第一次作业
实现多项式的加减运算,主要问题是解决输入格式的判断问题。
输入实例:
{(3,0), (2,2), (12,3)} + {(3,1), (-5,3)} – {(-199,2), (29,3),(10,7)}
{}表示多项式,其中的小括号第一个参数是系数,第二个是指数。同一个多项式指数要求不同。
程序实现的重点总结
1.去除空白字符
s = s.replaceAll("\s*", "");
2.初步判断合法性(有有效输入字符且没有中文)

Pattern p = Pattern.compile("[u4e00-u9fa5]+"); //匹配中文字符
Matcher m = p.matcher(s);
if (s.trim().isEmpty()) { //判断是不是空串,或者字符串只由空白字符组成。trim方法去除字符串前后的空白字符
System.out.println("ERROR");
System.out.println("#The string is empty!");
}
else if(m.find()){
System.out.println("ERROR");
System.out.println("#The string has Chinese character!");
}
3.多项式格式检查
public static boolean CheckSyntax(String s){
String str;
if(s.charAt(0) != '-' && s.charAt(0) != '+'){
str = '+' + s;
}
else{
str = s;
} //如果第一个多项式前面没有符号,添加+,以方便匹配
Pattern p1 = Pattern.compile("([+-]\{[^\}]+}){0,20}");
Matcher m1 = p1.matcher(str);
boolean flag = m1.matches(); //先进行整体检查(逻辑清晰,且不会爆栈),匹配整体是否为+{...}-{...}格式,match方法要完全匹配才返回true
if(flag){
Pattern p2 = Pattern.compile("(\{[^\}]+})");
Matcher m2 = p2.matcher(str); //外部多项式大括号匹配成功,再进一步看大括号里面的是否符合格式
Pattern p3 = Pattern.compile("\{\([+-]?\d{1,6},([+]?\d{1,6}|-0{1,6})\)(,\([+-]?\d{1,6},([+]?\d{1,6}|-0{1,6})\)){0,49}\}");
while(m2.find()){ //匹配大括号里面的(c, n),(c,n)...
Matcher m3 = p3.matcher(m2.group(1));
if(m3.matches() == false){
return false;
}
}
return true;
}
else{
return false;
}
}
注意:
正则表达式的具体含义请参考后面的博客
不支持空多项式,{}会被报错。
3.字符串中数字的提取以及符号的提取
因为前面已经做过格式检查,如果格式是对的,只要非贪婪式匹配(...,就能提取系数,匹配,...)就能提取指数。(?表示非贪婪匹配)
同理,匹配{前面的字符就能得到运算符。
正则表达式的提取数字过程如下:
Pattern p = Pattern.compile("(?<=\{)(.*?)(?=\})");
Matcher matcher = p.matcher(s);
while(matcher.find()){
list.add(matcher.group());
} //提取每个{}多项式里面的内容并放进list容器里面
Pattern p1 = Pattern.compile("(?<=\()([\+|\-]?[0-9]*?)(?=\,)");
Matcher m1 = p1.matcher(str); //匹配系数
Pattern p2 = Pattern.compile("(?<=\,)([\+|\-]?[0-9]*?)(?=\))");
Matcher m2 = p2.matcher(str); //匹配指数
将字符串转化为数字:
int c = Integer.parseInt(m1.group()); int d = Integer.parseInt(m2.group());
注意,当parseInt方法不能转化字符换为整数的时候会抛出异常,最好使用try+catch方法对异常进行捕捉,以方便debug和避免程序的crash。
附:异常处理
异常处理的具体方法见后面的博客总结。
try{
... ...
