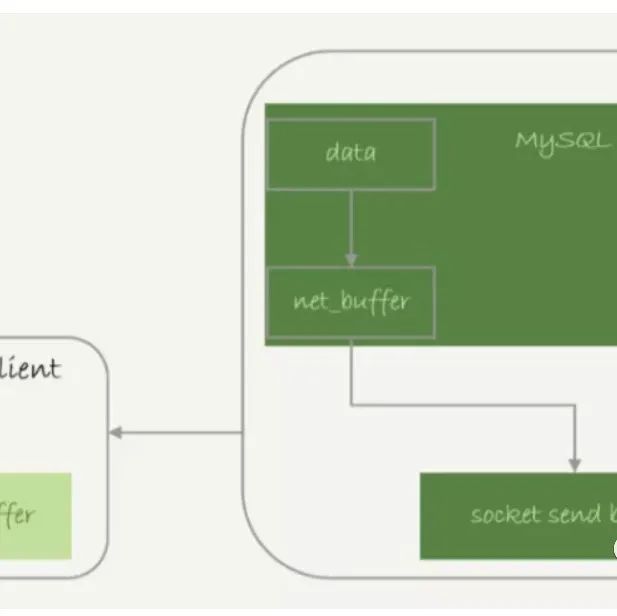
1.数据库链接过多的原因和解决方案
原因:
配置的 max_connections 数量太少,修改配置或者 set global max_connections=xxx 就行
sleep 的链接回收太慢,修改 wait_timeout 就行,调 小点加速回收
使用连接池
2.502 504错误的原因
502 是无效响应,(1)nginx 无法与 php-fpm 进行连接,检查 php-fpm 是否启动 ;(2) 脚 本执行超时,然后 php-fpm 终止了执行和worker进程,也可能是高并发情况下,超过 了最大子进程数量,与max_execution_time request_terminate_timeout max_children 这三个配置相关
504 是 php 脚本的执行时间超过了 nginx 的等待时间,可能由 502 升级成为 504,和 以下的 nginx 配置相关
fastcgi_connect_timeout 60;
fastcgi_read_timeout 300;
fastcgi_send_timeout 300;
3.从输入 url 到页面展现经历了哪些
DNS 解析:将域名解析成 IP 地址
TCP 连接:TCP 三次握手
发送 HTTP 请求
服务器处理请求并返回 HTTP 报文
浏览器解析渲染页面
断开连接:TCP 四次挥手
4.搜索解决方案
1 简单的直接 like 搜索就行,例如数量较小的表,在后台管理中的操作,也可以是 mysql 的全文搜索。
2 电商系列可以使用elastic search,结合 jieba 分词这样的工具,分词查找,按相关 性,热度排序,重点关注是怎样用户输入的词,然后再是搜索结果。曾经有系统是有独立进程从数据库读取数据,保存到elastic search,会有少许延迟,同 时每小时有脚本来校验数据同步的完整性。
5.性能调优方案:前端 - 后端 - 网络 分治解决。
基础的关注慢 sql,针对 sql 进行优化,没有高并发情况下,sql 一般是优化的入手 点
再是elk监控方案,给每个请求一个唯一的 request_id,监控响应慢的接口,对接口 可以打印sql,打印每个方法/调用的执行时间,找到慢的点,优化代码,使用缓存等手 段,提升这段代码的执行。
如果高并发的读,读频率搞的数据放到缓存中,当成热数据,提高查询响应
网络层面就是负载均衡,一些高耗时的统计类任务 ,拆到额外的机器执行,不要影响正式业务
让系统方便横向扩展,必要时加机器,加配置解决
网络方面风控,拦截恶意流量,避免给业务代理多余的压力
6.魔术方法
_call()当调用不存在的方法时会自动调用的方法
__autoload()在实例化一个尚未被定义的类是会自动调用次方法来加载类文件
__set()当给未定义的变量赋值时会自动调用的方法
__get()当获取未定义变量的值时会自动调用的方法
__construct()构造方法,实例化类时自动调用的方法
__destroy()销毁对象时自动调用的方法
__unset()当对一个未定义变量调用unset()时自动调用的方法
__isset()当对一个未定义变量调用isset()方法时自动调用的方法
__clone()克隆一个对象
__tostring()当输出一个对象时自动调用的方法7.数据库 MVCC 是怎样的
MVCC,Multi-Version Concurrency Control,多版本并发控制。MVCC 是一种并发 控制的方法,一般在数据库管理系统中,实现对数据库的并发访问;在编程语言中实现 事务内存。
MVCC 提供了时点(point in time)一致性视图。MVCC 并发控制下的读事务一般使 用时间戳或者事务 ID去标记当前读的数据库的状态(版本),读取这个版本的数据。读、写事务相互隔离,不需要加锁。读写并存的时候,写操作会根据目前数据库的状 态,创建一个新版本,并发的读则依旧访问旧版本的数据。
MVCC 就是 同一份数据临时保留多版本的一种方式,进而实现并发控制。
8.MVCC 在不同的隔离级别下的差别:
在事务隔离级别为RC和RR级别下, InnnoDB存储引擎使用的才是多版本并发控制。然 而,对于快照数据的定义却不相同。在RC事务隔离级别下,对于快照数据(undo端数 据),总是读取被锁定行的最新的一份快照数据。而在RR事务隔离级别下,对于快照数 据,多版本并发控制总是读取事务开始时的行数据。
9.Php 数组解决hash冲突
