参考书
《TensorFlow:实战Google深度学习框架》(第2版)
例子:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出y = x^2 的值。
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test1.py @time: 2019/2/10 10:52 @desc: 例子:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出y = x^2 的值。 """ import tensorflow as tf # 从一个数组创建数据集。 input_data = [1, 2, 3, 5, 8] dataset = tf.data.Dataset.from_tensor_slices(input_data) # 定义一个迭代器用于遍历数据集。因为上面定义的数据集没有用placeholder作为输入参数 # 所以这里可以使用最简单的one_shot_iterator iterator = dataset.make_one_shot_iterator() # get_next() 返回代表一个输入数据的张量,类似于队列的dequeue()。 x = iterator.get_next() y = x * x with tf.Session() as sess: for i in range(len(input_data)): print(sess.run(y))
运行结果:
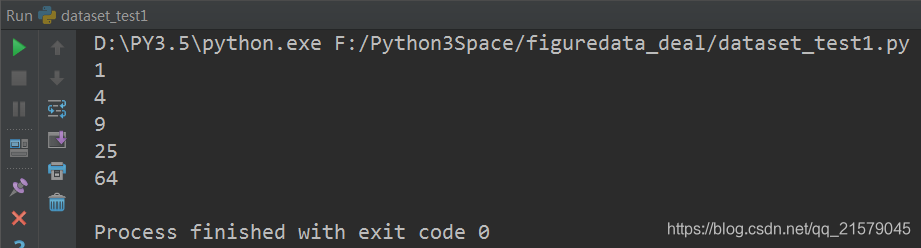
![]()
数据是文本文件:创建数据集。
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test2.py @time: 2019/2/10 11:03 @desc: 数据是文本文件 """ import tensorflow as tf # 从文本文件创建数据集。假定每行文字是一个训练例子。注意这里可以提供多个文件。 input_files = ['./input_file11', './input_file22'] dataset = tf.data.TextLineDataset(input_files) # 定义迭代器用于遍历数据集 iterator = dataset.make_one_shot_iterator() # 这里get_next()返回一个字符串类型的张量,代表文件中的一行。 x = iterator.get_next() with tf.Session() as sess: for i in range(4): print(sess.run(x))
运行结果:
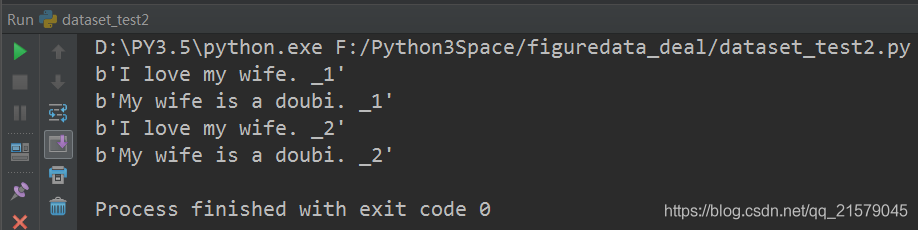
![]()
数据是TFRecord文件:创建TFRecord测试文件。
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_createdata.py @time: 2019/2/10 13:59 @desc: 创建样例文件 """ import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import numpy as np import time # 生成整数型的属性。 def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 生成字符串型的属性。 def _bytes_feature(value): return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) a = [11, 21, 31, 41, 51] b = [22, 33, 44, 55, 66] # 输出TFRecord文件的地址 filename = './input_file2' # 创建一个writer来写TFRecord文件 writer = tf.python_io.TFRecordWriter(filename) for index in range(len(a)): aa = a[index] bb = b[index] # 将一个样例转化为Example Protocol Buffer,并将所有的信息写入这个数据结构。 example = tf.train.Example(features=tf.train.Features(feature={ 'feat1': _int64_feature(aa), 'feat2': _int64_feature(bb) })) # 将一个Example写入TFRecord文件中。 writer.write(example.SerializeToString()) writer.close()