}catch(IOException e){
//处理IO异常的代码
}catch(NumberFormatException e){
//处理parseInt不能转换时的异常代码
}catch(StringIndexOutOfBoundsException e){
//处理数组越界的异常代码
}catch(Exception e) {
//总异常(父类)
}
正则表达式匹配运算符:
Pattern p = Pattern.compile("([\+|\-])(?=\{)");
Matcher matcher = p.matcher(str);
当然,也可以使用split方法提取,会更加简洁。
抽到的测试程序
第一次抽到同学的代码整体写的不错,除了正则表达式爆栈了有点小遗憾。里面有很多值得学习的地方。
1.程序的结束与退出
System.exit(0); //程序结束,相当于C语言的return 0;正常结束时程序exitcode == 0。
System是一个Java类,调用exit(0)方法终止虚拟机也就是退出你的Java程序,括号里面的是参数,进程结束的返回值。
2.正则表达式太长,在数据压力大的时候可能会爆栈
public void formatCheck() {//正则表达式匹配格式
String regex = "[+-]{0,1}\{{1}\({1}[+-]{0,1}[0-9]{1,6},{1}((\+{0,1}[0-9]{1,6})|(-{1}0{1,6}))\){1}(,{1}\({1}[+-]{0,1}[0-9]{1,6},{1}((\+{0,1}[0-9]{1,6})|(-{1}0{1,6}))\){1}){0,}\}{1}([+-]{1}\{{1}\({1}[+-]{0,1}[0-9]{1,6},{1}((\+{0,1}[0-9]{1,6})|(-{1}0{1,6}))\){1}(,{1}\({1}[+-]{0,1}[0-9]{1,6},{1}((\+{0,1}[0-9]{1,6})|(-{1}0{1,6}))\){1}){0,}\}{1}){0,}";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);
if(m.matches() == false && input.length() != 0) {
System.out.println("ERROR");
