1. 应用K-means算法进行图片压缩
(1)读取一张图片(照片来源:微博@喵呜不停)

(2)观察图片文件大小,占内存大小,图片数据结构,线性化
1 from matplotlib import pyplot as plt 2 from sklearn.cluster import KMeans 3 import numpy as np 4 import matplotlib.image as img 5 6 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] 8 9 img1 = img.imread("./img/cat.jpg") 10 11 # 根据图片的分辨率,可适当降低分辨率 12 img2 = img1[::6, ::6] # 降低分辨率,训练时减短等待时间 13 X = img1.reshape(-1, 3) # 生成行数未知,列数为3 14 print(img1.shape, img2.shape, X.shape)
打印输出:

(3)压缩图片
· 构造函数方法:
1)用kmeans对图片像素颜色进行聚类
2)获取每个像素的颜色类别,每个类别的颜色
3)压缩图片生成:以聚类中收替代原像素颜色,还原为二维
1 # 构建模型 :用k均值聚类算法,将图片中所有的颜色值做聚类。 2 def cluster(x, n_colors): 3 model = KMeans(n_clusters=n_colors, n_init=10, max_iter=200) 4 model.fit(x) 5 labels = model.predict(x) # 每个像素颜色类别 6 colors = model.cluster_centers_ # 聚类中心,每个类别的颜色值 7 # img = colors[labels] 8 # 重塑图片:用聚类中心的颜色代替原来的颜色值,还原为二维。 9 new_img = colors[labels] 10 # new_img = img.astype(np.uint8) 11 return new_img
· 利用函数生成压缩图片
1 # 形成新的图片(8,32,64,128) 2 img_8 = cluster(X, 8).reshape(img1.shape).astype(np.uint8) 3 img_32 = cluster(X, 32).reshape(img1.shape).astype(np.uint8)
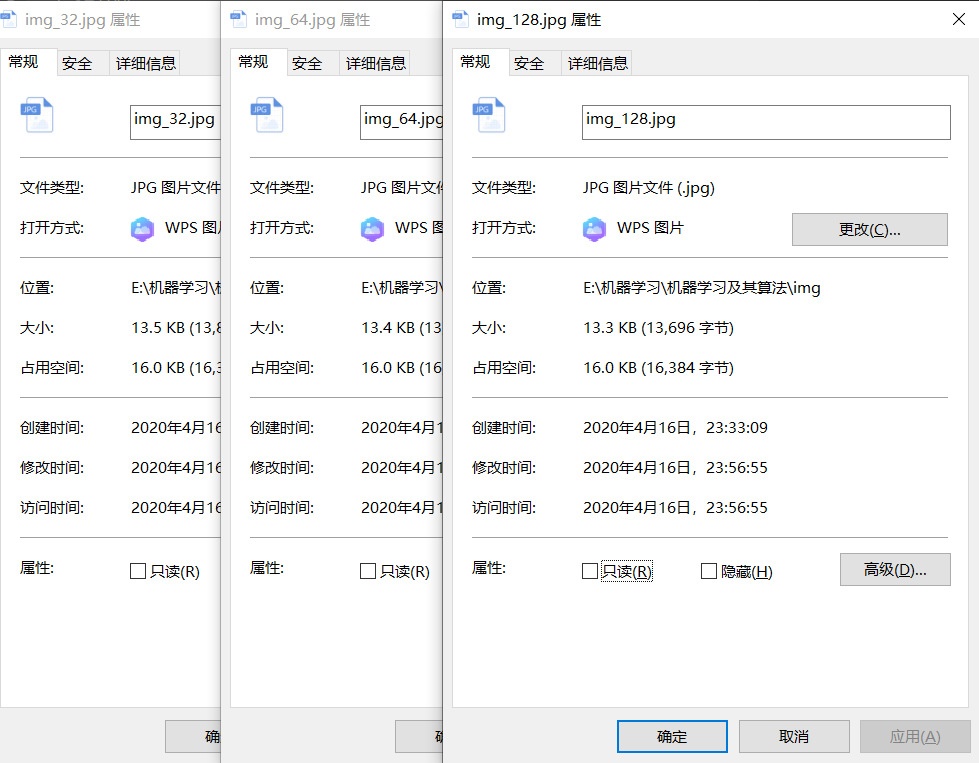
· 观察压缩图片的文件大小,占内存大小
1 # 观察原始图片与新图片。 2 plt.subplot(131) 3 plt.title("原图") 4 plt.imshow(img1) 5 6 plt.subplot(132) 7 plt.title("聚类32种颜色") 8 plt.imshow(img_32) 9 10 plt.subplot(133) 11 plt.title("聚类8种颜色") 12 plt.imshow(img_8) 13 plt.show()

