对鸢尾花识别之Keras
任务目标
- 对鸢尾花数据集分析
- 建立鸢尾花的模型
- 利用模型预测鸢尾花的类别
环境搭建
pycharm编辑器搭建python3.*
第三方库
- numpy
- pandas
- sklearn
- keras
处理鸢尾花数据集
了解数据集
鸢尾花数据集是一个经典的机器学习数据集,非常适合用来入门。
鸢尾花数据集链接:下载鸢尾花数据集
鸢尾花数据集包含四个特征和一个标签。这四个特征确定了单株鸢尾花的下列植物学特征:
- 花萼长度
- 花萼宽度
- 花瓣长度
- 花瓣宽度
该表确定了鸢尾花品种,品种必须是下列任意一种:
- 山鸢尾 Iris-Setosa(0)
- 杂色鸢尾 Iris-versicolor(1)
- 维吉尼亚鸢尾 Iris-virginica(2)
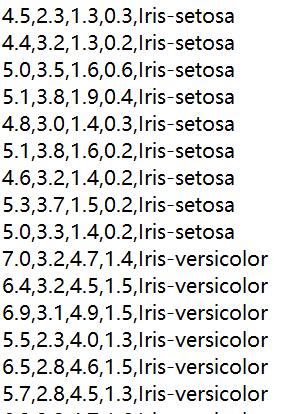
数据集中三类鸢尾花各含有50个样本,共150各样本
下面显示了数据集中的样本:
机器学习中,为了保证测试结果的准确性,一般会从数据集中抽取一部分数据专门留作测试,其余数据用于训练。所以我将数据集按7:3(训练集:测试集)的比例进行划分。
数据集处理具体代码
# 读取数据集
iris = pd.read_csv("iris.data", header=None)
# 数据集转化成数组
iris = np.array(iris)
# 提取特征集
X = iris[:, 0:4]
# 提取标签集
Y = iris[:, 4]
# One-Hot编码
encoder = LabelEncoder()
Y = encoder.fit_transform(Y)
Y = np_utils.to_categorical(Y)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
return x_train,x_test,y_train,y_test
什么是one-hot编码?
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
One-Hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
比如:["山鸢尾","杂色鸢尾","维吉尼亚鸢尾"]---->[[1,0,0][0,1,0][0,0,1]]
建立模型和预测
设置超参数
# 超参数
epochs = 500 # 循环次数
validation_split = 0.05 # 学习率
test_size = 0.25 # 拆分数据集大小
dense1_neurons = 512 # 第一层神经元的数量
dense2_neurons = 256 # 第二层神经元的数量
dense3_neurons = 128 # 第三层神经元的数量
搭建模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(units=dense1_neurons,input_dim = 4,activation = 'relu'))
model.add(tf.keras.layers.Dense(units=dense2_neurons,activation='relu'))
model.add(tf.keras.layers.Dense(units=dense3_neurons,activation='relu'))
model.add(tf.keras.layers.Dense(units=3,activation="softmax"))
model.summary() # 查看模型结构
编译模型
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
训练模型
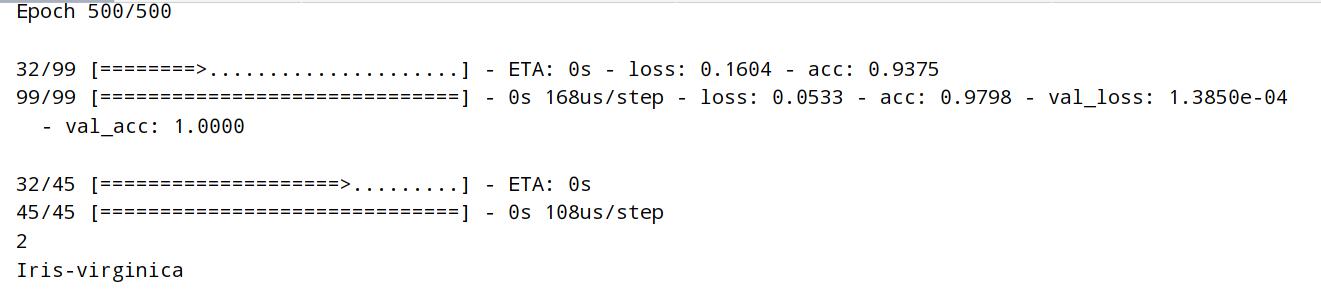
history = model.fit(x_train,y_train,validation_split=validation_split,epochs=epochs)
使用测试集进行评估
model.evaluate(x_test,y_test)
预测
target = model.predict(np.array([[7, 5.5, 6.5, 3.9]])).argmax()
print(target)
if target == 0:
print("Iris-setosa")
elif target == 1:
print("Iris-versicolor")
else:
print("Iris-virginica")