System.out.println("#输入格式错误");
System.exit(0);
}
}
类图与度量分析
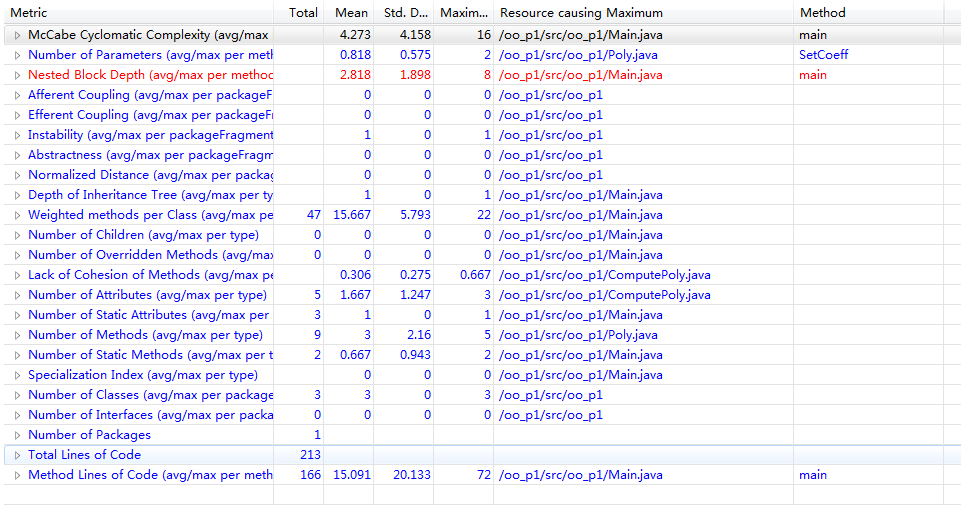
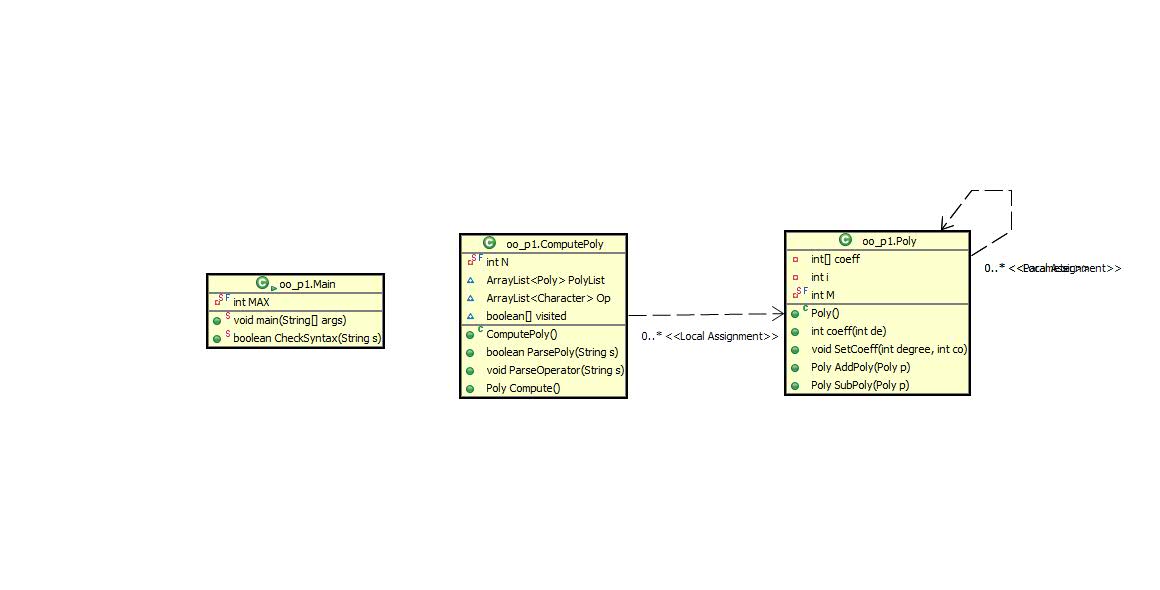
第一次作业还有很明显的面向过程思维,从main函数开始执行了大多数的功能。但是因为老师上课有讲解类功能的划分思路,类之间的联系还算明确、简洁。
第二次作业
本次作业的要求是单部可判断同质请求的电梯调度,算法复杂度不高,但是在一定程度上扭转了笔者面向过程编程的思维,总共有五个类,由楼层类、电梯类、请求类、请求队列类以及最重要的控制类构成。
程序实现的重点总结
总体规划:
笔者调整和协同这几个类的思路是,以控制类为全局控制与出发点,不断从请求队列中取出请求,根据控制类的算法计算出电梯的行为。因为本次作业的请求只有产生时间这一个优先级,而且输入的请求已经按照时间排序,所以只要从队列里逐个取出请求进行处理即可。写完代码之后,笔者发现了很多问题,比如并没有用上楼层类,楼层类变成了摆设。比如过度使用了调度器,调度类成为了核心,但是维护的事情过多,比如设置电梯的状态这一行为本来应该在电梯内部,由电梯独立完成,但笔者直接使用调度器设置了电梯的状态,这样就破坏了类的独立性与一致性,这是笔者应该改进的地方。在单元总结课上,吴际老师给出了设置楼层类的原因之一,因为在实际问题中,存在楼层维护的问题,那么就存在电梯是否可以根据请求到达该层的问题,这时楼层状态就起到了重要作用。
重点算法分析:
本次作业最核心的算法就是调度器的调度算法,难点是除去同质请求,关于同质请求的处理,笔者为请求类设置了available属性,available为true时表示该请求可执行,即没有被判断为同质请求。做完这些准备后,思考一下同质的本质,那就是,当一条指令执行的时候,在该条指令执行完成的时间点之前产的生所有与该条指令相同指令,都被认为在该执行的时间段内被完成,所以之前的指令都被认为是该条指令的同质请求。好了,这样就可以使用双层循环来完成同质请求的判断了。进一步思考一下,有什么可以优化的地方,使得判断变得更简洁。因为请求队列中的请求是按照时间排序的,那么被处理过的请求就没必要再被判断为同质请求了,判断同质的目的本来就是为了合并相同指令,少处理一些指令,那么就可以从当前指令开始,往后找在本条指令的执行时间范围内可以被判断为同质的请求,这样就大功告成了。
