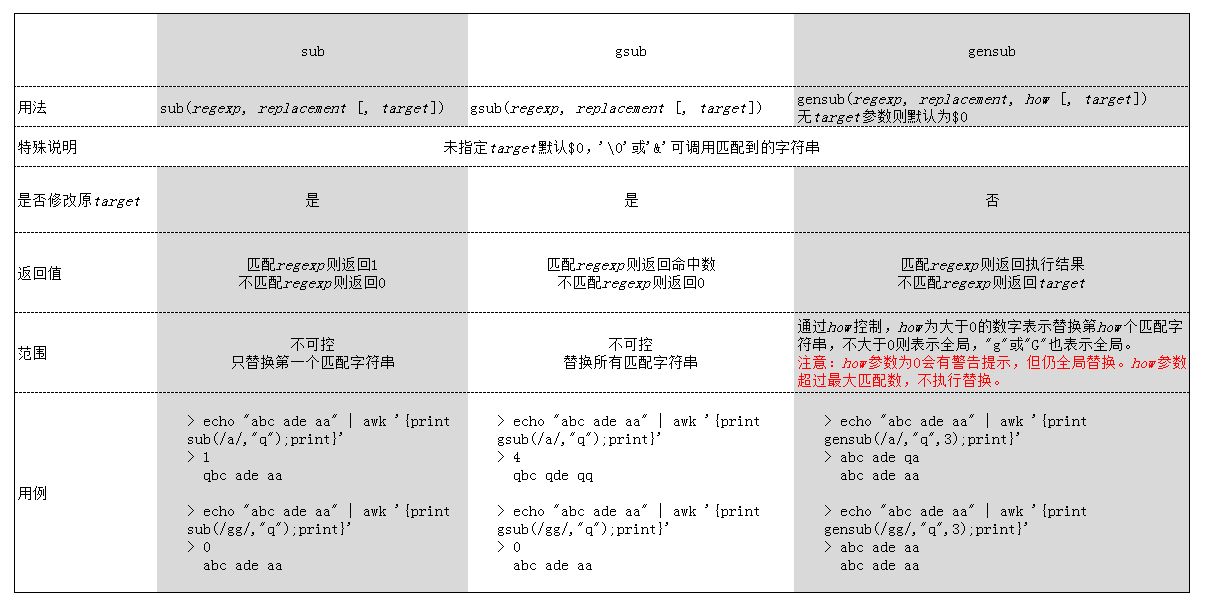
awk的内建函数split允许你把一个字符串分隔为单词并存储在数组中。你可以自己定义域分隔符或者使用现在FS(域分隔符)的值。
格式:
split (string, array) -->如果第三个参数没有提供,awk就默认使用当前FS值。
例子:
例1:替换分隔符
|
1
2
3
|
time="12:34:56"out=`echo $time | awk '{split($0,a,":");print a[1],a[2],a[3]}'`echo $out |
例2:计算指定范围内的和(计算每个人1月份的工资之和)
|
1
2
3
4
5
6
7
8
9
10
|
[root@test ~]# cat test.txtTom 2012-12-11 car 53000John 2013-01-13 bike 41000vivi 2013-01-18 car 42800Tom 2013-01-20 car 32500John 2013-01-28 bike 63500[root@test ~]# awk '{split($2,a,"-");if(a[2]==01){b[$1]+=$4}}END{for(i in b)print i,b[i]}' test.txt John 104500 |
二、substr 截取字符串
返回从起始位置起,指定长度之子字符串;若未指定长度,则返回从起始位置到字符串末尾的子字符串。格式:
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分
例子:
|
1
2
|
[root@test ~]# echo "123" | awk '{print substr($0,1,1)}'1 |
解释:
awk -F ',' '{print substr($3,6)}' ---> 表示是从第3个字段里的第6个字符开始,一直到设定的分隔符","结束.substr($3,10,8) ---> 表示是从第3个字段里的第10个字符开始,截取8个字符结束.
substr($3,6) ---> 表示是从第3个字段里的第6个字符开始,一直到结尾
三、length 字符串长度
length函数返回没有参数的字符串的长度。length函数返回整个记录中的字符数。
|
1
2
|
[root@test ~]# echo "123" | awk '{print length}'3 |
四、gsub函数
gsub函数则使得在所有正则表达式被匹配的时候都发生替换。gsub(regular expression, subsitution string, target string);简称 gsub(r,s,t)。
举例:把一个文件里面所有包含 abc 的行里面的 abc 替换成 def,然后输出第一列和第三列
|
1
|
awk '$0 ~ /abc/ {gsub("abc", "def", $0); print $1, $3}' abc.txt |
过滤中文字符集
1 echo 'zhangsan张三' |awk '{print gensub(/[^!-~]/,"","g",$0)}'
2 zhangsan
3 awk 'BEGIN{info="this is a test2010test!";gsub(/[0-9]+/,"!",info);print info}'
4 this is a test!test!
