作业格式描述
| 这个作业属于哪个课程 | <https://edu.cnblogs.com/campus/fzu/2020SPRINGS> |
|---|---|
| 这个作业要求在哪里 | <https://edu.cnblogs.com/campus/fzu/2020SPRINGS/homework/10287#4> |
| 这个作业的目标 | <掌握github的使用。疫情统计程序的需求分析及代码编写。> |
| 作业正文 | <https://www.cnblogs.com/lyxblogaxi/p/12287153.html> |
| 其他参考文献 | 暂无 |
一、Github仓库地址
https://github.com/is-lyx/InfectStatistic-main
二、阅读《构建之法》
- 本次作业的PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 360 | 450 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 180 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| Design | 具体设计 | 60 | 100 |
| Coding | 具体编码 | 360 | 450 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 40 | 80 |
| Test Repor | 测试报告 | 40 | 40 |
| Size Measurement | 计算工作量 | 5 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 1230 | 1695 |
三、解题思路描述
- fork项目示例结构到自己的仓库
因为之前没有接触过Github,所以这次根据作业下方提供的教程进行了Github的学习,对Github的使用有了基本的了解,方便后续的操作。
- main函数的传参问题
根据作业需求,我们需要使用命令行cd到目录的src下,编译.java文件,运行并且传入命令参数。那么这就涉及到了命令解析的问题。于是我决定使用ArrayList
来存储传入的参数,再调用函数进行分离、判断,取出list命令后具体的参数和参数值。 - 统计日志问题
我们需要根据-date的参数值汇总某一天或某一阶段的日志内容。仍然使用ArrayList
来分别存储需要统计日期的内容和汇总的内容。需要统计日期的内容包含统计日志的每一行,而汇总的内容是不包含重复省份,已经计算过总人数之后的内容。 - 数据统计问题
日志的数据如何进行提取?有一个非常好用的函数:split()。由于日志是使用空格进行分隔,所以我使用split(" ")对日志的每一行进行一个分隔,根据日志可能出现的8种情况进行分类,提取数据进行加和减差计算,最后输出到汇总的ArrayList
里。 - 根据要求输出问题
根据命令输入的-province和-type后的参数值输出对应要求的内容,先判断这两个命令是否存在参数值,再进行取值输出。因为-province和-type可能含有多个参数,所以在前面命令行解析的时候使用ArrayList