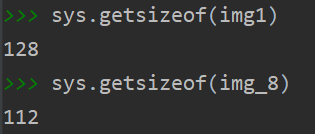
1 # 将原始图片与新图片保存成文件,观察文件的大小。 2 plt.imsave("./img/img1.jpg", img1) 3 plt.imsave("./img/img_8.jpg", img_8) 4 plt.imsave("./img/img_32.jpg", img_32) 5 import sys # 查看内存大小 6 7 sys.getsizeof(img1) 8 sys.getsizeof(img_8) 9 print("原图大小:" + img1.size + " 聚类8类图片大小:" + img_8.size)
运行结果:
· 对比按比例压缩和K-Means算法压缩
1 plt.subplot(131) 2 plt.title("原图") 3 plt.imshow(img1) 4 5 plt.subplot(132) 6 plt.title("聚类8种颜色") 7 plt.imshow(img_8) 8 plt.show() 9 10 plt.subplot(133) 11 plt.title("每隔6个像素点压缩") 12 plt.imshow(img2)

· 经过等比压缩后和K-Means算法联合压缩后图片的大小
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
· 分析某淘宝店铺的客户群体划分
以淘宝天池User Behavior Data on Taobao App作为源数据
1)数据处理:
筛选一个星期(2014-11-18至2014-11-24)客户成交订单(behavior_type=4)的数据量
删除无用列 用户所在地理位置、商品种类、用户行为
日期格式设置为 YY-MM-DD
1 import pandas as pd 2 import datetime 3 4 data = pd.read_csv("./data/user.csv", encoding="utf-8", low_memory=False) 5 data = data.drop("user_geohash", axis=1) # 删除用户地理位置 6 data = data.drop("item_id", axis=1) # 删除商品id 7 # data.keys() 8 data = data.dropna() 9 data = data.loc[data["behavior_type"] == 4] # 筛选用户已支付订单 10 data = data.drop("behavior_type", axis=1) # 删除用户操作类型 11 # 修改时间格式 12 data['time'] = data['time'].map(lambda x: x.split(" ")[0]) 13 data['time'] = data['time'].map(lambda x: datetime.datetime.strptime(x, '%Y-%m-%d')) 14 # 将商品的类别当成商品金额来处理(数据源没有订单金额,将就叭) 15 data.rename(columns={'item_category': 'item_money'}, inplace=True) 16 # 获取每个用户的消费总金额 17 df2 = data.groupby(by=['user_id'])['item_money'].sum() 18 data2 = pd.DataFrame({"user": df2.index, "count": df2}) 19 # 获取每个用户距离24号的最新一次消费的日间隔 20 df3 = datetime.datetime.strptime("2014-11-24", '%Y-%m-%d') - data.groupby(by=['user_id'])['time'].max() 21 df3 = df3.map(lambda x: x.days) 22 data3 = pd.DataFrame({"user": df3.index, "recent_consume": df3}) 23 data_rfm = pd.merge(data2, data3, how='left', on='user') 24 data_rfm.to_csv("./data/rfm.csv")
2)构建模型
1 from matplotlib import pyplot as plt 2 from sklearn.cluster import KMeans 3 import numpy as np 4 X = data_rfm.iloc[:, 1:] 5 est = KMeans(n_clusters=3) 6 est.fit(X)
3)预测数据
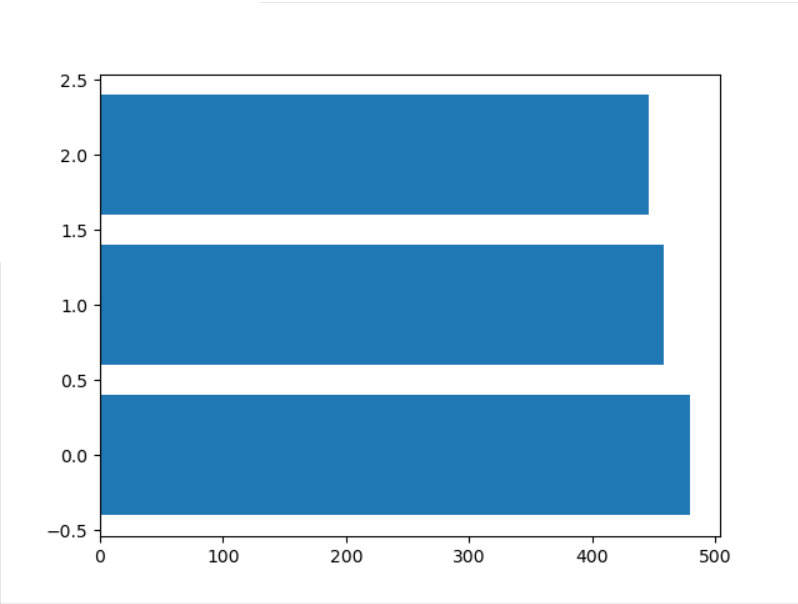
通过直方图可以直观的看出该店铺的活跃客户人数
1 y_means = est.predict(X) 2 level, number = np.unique(y_means,return_counts=True) 3 plt.barh(level, number) 4 plt.show()