0. 引子
在训练轻量化模型时,经常发生的情况就是,明明 GPU 很闲,可速度就是上不去,用了多张卡并行也没有太大改善。
如果什么优化都不做,仅仅是使用nn.DataParallel这个模块,那么实测大概只能实现一点几倍的加速(按每秒处理的总图片数计算),不管用多少张卡。因为卡越多,数据传输的开销就越大,副作用就越大。
为了提高GPU服务器的资源利用率,尝试了一些加速的手段。
基于Pytorch1.6.0版本实现,官方支持
amp功能,不再需要外部apex库;
此外比较重要的库是Dali。
梳理了训练框架,并将参考代码放到Github上。
如果觉得对你有所启发,请给个star呀。
1. 训练速度的瓶颈及应对思路
这边主要说的是CV领域,但在其他领域,思路应该也是相通的。
模型训练过程中,影响整体速度的因素主要有以下几点:
- 将数据从磁盘读取到内存的效率;
- 对图片进行解码的效率;
- 对样本进行在线增强的效率;
- 网络前向/反向传播和Loss计算的效率;
针对这几个因素,分别采取如下几种应对思路:
- 加快数据读取可以有几种思路:
- 采取类似TF的tfrecord或者Caffe的lmdb格式,提前将数据打包,比反复加载海量的小文件要快很多,但pytorch没有通用的数据打包方式;
- 在初始化时,提前将所有数据加载到内存中(前提是数据集不能太大,内存能装得下);
- 将数据放在SSD而非HDD,可以大大提速(前提是你有足够大的SSD);
- 提升图片解码速度,可以考虑采用NVIDIA-DALI库,能够利用GPU来加速JPG格式的图片解码,针对其他格式的图片(如PNG),不能实现GPU加速,但也可以兼容;
- 提升样本在线增强的效率,同样可以通过NVIDIA-DALI库,实现GPU加速;
- 在网络结构确定的情况下,提速主要有两种方式,并且可以同时采用:
- 采用Data Parallel的多卡并行训练
- 采用amp自动混合精度训练
2. 实验配置
2.1 服务器
服务器为4卡TITAN RTX,进行实验时停止了其他高资源消耗的进程。
2.2 基本配置
- Dataset:ImageNet
- Model:MobilenetV2
- Augmentation:RandomCrop,RandomFlip,Resize,Normalization
- 每个进程的
batch_size:256 - 每个进程的
Dataloader的num_threads:8
3. 具体实现中的注意点
3.1 关于Dataloader
在使用DALI库构建Dataloader时,建议采用ops.ExternalSource的方式来加载数据,这样可以实现比较高的自由度。
示例代码中只实现了分类任务的dataloader,但按照这种方式构建,很容易实现其他如检测/分割任务的dataloader。
只要把数据来源按照迭代器来实现,就可以套用到ops.ExternalSource这一套框架下。
参见src/datasets/cls_dataset_dali.py中的ClsInputIterator。