笔者在这次作业中的技巧收获是对数据范围有了进一步的认识。
附数据类型范围测试
一、数字常数的编译问题
java中的常量数字默认以int型编译
如:
long a = 1234567890; //十位 long b = 12345678900; //默认数据为int型,十一位超int范围,编译不过,在eclipse下数字有下划线提醒
如果用到的数超过int型,这里提供一下几种解决方法
1.整数后面加L或者l
long c = 12345678900L; //加L或者l表示以long编译
2.写成浮点数形式(double表示的范围更广)
在java中,直接写整数常数,被默认为int型,整数后面加L可以转化成long型。
直接写浮点常数,被默认为double型,整数后面加f可以转化成float型。
double e = 12345678900.0; //以double形式写数字常量,编译可过
二、unsigned int的处理方法
java没有unsigned int类型,笔者使用了移位的方法表示了无符号整型的最大值
private static final long UNSIGNED_INT_MAX = (1L << 32) - 1;
顺便一提,可以用这种方法定义常量字符,代替C语言的宏定义。
抽到的测试程序
第二次抽到的程序没有bug。
类图与度量分析

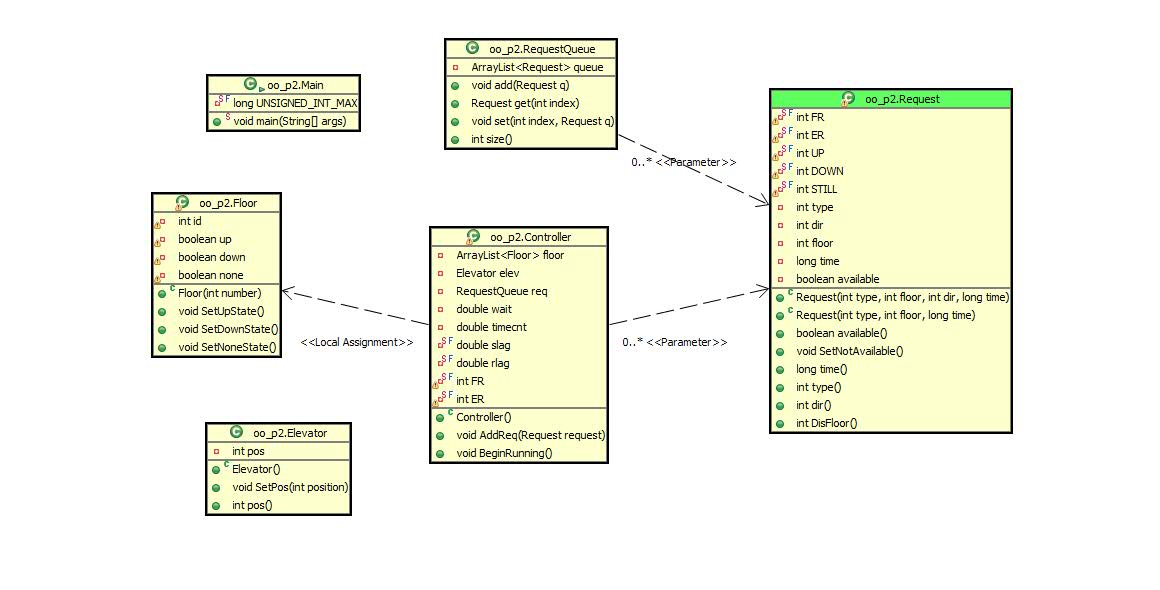
以controller作为整个程序的调度,取出队列中的请求并处理执行。从中可以看出类功能划分不均衡,controller控制的东西过多,应该把功能分给电梯类一些。
第三次作业:
程序实现的重点总结
第三次作业在第二次作业的基础之上增加了捎带的功能,这是一个看似简单但是需要很多逻辑边界的思考。笔者一开始觉得很晕,但是后来发现,解决一个让你觉得棘手问题最好的方法就是直面它,第一次写难免会有疏漏,但是算法就是在一步步精雕细琢中完善的。
从宏观来看,主请求是用来判断捎带的,但是实际执行优先级却要根据捎带队列来判断。而捎带队列中,“去往主请求过程中的捎带”和“超过主请求楼层的捎带”又是有本质区别的,前者的优先级相当于被直接提高,而后者的优先级仍在主请求之后。
