1.Spark SQL 基本操作
创建DataFrame
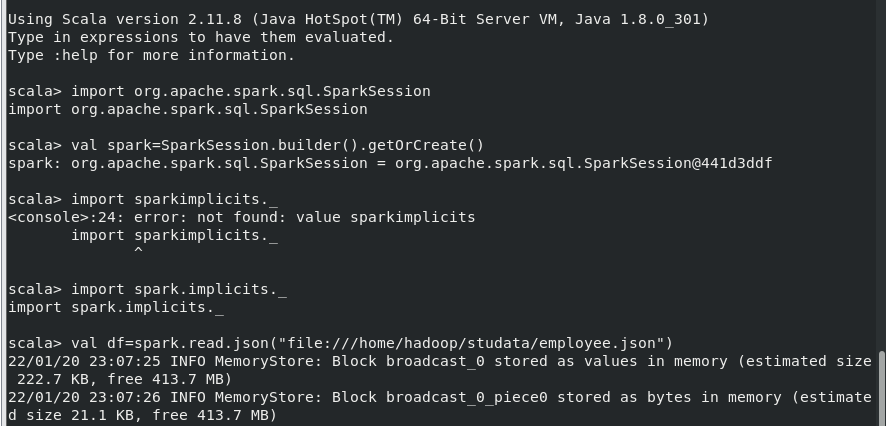
(1) 查询所有数据
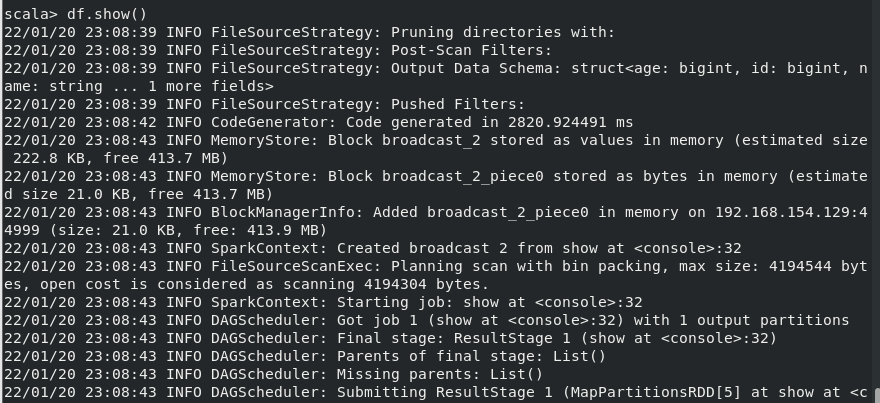
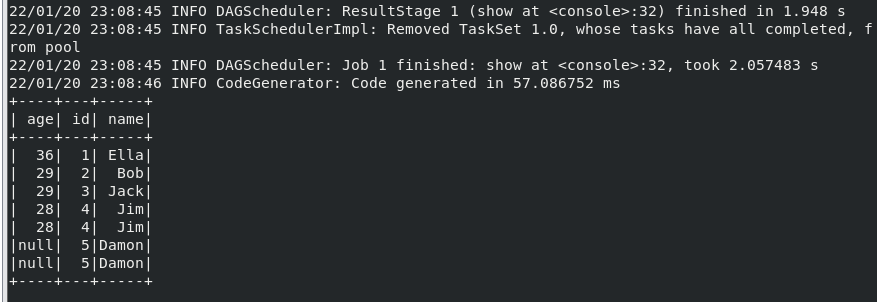
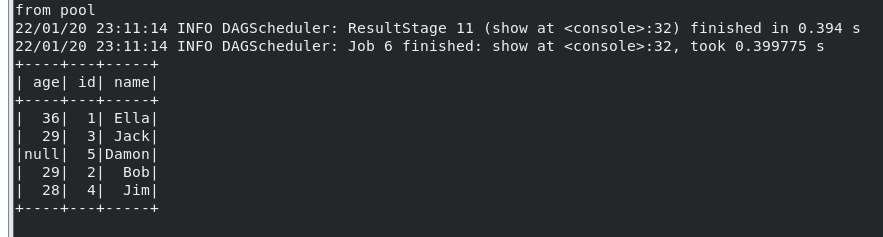
