集合介绍
1.集合是什么?
容器:用来存放数据的东西.
在java中,集合就是容器,用来存放不同类型的数据.
2.集合和数组的区别:
共同点:
集合和数组都是容器,都可以存储数据;
不同点:
1.集合长度可变,数组长度是固定的;
2.集合只能存储引用类型的数据,不能存储基本类型,而数组可以存储基本类型的数据;
3.集合可以存放不同类型的数据,而数组只能存储同一种类型的数据.
3.集合的继承体系:
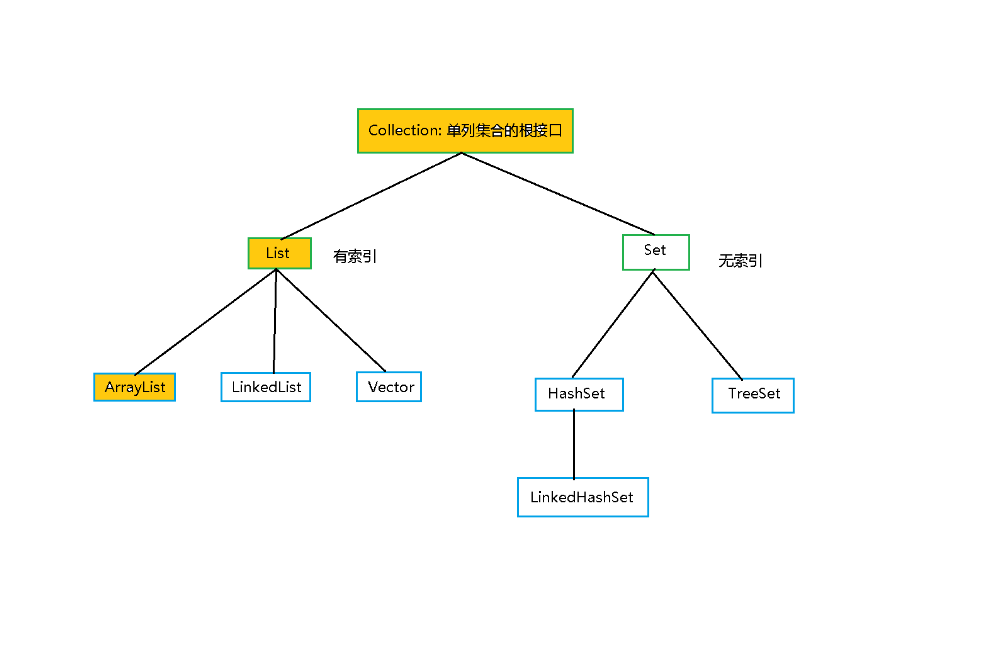
4.常用的功能: add: public boolean add(E e) : 添加元素; clear: public void clear() : 清空集合; remove: public boolean remove(E e) : 按照元素删除; contains: public boolean contains(Object o) : 判断集合中是否包含指定的元素; isEmpty: public boolean isEmpty() : 判断集合是否为空(空: 不是null, 而是长度为0); size: public int size() : 获取集合的长度, 集合中元素的个数; Iterator:迭代器的使用 使用多态声明:Collection<String> c = new ArrayList<>(); 上面的语句使用了多态,编译看左边,Collection中没有索引,所以无法使用索引进行遍历,此时就需要用到迭代器Iterator进行遍历. 迭代器使用的代码演示: public class CollectionDemo01 { public static void main(String[] args) { //ArrayList<String> list = new ArrayList(); Collection<String> list = new ArrayList(); list.add("湖北"); list.add("广东"); list.add("江西"); list.add("湖南"); //System.out.println(list); //迭代器的使用: //1.获取迭代器,注意一条iterator.hasNext()对应一条iterator.next()语句 Iterator<String> iterator = list.iterator(); //2.判断是否还有下一个元素 while (iterator.hasNext()) { //3.获取下一个元素 String province = iterator.next(); System.out.println(province); } } }
增强for循环: for (容器中元素的数据类型 变量名 : 容器) { 使用变量; } 快捷键:容器.for -> enter 例如: public class CollectionDemo01 { public static void main(String[] args) { //ArrayList<String> list = new ArrayList(); Collection<String> list = new ArrayList(); list.add("湖北"); list.add("广东"); list.add("江西"); list.add("湖南"); //增强for循环 for (String pro : list) { System.out.println(pro); } } } 注意事项: 使用迭代器或者增强for遍历集合的同时, 不要增删集合中的元素. 否则会出现 `ConcurrentModificationException` 5.泛型的基本知识: 作用: 用来限定集合中元素的数据类型. 好处: 1. 将问题从运行时期, 提前到编译时期. 2. 省去了强转的麻烦 泛型类:在创建对象的时候确定具体数据类型; 例如: ArrayList<String> 泛型接口: 实现类实现接口的时候直接指定泛型的具体数据类型; 实现类实现接口的时候不指定, 等到创建实现类对象的时候确定具体的数据类型; 例如: List<String> 泛型方法: 在调用方法的时候, 确定泛型的具体数据类型; public static <P> void fun(ArrayList<P> list) { } 泛型通配符: ? 有如下两种用法: 固定泛型的上边界: <? extends E> : 集合的泛型可以是E, 也可以是E的子类; 固定泛型的下边界: <? super E> : 集合的泛型可以是E, 也可以是E的父类; 6.常见数据结构的基本知识; Stack栈: 经典模型:弹夹 特点:先进后出(FILO) 常见的数据类型: 队列: 经典模型:隧道 特点:先进先出(FIFO) 常见的数据类型:数组 链表: 结构:头部指针,中间存储区,尾部指针; 特点:增删快,查询慢; 常见的数据类型:linkedList 增删快的原因: 在进行增删操作的时候,只需要改变前一个元素的指针指向即可; 查询慢的原因: 在进行查询的时候,就双向链表为例:会先判断要查找的元素的node索引值是在链表的前半部分还是后半部分; 如果是前半部分,则从头部开始查找,一个一个往后查找; 如果是在链表的后半部分,则从尾部开始,一个一个往前查找; 数组结构的特点: 查询快,增删慢; 查询快的原因: 1.