来存储对应的参数值。仍然使用split(" ")取出每一个参数值,对汇总的结果进行比对,把需要的内容到输出到String里,再写入对应路径的日志中。
四、设计实现过程
- 项目结构

- 关键SortLog函数流程图
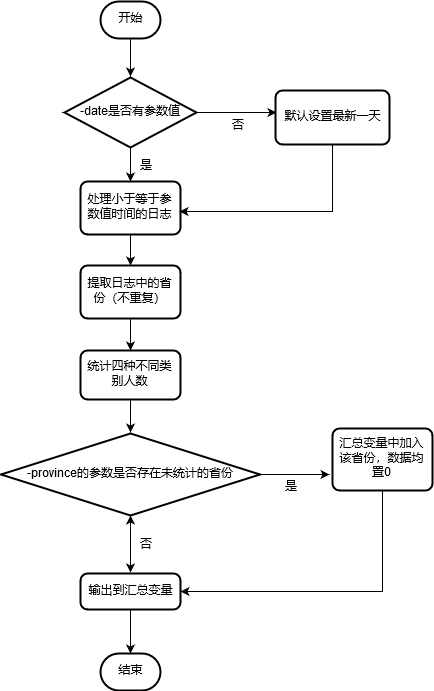
五、代码说明
-
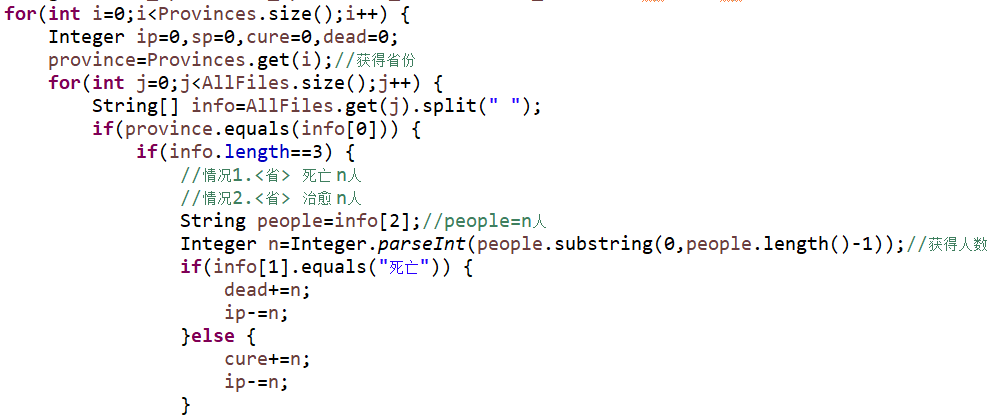
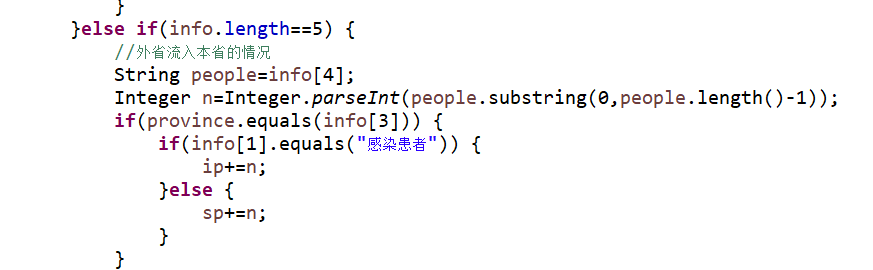
关键代码1


-
思路
这段代码是对日志进行数据的提取,并把日志中可能出现的八种情况进行了一个分类。首先判断每一个Province是否匹配日志每一行开头的省份,如果匹配则用split函数分隔后的长度进行分类,在大分类下又根据提取的“新增”、“感染患者”、“死亡”、“治愈”等关键性词语进行具体的数据处理。如果不匹配还要核对是否属于病例流入的情况,再对这种情况进行讨论即可。