(2) 查询所有数据,并去除重复的数据;
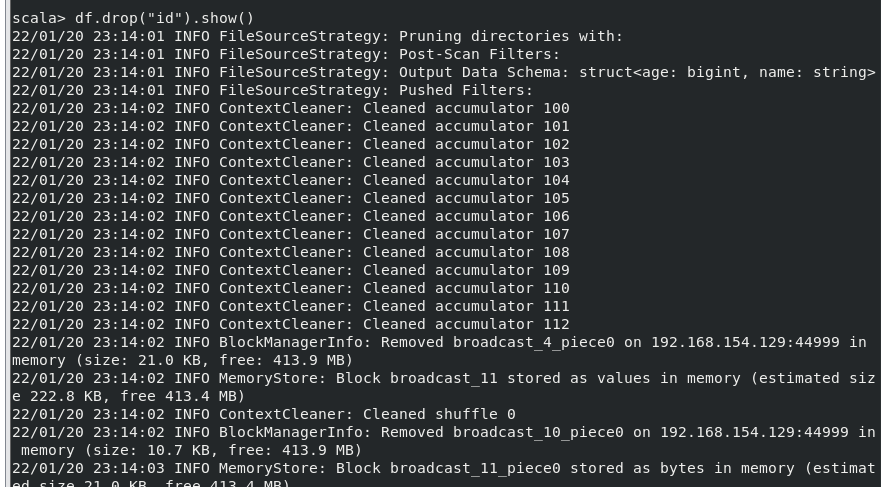
(3) 查询所有数据,打印时去除 id 字段;
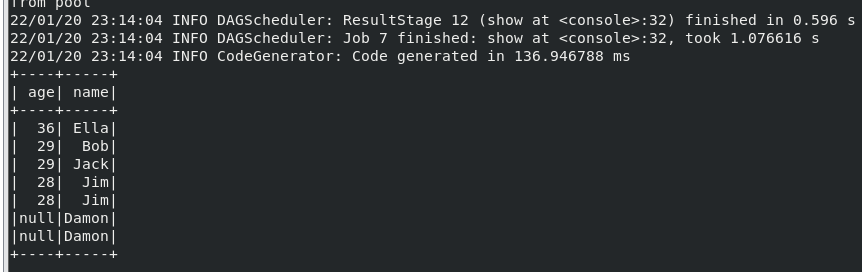
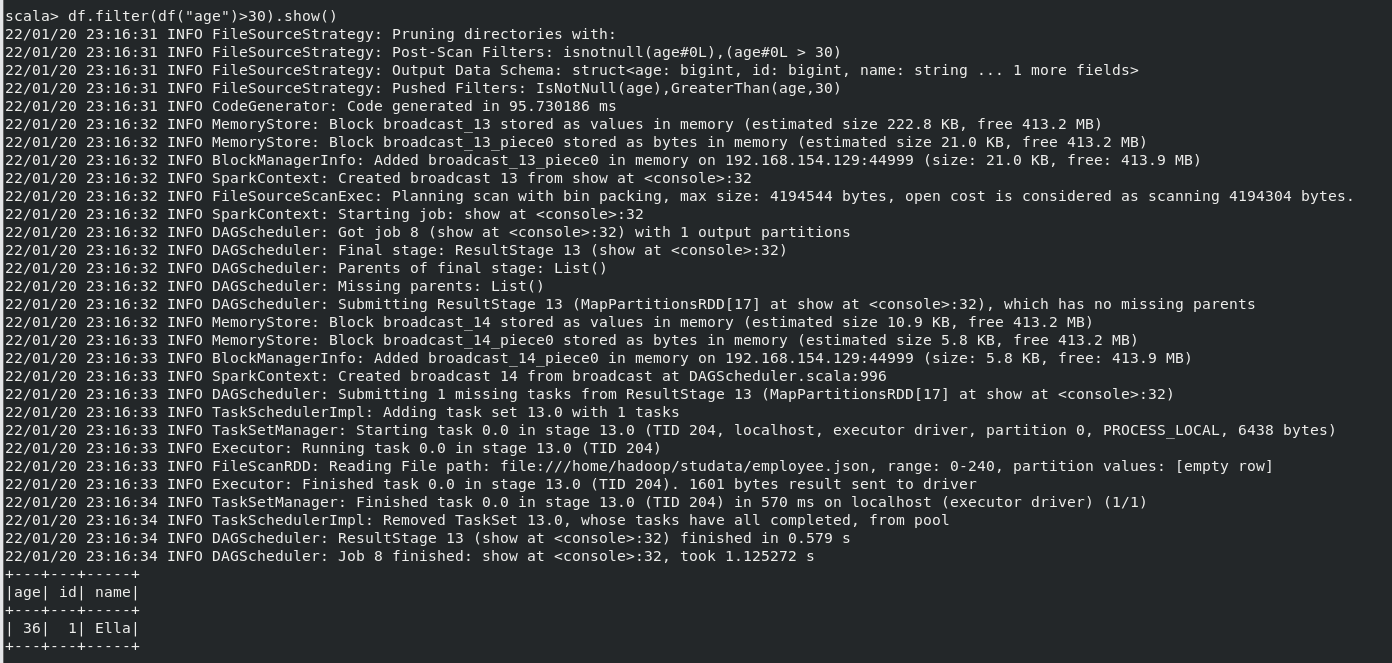