五、正则表达式
| 字符 | 功能 |
|---|---|
| + | 指定如果一个或多个字符或扩展正则表达式的具体值(在 +(加号)前)在这个字符串中,则字符串匹配。命令行:
awk '/smith+ern/' testfile 将包含字符 smit,后跟一个或多个 h 字符,并以字符 ern 结束的字符串的任何记录打印至标准输出。此示例中的输出是: smithern, harry smithhern, anne |
| ? | 指定如果零个或一个字符或扩展正则表达式的具体值(在 ?(问号)之前)在字符串中,则字符串匹配。命令行:
awk '/smith?/' testfile 将包含字符 smit,后跟零个或一个 h 字符的实例的所有记录打印至标准输出。此示例中的输出是: smith, alan smithern, harry smithhern, anne smitters, alexis |
| | | 指定如果以 |(垂直线)隔开的字符串的任何一个在字符串中,则字符串匹配。命令行:
awk '/allen | alan /' testfile 将包含字符串 allen 或 alan 的所有记录打印至标准输出。此示例中的输出是: smiley, allen smith, alan |
| ( ) | 在正则表达式中将字符串组合在一起。命令行:
awk '/a(ll)?(nn)?e/' testfile 将具有字符串 ae 或 alle 或 anne 或 allnne 的所有记录打印至标准输出。此示例中的输出是: smiley, allen smithhern, anne |
| {m} | 指定如果正好有 m 个模式的具体值位于字符串中,则字符串匹配。命令行:
awk '/l{2}/' testfile 打印至标准输出 smiley, allen |
| {m,} | 指定如果至少 m 个模式的具体值在字符串中,则字符串匹配。命令行:
awk '/t{2,}/' testfile 打印至标准输出: smitters, alexis |
| {m, n} | 指定如果 m 和 n 之间(包含的 m 和 n)个模式的具体值在字符串中(其中m<= n),则字符串匹配。命令行:
awk '/er{1, 2}/' testfile 打印至标准输出: smithern, harry smithern, anne smitters, alexis |
| [String] | 指定正则表达式与方括号内 String 变量指定的任何字符匹配。命令行:
awk '/sm[a-h]/' testfile 将具有 sm 后跟以字母顺序从 a 到 h 排列的任何字符的所有记录打印至标准输出。此示例的输出是: smawley, andy |
| [^ String] | 在 [ ](方括号)和在指定字符串开头的 ^ (插入记号) 指明正则表达式与方括号内的任何字符不匹配。这样,命令行:
awk '/sm[^a-h]/' testfile 打印至标准输出: smiley, allen smith, alan smithern, harry smithhern, anne smitters, alexis |
| ~,!~ | 表示指定变量与正则表达式匹配(代字号)或不匹配(代字号、感叹号)的条件语句。命令行:
awk '$1 ~ /n/' testfile 将第一个字段包含字符 n 的所有记录打印至标准输出。此示例中的输出是: smithern, harry smithhern, anne |
| ^ | 指定字段或记录的开头。命令行:
awk '$2 ~ /^h/' testfile 将把字符 h 作为第二个字段的第一个字符的所有记录打印至标准输出。此示例中的输出是: smithern, harry |
| $ | 指定字段或记录的末尾。命令行:
awk '$2 ~ /y$/' testfile 将把字符 y 作为第二个字段的最后一个字符的所有记录打印至标准输出。此示例中的输出是: smawley, andy smithern, harry |
| . (句号) | 表示除了在空白末尾的终端换行字符以外的任何一个字符。命令行:
awk '/a..e/' testfile 将具有以两个字符隔开的字符 a 和 e 的所有记录打印至标准输出。此示例中的输出是: smawley, andy smiley, allen smithhern, anne |
| *(星号) | 表示零个或更多的任意字符。命令行:
awk '/a.*e/' testfile 将具有以零个或更多字符隔开的字符 a 和 e 的所有记录打印至标准输出。此示例中的输出是: smawley, andy smiley, allen smithhern, anne smitters, alexis |
| (反斜杠) | 转义字符。当位于在扩展正则表达式中具有特殊含义的任何字符之前时,转义字符除去该字符的任何特殊含义。例如,命令行:
/a/// 将与模式 a // 匹配,因为反斜杠否定斜杠作为正则表达式定界符的通常含义。要将反斜杠本身指定为字符,则使用双反斜杠。有关反斜杠及其使用的更多信息,请参阅以下关于转义序列的内容。 |