-
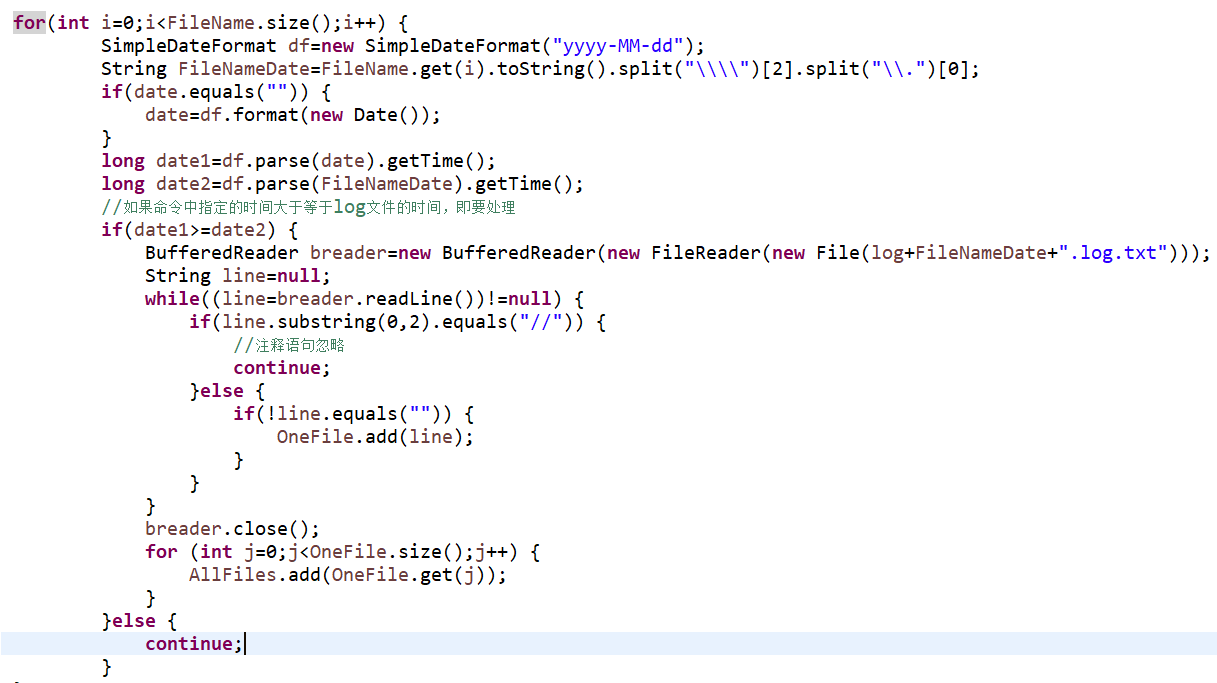
关键代码2
-
思路
这段代码是对-date参数值进行的处理。对-date的参数值进行一个判断,再选择性的读取对应的文档。代码基本上都是属于对文档的操作。
-
关键代码3
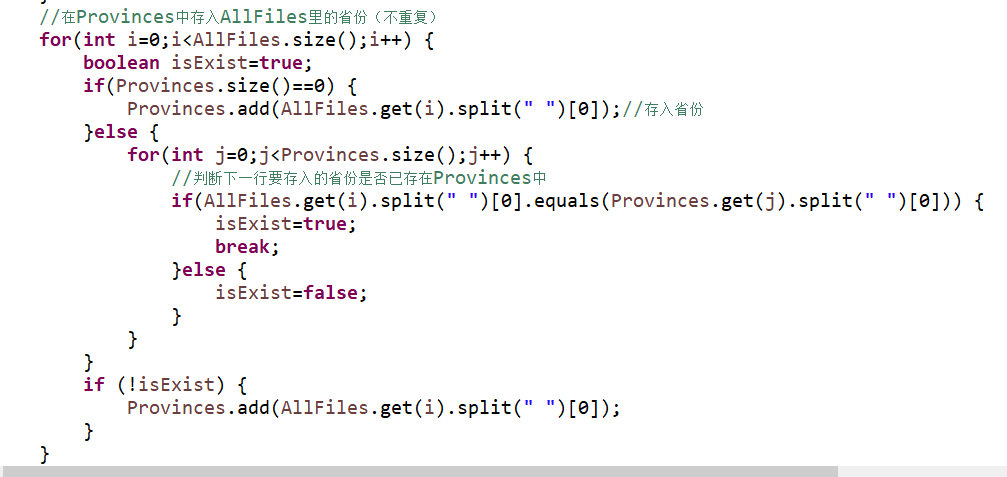
-
思路
这段代码主要是处理省份的问题,日志中的数据可能有n条属于同一省份的信息,这段代码就是为了过滤相同省份的操作。
六、单元测试截图和描述
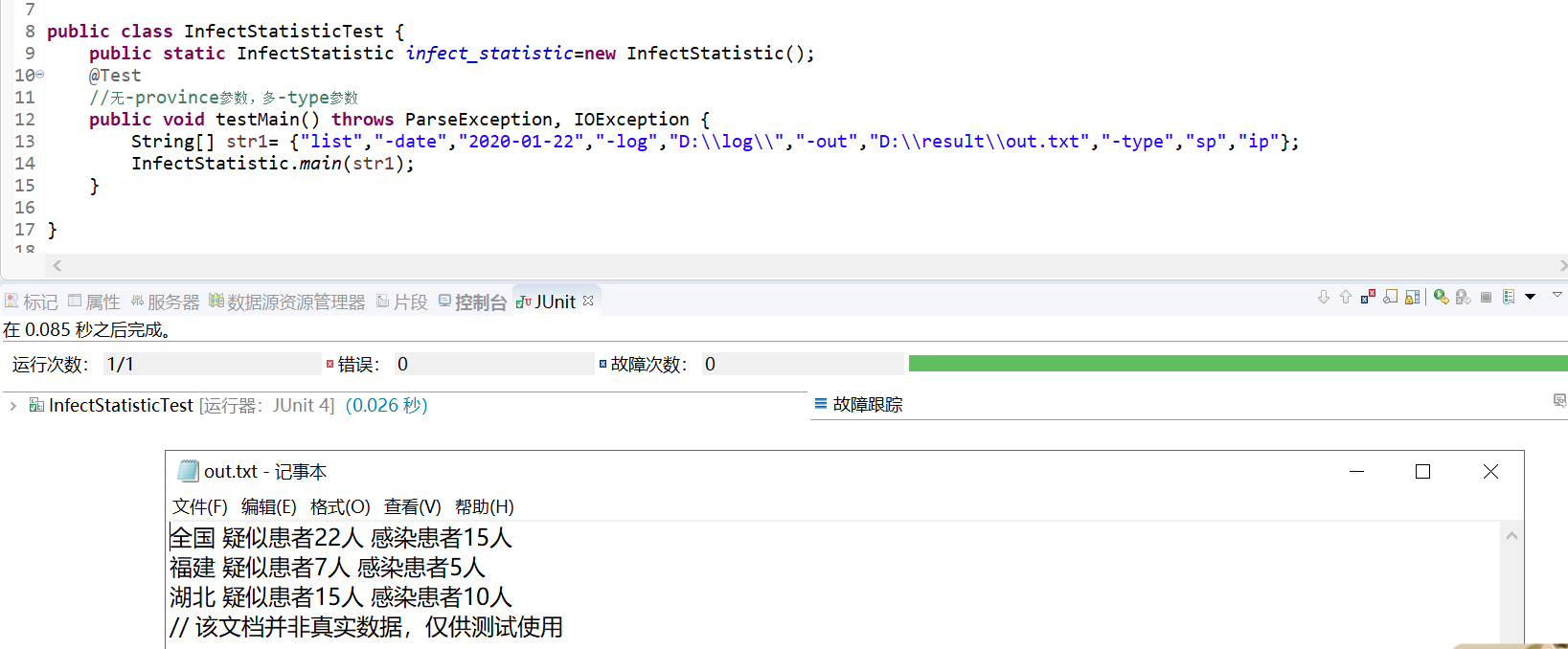
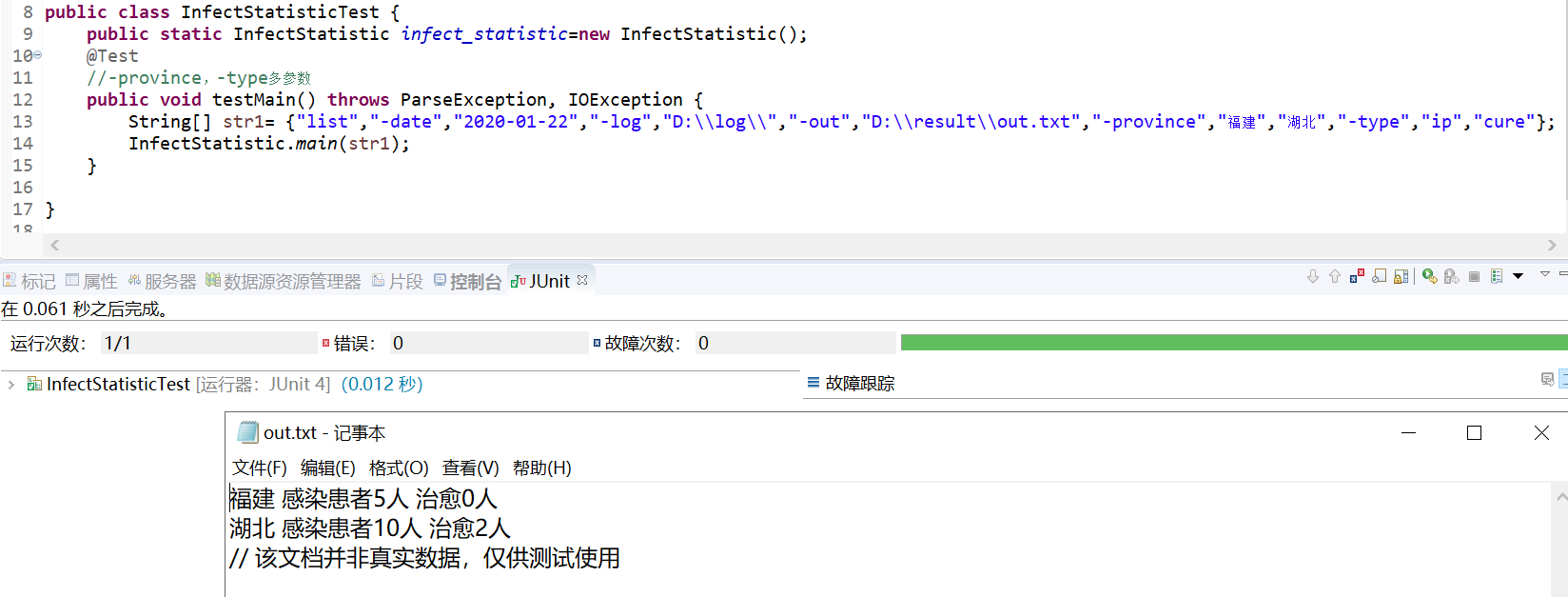
- 无-date、-province、-type参数测试

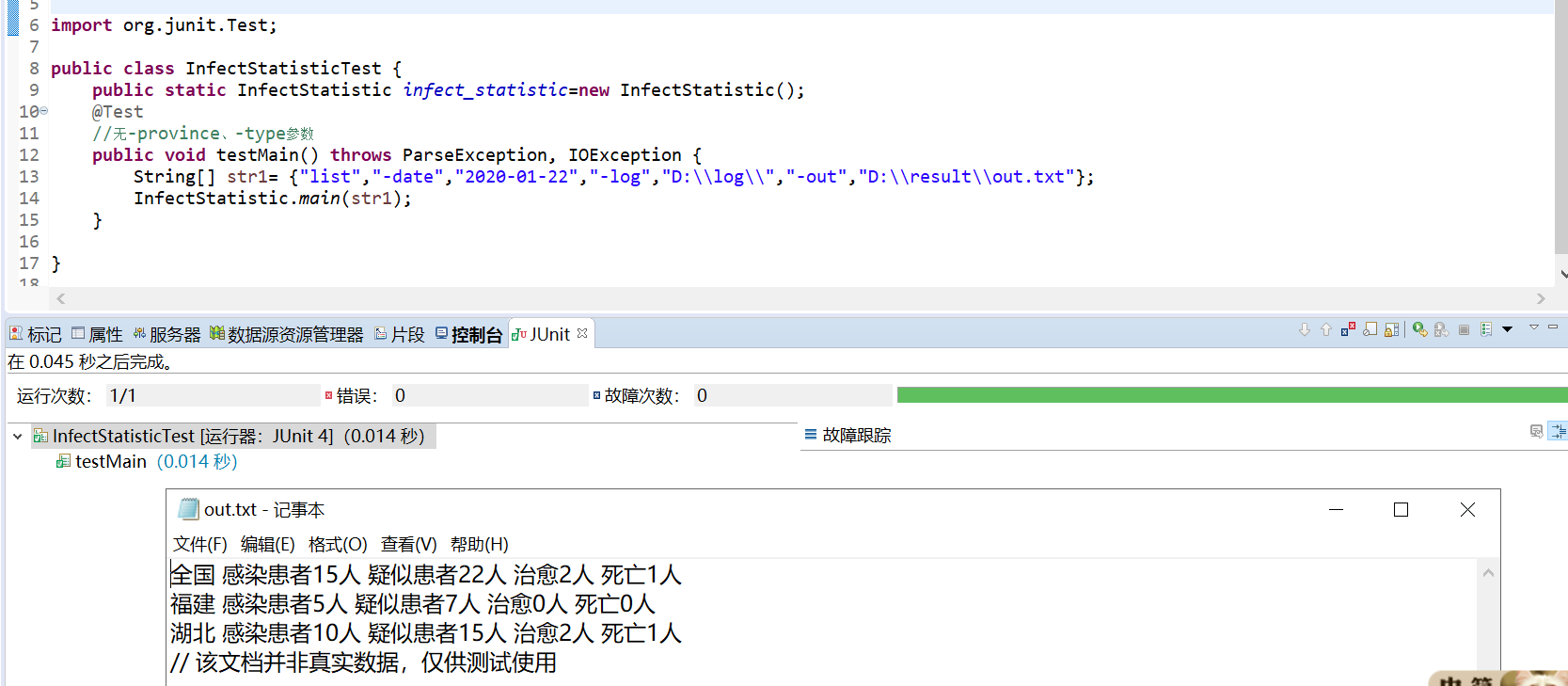
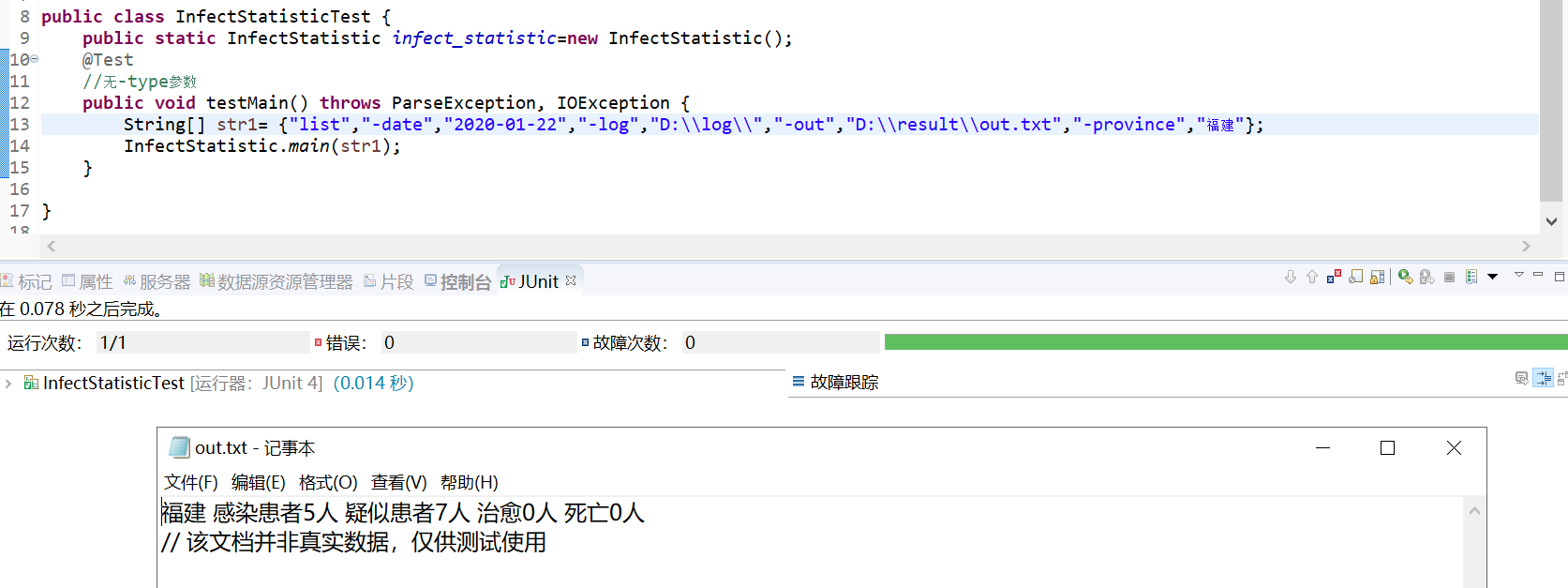

