1、掌握外部文件读取和存储各类方法。
2、掌握异常的处理办法。
3、掌握外部模块导入和调用的方法。
实际应用中,我们绝大数的数据都是通过文件的交互完成的。
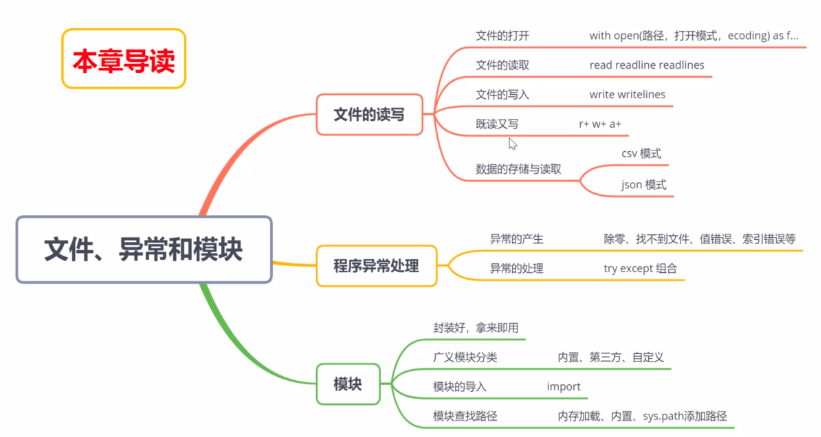
1.文件的读写
1.1 文件的打开
- 文件的打开通用格式
with open("文件路径","打开模式",encoding = "操作文件的字符编码") as f: # 对文件进行相应的读写操作
- ①文件路径:程序与文件在同一文件夹,可简化成文件名
- ②打开模式:
- "r" 只读模式,如文件不存在,报错
- "w" 覆盖写模式,若文件不存在,则创建;若文件存在,则完全覆盖原文件
- "x" 创建写模式,若文件存在,则报错,若不存在则创建
- "a" 追加写模式,若文件不存在,则创建,若存在则在原文件后追加内容
- "b" 二进制文件模式,不能淡入使用,需要配合使用如"rb" "wb" "ab",该模式不需指定encoding
- "t" 文本文件模式,默认值,需配合使用如"rt" "wt" "at"
- "+" 与"r" "w" "x" "a"配合使用,在原功能基础上,增加读写功能
- 打开模式缺省,默认为只读模式- ③字符编码:
- utf-8:万国码,包含全世界所有国家需要用到的字符
- gbk:中文编码,专门解决中文编码问题,Windows系统,如果缺省,则默认gbk(所在区域的编码),建议除处理二进制文件,建议不要缺省encoding
使用with块的好处:执行完毕后,自动对文件进行close操作
with open("E:ipthon测试文件.txt","r",encoding="gbk") as f: # 打开文件
text = f. read() # 读取文件
print(text)
1.2 文件的读取
- 读取整个内容——f.read()
- 解码模式不匹配,报错
- 逐行进行读取——f.readline()
- 读入所有行,以每行为元素形成一个列表——f.readlines()
- 图片是二进制文件
注意:当文件比较大时,read()和readlines()占用内存过大,不建议使用,推荐使用如下方式
with open("三国演义片头曲_gbk.txt","r",enconding="gbk") as f:
for text in f: # f本身就是一个可迭代对象,每次迭代读取一行内容
print(text)
1.3 文件的写入
- 向文件写入一个字符串或字符流(二进制)——f.write()
- 追加模式——"a"
- 将一个元素为字符串的列表整体写入文件——f.writelines()
ls = ["春天刮着风", "秋天下着雨", "春风秋雨多少海誓山盟随风远去"]
with open("恋雨1980.txt", "w", encoding="utf-8") as f:
f.writelines(ls)
1.4 既读又写
- "r+":如果文件名不存在,则报错;文件指针在文件最开始,需要把指针移动到末尾才能开始写,否则会覆盖前面内容
with open("浪淘沙_北戴河.txt", "r+", encoding="utf-8") as f:
# for line in f:
# print(line) #遍历文件f,指针达到结尾
f.seek(0, 2) # 或者可以将指针移到末尾f.seek(偏移字节数,位置(0:开始;1:当前位置;2:结尾))
text = ["萧瑟秋风今又是,
", "换了人间,
"]
f.writelines(text)
- "w+":若文件不存在,则创建;若文件存在,会立刻清空原内容
with open("浪淘沙_北戴河.txt", "w+", encoding="utf-8") as f:
text = ["萧瑟秋风今又是,
", "换了人间,
"] # 清空原内容
f.writelines(text)
f.seek(0, 0) # 指针移到开始
print(f.read())
- "a+":若文件不存在,则创建;指针在末尾,添加新内容,不会清空原内容
2 数据的存储与读取
通用的数据格式,可以在不同语言中加载和存储,主要了解数据存储结构csv和json
2.1 csv格式
csv格式由逗号将数据分开的字符序列,可以由excel打开
- 读取

with open("成绩.csv","r",encoding="gbk") as f:
ls = []
for line in f:
ls.append(line.strip("
").split(",")) #去掉每行的换行符,并用","进行分割返回列表
for res in ls:
print(res)

- 写入
ls = [["编号", "数学成绩", "语文成绩"], ['1', '100', '98'], ['3', '97', '95']]
with open("score.csv","w",encoding="gbk") as f: # encoding="utf-8"中文出现乱码
for row in ls:
f.write(",".join(row)+"
") # 逐行写入.用逗号组合成字符串形式
也可借助csv模块完成上述操作
2.2 json格式
常用来存储字典格式