数组有索引; 2.数组是一段连续的内存空间; 增删慢的原因: 1.数组长度是固定的,在进行增删时,会先创建一个长度固定的数组,再将原数组中的数据拷贝到新数组; List的特点: 有序:存储和取出是有顺序的(先进先出); 有索引; 可重复:集合中的元素是可以重复的; 所以有索引的方法都是List特有的; List接口的子类: ArrayList:底层的数据结构是数组; LinkedList:底层数据结构是链表; Vector:已经被ArrayList取代了; 7.集合的工具类: Collections:操作集合的工具类; Arrays:操作数组的工具类; Collections中的常用方法: addAll: public static <T> boolean addAll(Collection<T> c, T... elements) 将可变参数中的每一个元素, 都添加到c集合中; sort:自然排序 public static <T extends Comparable<T>> void sort(List<T> list) : 排序 传入集合中泛型的数据类型, 必须是Comparable的实现类; 使用实例: public class SortDemo01 { public static void main(String[] args) { ArrayList<Integer> list = new ArrayList(); Collections.addAll(list, 5, 4, 6, 2, 3, 1); System.out.println("排序前:"+list); //注意,使用sort方法,集合的泛型必须实现了Comparable接口,查看源码,可以发现Integer类型实现了该接口 Collections.sort(list); System.out.println("排序后:"+list); } } Comparator:比较器排序 public static <T> void sort(List<T> list, Comparator<T> c) 使用实例: public class SortByComparator { public static void main(String[] args) { ArrayList<Person> list = new ArrayList(); list.add(new Person("双儿", 18)); list.add(new Person("沐剑屏", 22)); list.add(new Person("阿珂", 20)); list.add(new Person("曾柔", 24)); //排序,sort肯定不行了,因为Person并没有实现Comparable接口 //使用比较器排序 //new 接口名() {}:表示实现了该接口的实现类对象 Collections.sort(list, new Comparator<Person>() { /** * o1-o2:表示按照升序排序 * o2-o1:表示按照降序排序 * @param o1 * @param o2 * @return */ @Override public int compare(Person o1, Person o2) { //按照年龄升序排序 return o1.getAge() - o2.getAge(); } }); for (Person person : list) { System.out.println(person); } } } 可变参数:实质上就是可变数组 用于形参位置,格式如下: (数据类型 ... 变量名) 作用:该方法可以传入**任意个该数据类型**的参数 应用实例: public class ParaDemo01 { public static void main(String[] args) { System.out.println(sum()); System.out.println(sum(1)); System.out.println(sum(1,2)); System.out.println(sum(1,2,3)); System.out.println(sum(1,2,3,4)); System.out.println(sum(1,2,3,4,5)); } public static int sum(int... arr){//表示可以传入任意个int类型的参数 int sum=0; for (int i : arr) { sum+=i; } return sum; } } Set集合的特点: 无序:存储和取出是没有顺序的; 无索引; 不可重复:集合中的元素不可以重复,保证集合中的元素的唯一性; HashSet存储自定义对象: HashSet保证元素唯一是通过, **hashCode()和equals()方法**. HashSet存储自定义对象时, 如果要保证元素的唯一, 需要重写hashCode()和equals()方法.(alt + insert); LinkedHashSet: 可以保证元素的唯一性; 可以保证有序, 怎么存就怎么取; TreeSet的使用: 可以保证元素的唯一性; 可以对集合中的元素进行自然排序;