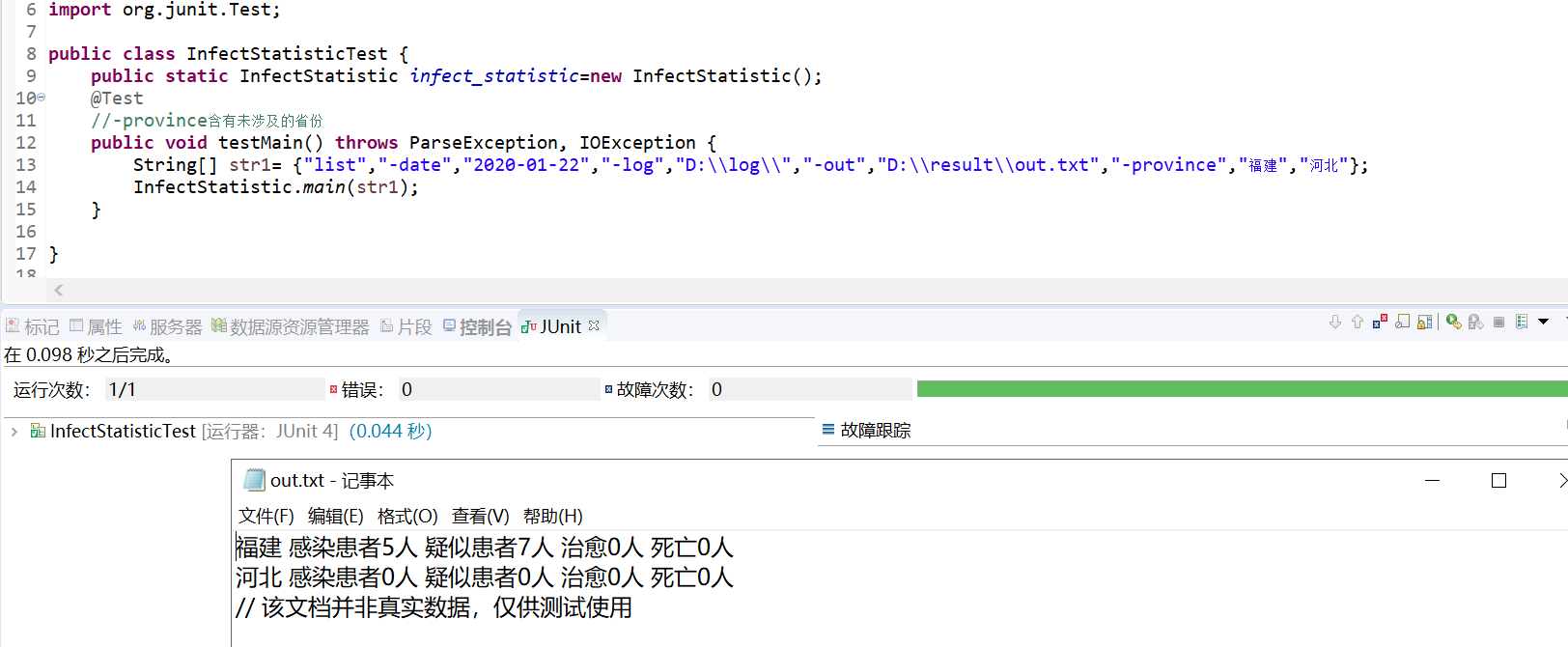


七、单元测试覆盖率优化和性能测试
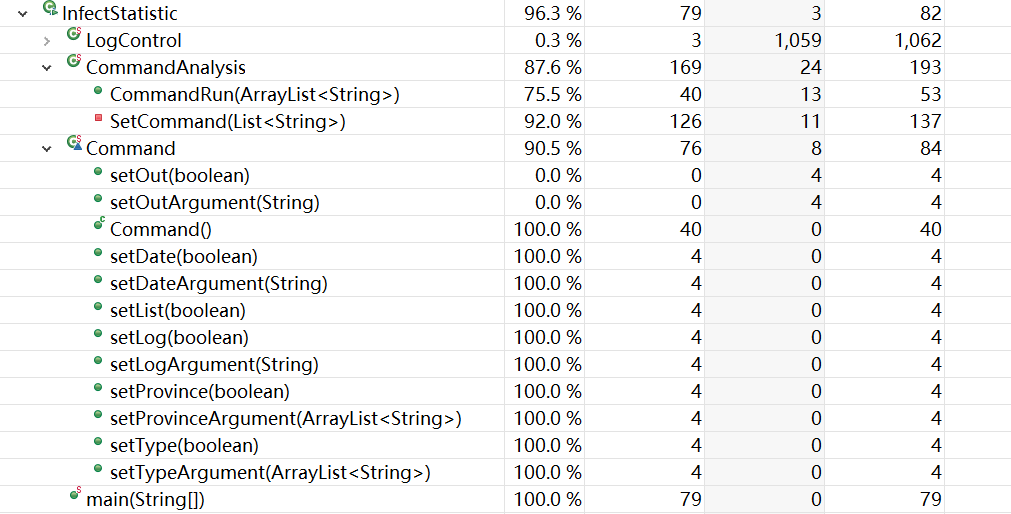
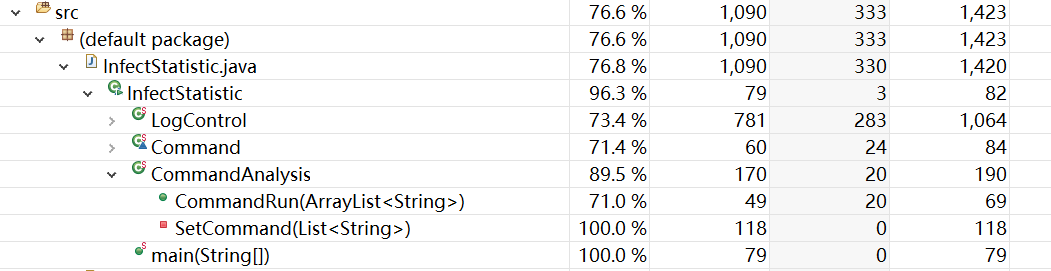
- 性能优化截图
优化前
- 描述
优化前的短板就是LogSort覆盖率很低,分析了一下是程序运行时参数传入的问题。这是因为当-log和-out没有传入参数时,系统会跳出,不进行后续的操作导致,使后面处理日志的LogSort没有运用到。
另外修改了一些原本在写结构时设置的,但在后续编程中使用次数较少(甚至没有)的函数。例如判断是否存在某个命令,实际上并不需要判断是否存在,而是通过switch语句直接获取对应命令后面的参数值即可。
除了“无用”函数之外,还对其中的一些代码段进行了优化。例如在循环判断语句中,频繁使用到了大致相同的结构的局部变量,则将相同结构的部分提取出来,后面的使用会使得代码段缩短很多,并且也提高了运行效率。