- 写入——dump()
scores = {"Petter": {"math": 96, "pysics": 98},
"Paul": {"math": 92, "pysics": 99},
"Mary": {"math": 98, "pysics": 97}}
with open("score.json", "w", encoding="utf-8") as f:
# indent:表示字符串换行+缩进 ensure_ascii=False 显示中文
json.dump(scores, f, indent=4, ensure_ascii=False)
- 读取——load()
with open("score.json", "r", encoding="utf-8") as f:
scores = json.load(f) # 加载整个对象
for k, v in scores.item():
print(k, v)
3 异常处理
3.1 常见异常的产生
- 除0异常——ZeroDivisionError
- 找不到可读文件——FileNotFoundError
- 值错误——ValueError:传入一个调用者不期望的值,即使这个值的类型是正确的
- 类型错误——TypeError:传入对象类型与要求不符
- 索引错误——IndexError:下标超出序列边界
- 其他常见的异常类型:NameError使用一个还未被赋予对象的变量KeyError试图访问字典里不存在的键
当异常发生的时候,如果不预先设定处理方法,程序就会中断
3.2 异常的处理
提高程序的稳定性和可靠行
try_except
如果try内代码块顺利执行,except不被触发;如果try内代码块发生错误,触发except执行except内代码块
- 单分支
x = 10
y = 0
try:
z = x/y
except ZeroDivisionError:
print("0不可以被除")
- 多分支
d = {"name": "大杰仔"}
try:
d["age"]
except NameError:
print("变量名不存在")
except IndexError:
print("索引超出界限")
except KeyError:
print("键不存在")
- 万能异常 Exception(所有错误的老祖宗)
- 捕获异常的值 as
ls = []
d = {"name": "大杰仔"}
try:
y = x
ls[3]
d["age"]
except Exception as e:
print(e)
- try_except_else:如果try模块执行,则else模块也会执行,也可将else看做try成功的额外奖赏
- try_except_finally:不论try模块是否执行,finally都会被执行
4 模块
已经被封装好,无需自己再"造轮子",声明导入后拿来即用
4.1 广义模块分类
- ①Python内置:时间库time;随机库random;容器数据类型collection;迭代器函数itertools
- ②第三方库:数据分析numpy、pandas;数据可视化matplotlib;机器学习scikit-learn;深度学习Tensorflow
- ③自定义文件:文件夹内有多个py文件,再加一个__init__.py文件(内容可为空)
4.2 模块的导入
- 导入整个模块——import 模块名
- 调用方式:模块名.函数名或类名 - 从模块中导入类或函数——from 模块 import 类名或函数名
- 调用方式:函数名或类名 - 导入模块中所有的类和函数—— from 模块 import *
4.3 模块的查找路径
模块搜索查找顺序:
- ①内存中已经加载的模块
- ②内置模块:Python启动时,解释器会默认加载一些modules 存放在sys.modules(包含一个由当前载入(完整且成功导入)到解释器的模块组成的字典,模块名作为域,他们的位置作为值)中
import sys
print(len(sys.modules))
print("math" in sys.modules)
print("numpy" in sys.modules)
for k,v in list(sys.modules.items())[:5]:
print(k, ":", v)
"""
875
True
True
sys : <module 'sys' (built-in)>
builtins : <module 'builtins' (built-in)>
_frozen_importlib : <module 'importlib._bootstrap' (frozen)>
_imp : <module '_imp' (built-in)>
_thread : <module '_thread' (built-in)>
"""
- ③sys.path路径中包含的模块:sys.path的第一个路径是当前执行文件所在的文件夹;若需将不在该文件夹内的模块导入,需要将模块的路径添加到sys.path
import sys
sys.path.append("C:\User\ibm\Desktop") #注意是双斜杠
import fun3
fun3.f3()