3.2 关于Loss
在训练过程中,每个进程分别计算各自的loss,通过内部同步机制去同步loss信息。但是在训练中需要监控过程,此时需要计算所有loss的均值。
参见src/train/logger.py中关于reduce_tensor的计算方式。
3.3 关于多进程参数的选取
在训练过程中,实验用的服务器,CPU共32核心,4卡并行,因此每个进程的Dataloader,设定的num_threads为8,测试下来效率最高。
如果num_gpusnum_threads < CPU核心数,不能充分利用CPU资源;
如果num_gpusnum_threads > CPU核心数,速度反而也会有所下降。
4. 训练速度实测结果
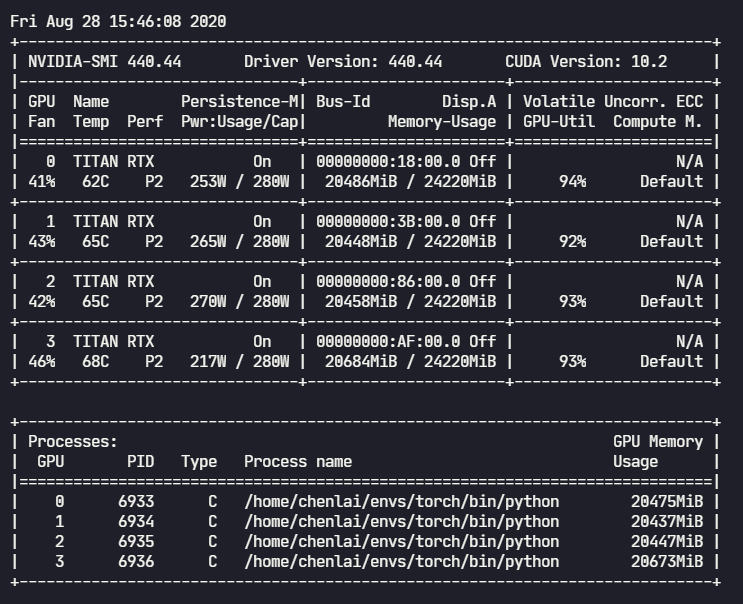
4.1 未开启amp时的GPU占用
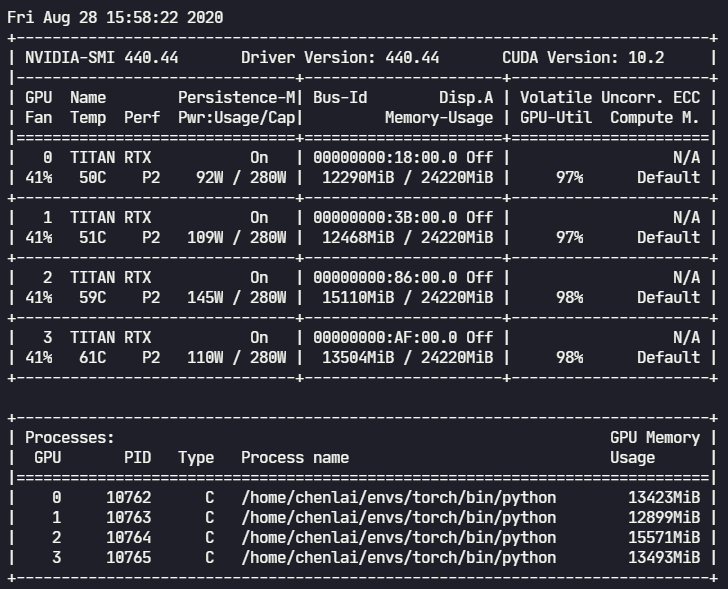
4.2 开启amp后的GPU占用
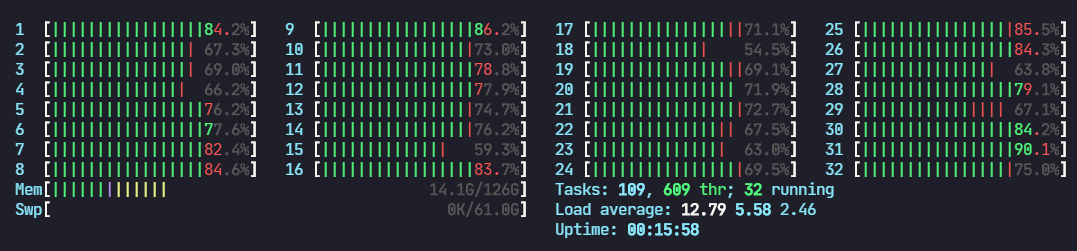
4.3 CPU占用情况
开启/关闭amp对于CPU的影响不大,基本看不出区别
4.4 综合训练速度
4卡并行,BS为256,训练集约120W图片。训练速度为:
- 未开启amp:约 2.4 iters/s(2458 帧/s),每个epoch训练时间不到 9 min;
- 开启amp:约 3.8 iters/s(3891 帧/s),每个epoch训练时间不到 6 min;
5. 一些总结
通过综合采用各种训练加速手段,基本可以做到充分利用多显卡服务器的GPU和CPU资源,不会造成硬件资源的浪费;
- 通过
Nvidia-Dali模块的合理配置,可以显著提升数据加载和在线增强阶段的效率,特别是在训练一些轻量化模型时,往往瓶颈不在于GPU的计算速度,而在于CPU等其他部件的负载; - 通过
DistributedDataParallel模块的合理配置,可以实现多卡的负载均衡,不论是显存占用还是GPU利用率,都能够达到平衡,不会有其中1张卡变成效率瓶颈; - 通过
torch.cuda.amp模块的合理配置,可以进一步降低显存占用,从而可以设置更大的batch_size,提高模型收敛速度; torch.cuda.amp模块还可以显著降低网络前向推理时间,从而进一步提高训练效率。
综合应用如上所述的手段,基本上可以实现显卡数量和训练效率之间的线性增长关系。
不会发生卡多了,但是单卡的效率却大大下降的现象。
6. 一些意外
原以为本篇到此就该结束了,但又遇到了新的问题。
当训练执行一段时间后,由于整个系统长时间处于高负载的状态,显卡温度飙升,触发了显卡的保护机制,自动降频了,GPU利用率直接降到了原来的一半左右。
之前显卡运行效率低的时候,散热不良的问题还没有显露出来,一旦长时间高负荷运转,多卡密集排布和风冷散热的不足就暴露出来了。
下一步是要折腾水冷散热了么?