八、代码规范的链接
https://github.com/is-lyx/InfectStatistic-main/blob/master/221701407/codestyle.md
九、解决项目的心路历程与收获
其实这是我第一次看到这么长的作业……难免觉得很有压力。粗略地浏览一遍下来,一点头绪都没有,甚至连作业的要求都没有理解的很清楚。后面才慢慢地一段一段认真去研究、分析这份作业到底要我们做什么。我觉得对我来说,收获最大的就是学会了Github的使用,像打开了新天地一样,而且还可以在这上面找到很多优秀的开源项目,棒呆!另一个收获就是对设计软件的流程有了一个清晰的认知。以前总是觉得敲代码就是敲代码,给一个题目就打开编译器开始写,只要能得到题目要求的答案就算完成。现在不一样了,开始写代码之前和做完之后其实还要做很多的工作,例如设计流程图、类图,单元测试等等,只有把程序的框架理清楚了,类与类之间的关系设计好了,各个方法都进行测试没问题了,才能算上一个结构优良的程序。
十、Github中与Python相关的仓库
- 常见算法的python实现
这个仓库用python语言实现了绝大部分算法,包含了常见算法的python实现,如二叉树、排序、查找等等,主要是用于教学目的。
- Python框架Flask
Flask是一个微型的Python开发的Web框架,基于Werkzeug WSGI工具箱和Jinja2模板引擎。
- Python Web框架Django
Django是Python编程语言驱动的一个开源模型-视图-控制器(MVC)风格的Web应用程序框架。
- Web爬虫框架Scrapy
Scrapy是Python开发的一个快速、高层次的屏幕抓取和Web抓取框架。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
- jQuery-File-Upload
jQuery-File-Upload是一个jQuery图片上传组件,支持多文件上传、取消、删除,上传前缩略图预览、列表显示图片大小,支持上传进度条显示和各种动态语言开发的服务器端。