进一步想,其实我们只需要一个指令执行队列,因为主请求本质上也是自己的捎带队列中的一员,而超过楼层的请求只取排序之后的第一个就ok(假设这个指令为q,在q之后的请求也会被q捕捉到,而超过楼层的指令实质上还没有执行,所以把q直接升级为主请求后清空队列是合理的,所以指导书样例的思路是正确的),用while循环执行到为空即可。
再进一步具体实现,为每条指令增加pick属性,表示是否执行过。扫描请求队列,找出捎带并设pick值,期间不断更新队列与同质请求判断。找完捎带队列后进行打印并提出新主请求即可。
思路清楚以后,最终笔者给继承的schedule类加了大概70-80行代码就解决了问题,虽然代码不多,写的也有点啰嗦,但小细节不知道被重写了多少次。本来以为已经比较严密了,测着测着又发现了很多漏洞,又不断回去改算法,也是很爆炸的体验了。
抽到的测试程序
笔者拿到的测试程序竟然是用状态机匹配的!激发了笔者的测试兴趣。本来以为状态机会比较冗长而且漏洞多,但是对方写的其实很精彩,确实吃了一惊。不过还是建议用正则表达式,不仅方便,而且容错性好。被我测的小哥哥就忘记了第一条指令的前导0和正号的匹配,可是他第一条特判明明是用正则写的啊,可能这就是大意失荆州吧(雾)。
还有一个很多人都会错的小错误,就是被执行时间相同的指令,要按照输入顺序排序。笔者觉得,扔进队列的时候本来就是有序的,发挥java库函数的优越性是很必要的。重写Comparator类就ok啦。
class SortByFloor implements Comparator { //楼层升序排列 public int compare(Object o1, Object o2) { Request s1 = (Request) o1; Request s2 = (Request) o2; if (s1.DisFloor() > s2.DisFloor()) { return 1; } else if(s1.DisFloor() < s2.DisFloor()) { return -1; } else { if(s1.time() > s2.time()) { return 1; } else if(s1.time() < s2.time()){ return -1; } else { return 0; } } } } class SortByFloorDown implements Comparator { //楼层降序 public int compare(Object o1, Object