哈希表,顾名思义,即将不同的关键字映射到不同单元的一种数据结构。而将不同关键 字映射到不同单元的方法就叫做哈希函数,冲突解决方案:
链接法
即当不同的关键字映射到同一单元时,在同一单元内使用链表来保存这些关键字。
开放寻址法
即当插入数据时,如果发现关键字被映射到的单元存在数据了,说明发生了冲突,就继 续寻找下一个单元,直到找到可用单元为止。而因为开放寻址法方案属于占用其他关键字映射单元的位置,所以后续的关键字更容易 出现哈希冲突,因此容易出现性能下降。php解决哈希冲突的方式是使用了链接法,所以php数组是由哈希表+双向链表实现
10.Array_map 与 array_reduce ,array_walk, array_fliter 区别
array_reduce( $arr , callable $callback ) 使用回调函数迭代地将数组简化为单一的 值。
array_map(callback $callback , $arr) 返回用户自定义函数作用后的数组。回调函数接 受的参数数目应该和传递给 array_map() 函数的数组数目一致。此函数返回的是新数 组,可以同时处理多个数组
Array_walk 遍历处理,但不返回新数组,只改变现有的数组,walk 只可以处理一个数 组,
Array_filter 过滤掉输入数组中的元素,产生新数组
11.Redis 分布式锁
特性
互斥性: 同一时刻只能有一个线程持有锁
可重入性: 同一节点上的同一个线程如果获取了锁之后能够再次获取锁
锁超时:和J.U.C中的锁一样支持锁超时,防止死锁
高性能和高可用: 加锁和解锁需要高效,同时也需要保证高可用,防止分布式锁失效
具备阻塞和非阻塞性:能够及时从阻塞状态中被唤醒
使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 (正确做法)
Get key 获取锁, del key 删除锁
12.Redis 事务
命令 | 描述 |
MULTI | 标记一个事务块的开始 |
EXEC | 执行所有事务块内的命令 |
DISCARD | |
WATCH | 监视一个(或多个)key,如果在事务执行之前这个(或多个)key 被其他命令所改动,那么事务将被打断 |
UNWATC H | 取消 WATCH 命令对所有 keys 的监视 |
提交/放弃事务之后,会自动 unwatch,无需手动 unwatch
Redis 不支持事务回滚机制,某个命令出现了错误,不会影响前后的命令执行。
12.Laravel 注入原理
Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想。Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控 制。谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获 取(不只是对象包括比如文件等)。因为由容器帮我们查找及注入依赖对象,对象只是 被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。DI—Dependency Injection,即“依赖注入”:组件之间依赖关系由容器在运行期决 定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非 为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可 扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指 定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实 现。一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是 通过DI(Dependency Injection,依赖注入)来实现的。其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的 变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应 用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。所有类需要提起在容器中登记,在运行需要的时候在提供,所有类的创建销毁都由容器 控制。控制反转IoC(Inversion of Control)是说创建对象的控制权进行转移,以前创建 对象的主动权和创建时机是由自己把控的,而现在这种权力转移到第三方