运行结果:
![]()
数据是TFRecord文件:创建数据集。(使用最简单的one_hot_iterator来遍历数据集)
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test3.py @time: 2019/2/10 13:16 @desc: 数据是TFRecord文件 """ import tensorflow as tf # 解析一个TFRecord的方法。record是从文件中读取的一个样例。前面介绍了如何解析TFRecord样例。 def parser(record): # 解析读入的一个样例 features = tf.parse_single_example( record, features={ 'feat1': tf.FixedLenFeature([], tf.int64), 'feat2': tf.FixedLenFeature([], tf.int64), } ) return features['feat1'], features['feat2'] # 从TFRecord文件创建数据集。 input_files = ['./input_file1', './input_file2'] dataset = tf.data.TFRecordDataset(input_files) # map()函数表示对数据集中的每一条数据进行调用相应方法。使用TFRecordDataset读出的是二进制的数据。 # 这里需要通过map()函数来调用parser()对二进制数据进行解析。类似的,map()函数也可以用来完成其他的数据预处理工作。 dataset = dataset.map(parser) # 定义遍历数据集的迭代器 iterator = dataset.make_one_shot_iterator() # feat1, feat2是parser()返回的一维int64型张量,可以作为输入用于进一步的计算。 feat1, feat2 = iterator.get_next() with tf.Session() as sess: for i in range(10): f1, f2 = sess.run([feat1, feat2]) print(f1, f2)
运行结果:
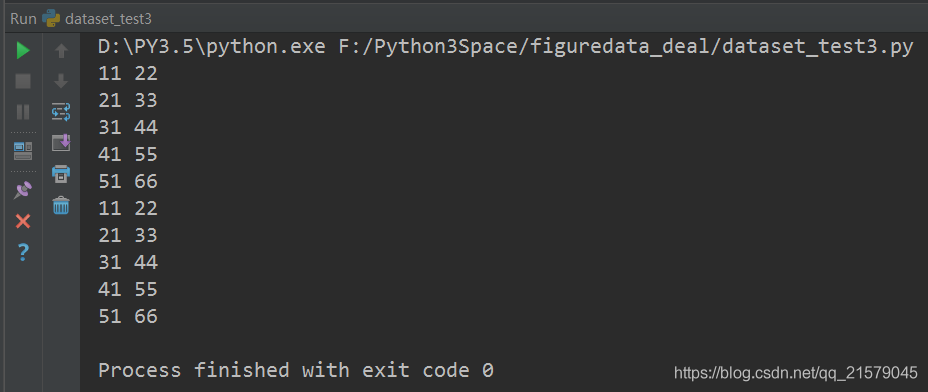
![]()
数据是TFRecord文件:创建数据集。(使用placeholder和initializable_iterator来动态初始化数据集)
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test4.py @time: 2019/2/10 13:44 @desc: 用initializable_iterator来动态初始化数据集的例子 """ import tensorflow as tf from figuredata_deal.dataset_test3 import parser # 解析一个TFRecord的方法。与上面的例子相同不再重复。 # 从TFRecord文件创建数据集,具体文件路径是一个placeholder,稍后再提供具体路径。 input_files = tf.placeholder(tf.string) dataset = tf.data.TFRecordDataset(input_files) dataset = dataset.map(parser) # 定义遍历dataset的initializable_iterator iterator = dataset.make_initializable_iterator() feat1, feat2 = iterator.get_next() with tf.Session() as sess: # 首先初始化iterator,并给出input_files的值。 sess.run(iterator.initializer, feed_dict={input_files: ['./input_file1', './input_file2']}) # 遍历所有数据一个epoch,当遍历结束时,程序会抛出OutOfRangeError while True: try: sess.run([feat1, feat2]) except tf.errors.OutOfRangeError: break
运行结果:
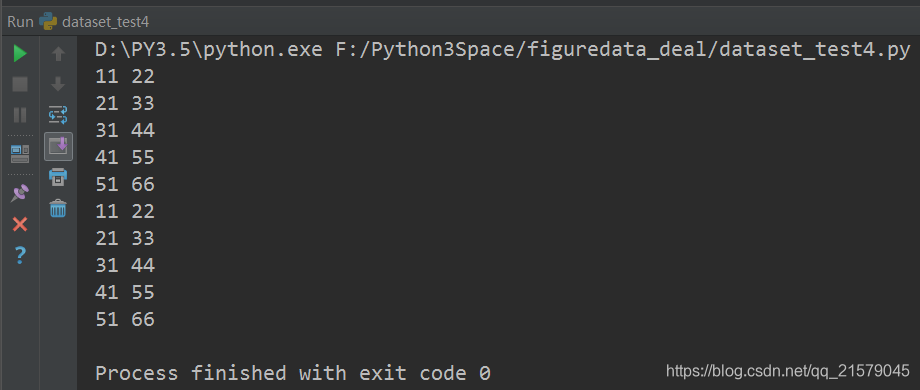
![]()