o2) { Request s1 = (Request) o1; Request s2 = (Request) o2; if (s1.DisFloor() < s2.DisFloor()) { return 1; } else if(s1.DisFloor() > s2.DisFloor()) { return -1; } else { if(s1.time() > s2.time()) { return 1; } else if(s1.time() < s2.time()) { return -1; } else { return 0; } } } }
这里千万记得不改顺序的时候要返回0!不改顺序的时候要返回0!不改顺序的时候要返回0!
调用语句如下:
Collections.sort(PrintQueue, new SortByFloor());
类图与度量分析
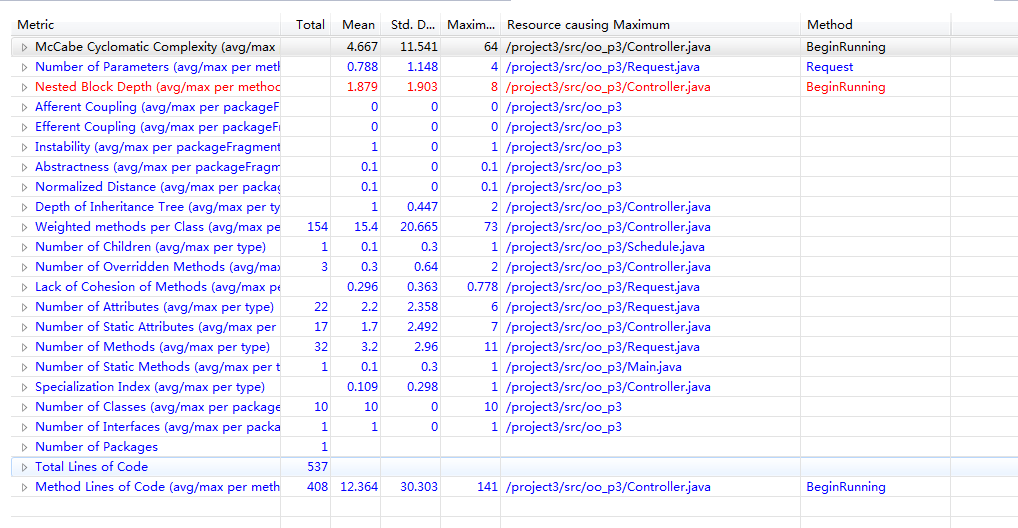
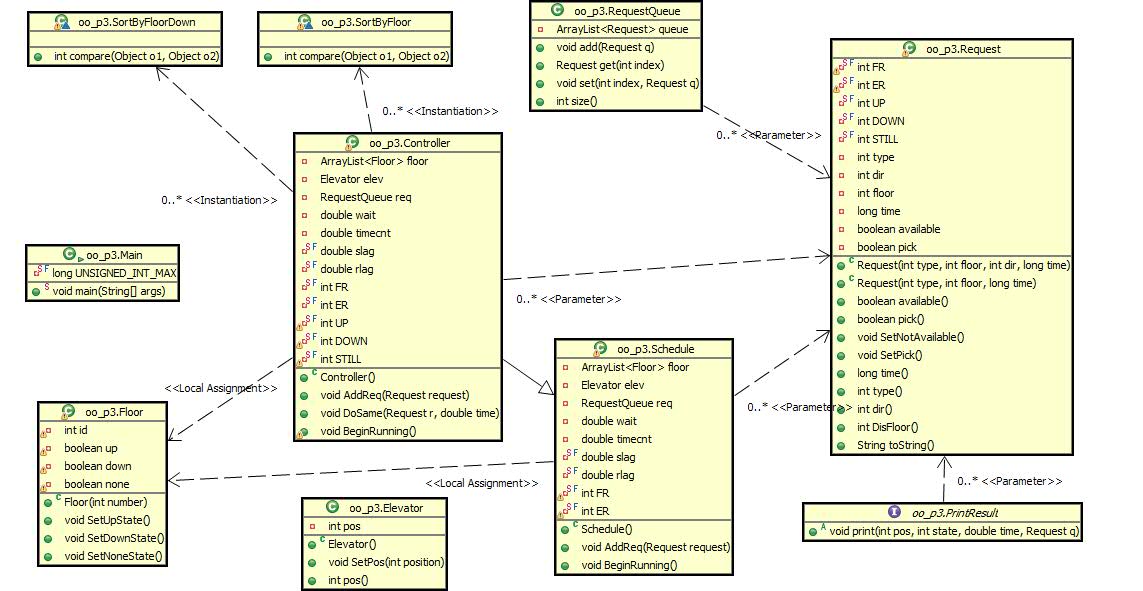
这次作业类之间的关系比较清晰明了,但是和第二次作业一样,没有很好的利用好电梯类,电梯类管理自己数据的能力还是比较弱,这样也导致controller背负了太多功能。下次写代码之前要进行好好的规划重整了。
自己程序的bug:
前两次作业没有bug,第三次作业因为调试时候误改了输出时间,导致公测错了十二个点,非常心痛,卡着时间交代码果然很容易出现各种问题,说明笔者真的应该好好治治拖延症了。
小结:
coding的过程让我想起了一个游戏叫《纪念碑谷》,它的第八章主题是《箱子》,箱子的表面看起来平淡无奇,但内部实际包含了各种机关,让你惊叹于里面构造的神奇与精妙,但当你理解了所有的机关玄妙之后,箱子又恢复成了最初平淡无奇的模样。笔者觉得一个类就是一个这样的箱子,负责信息交换的部分尽可能简洁,内部实现的功能尽可能集成,这样的一个“箱子”在使用过程中才会给人更好的体验。在debug的时候,或者是测试别人的程序时,笔者喜欢在应用拓展分支树的同时,将箱子的内部边界进行进一步测试,再辅以大数据集的测试,就很容易找到疏漏的部分。
还有,写程序的过程除了算法规划之外,更需要对布局、类的划分进行规划,才能保证程序以后的可扩展性,这种总体规划在实际工程中往往重于算法规划,而且需要逐步积累大量的经验,这是笔者应该不断学习之处。