laravel 容器包含控制反转和依赖注入(DI),使用起来就是,先把对象 bind 好,需要 时可以直接使用 make 来取就好。这种由外部负责其依赖需求的行为,我们可以称其 为 “控制反转(IoC)”依赖注入原理其实就是利用类方法反射,取得参数类型,然后利用容器构造好实例。然 后再使用回调函数调起。注入对象构造函数不能有参数,否则会报错。
容器是个超级工厂模式,真正的 IoC 容器会根据类的依赖需求,自动在注册、绑定的一 堆实例中搜寻符合的依赖需求,并自动注入到构造函数参数中去。自动搜寻依赖需求的 功能,是通过反射(Reflection)实现的,恰好的,php 完美的支持反射机制
13.反射是什么:
面向对象编程中对象被赋予了自省的能力,而这个自省的过程就是反射。反射,直观理解就是根据到达地找到出发地和来源。比如,一个光秃秃的对象,我们可 以仅仅通过这个对象就能知道它所属的类、拥有哪些方法。反射是指在PHP运行状态中,扩展分析PHP程序,导出或提出关于类、方法、属性、参 数等的详细信息,包括注释。这种动态获取信息以及动态调用对象方法的功能称为反射 API。在平常开发中,用到反射的地方不多:一个是对对象进行调试,另一个是获取类的信 息。在MVC和插件开发中,使用反射很常见,但是反射的消耗也很大,在可以找到替代 方案的情况下,就不要滥用。PHP有Token函数,可以通过这个机制实现一些反射功能。从简单灵活的角度讲,使用 已经提供的反射API是可取的。很多时候,善用反射能保持代码的优雅和简洁,但反射也会破坏类的封装性,因为反射 可以使本不应该暴露的方法或属性被强制暴露了出来,这既是优点也是缺点。
$student=new person();
$obj = new ReflectionClass('person');
$className = $obj->getName();
foreach($obj->getProperties() as $v)
{
$Properties[$v->getName()] = $v;
}
foreach($obj->getMethods() as $v)
{
$Methods[$v->getName()] = $v;
}14.Redis 哨兵机制
1)Sentinel(哨兵) 进程是用于监控 Redis 集群中 Master 主服务器工作的状态
2)在 Master 主服务器发生故障的时候,可以实现 Master 和 Slave 服务器的切换,保 证系统的高可用(High Availability)
15.监控(Monitoring):
1)哨兵(sentinel) 会不断地检查你的 Master 和 Slave 是否运作正常。
2)提醒(Notification):当被监控的某个Redis节点出现问题时, 哨兵(sentinel) 可以通 过 API 向管理员或者其他应用程序发送通知。(使用较少)
3)自动故障迁移(Automatic failover):当一个 Master 不能正常工作时,哨兵 (sentinel) 会开始一次自动故障迁移操作。
具体操作如下:
(1)它会将失效 Master 的其中一个 Slave 升级为新的 Master, 并让失效 Master 的 其他Slave 改为复制新的 Master。
(2)当客户端试图连接失效的 Master 时,集群也会向客户端返回新 Master 的地址, 使得集群可以使用现在的 Master 替换失效 Master。
(3)Master 和 Slave 服务器切换后,Master 的 redis.conf、Slave 的 redis.conf 和 sentinel.conf 的配置文件的内容都会发生相应的改变,即 Master 主服务器的 redis.conf 配置文件中会多一行 slaveof 的配置,sentinel.conf 的监控目标会随之调 换。
16.B+ 树的优点
1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更 少所以查询数据更快;
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的 次数都相同所以查询速度要比B树更稳定;
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需 要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比 B+ 树快