(4) 筛选出 age>30 的记录;
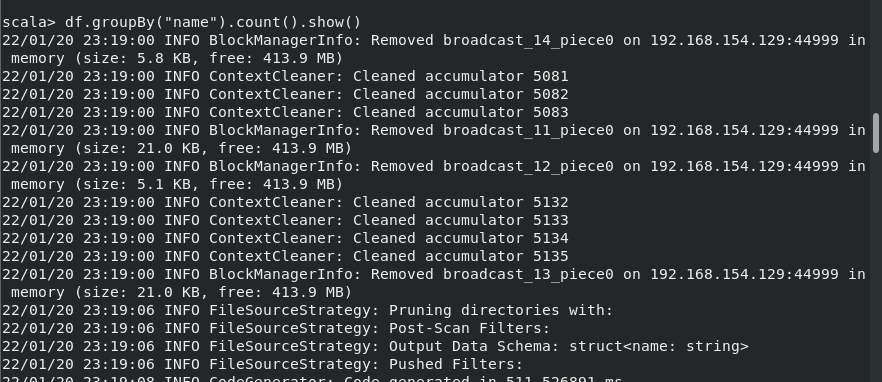
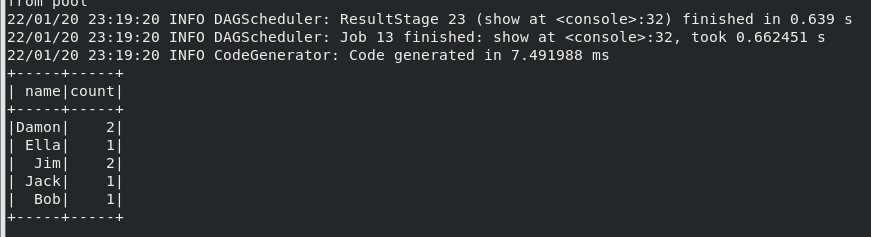
(5) 将数据按 age 分组;
(6) 将数据按 name 升序排列;
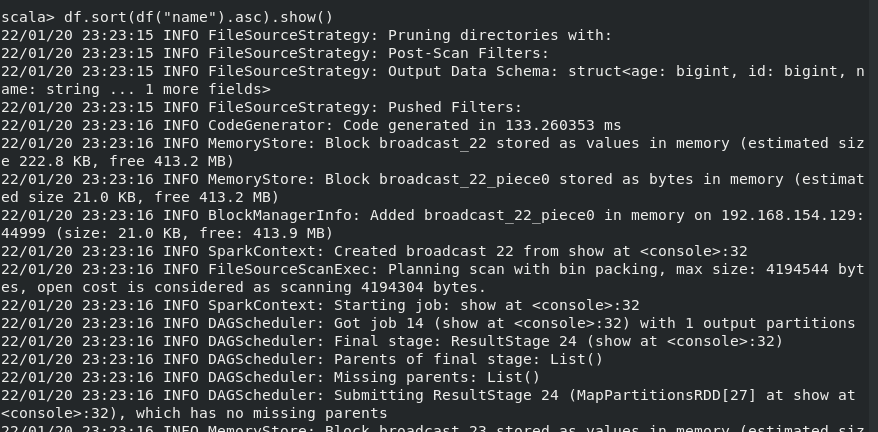
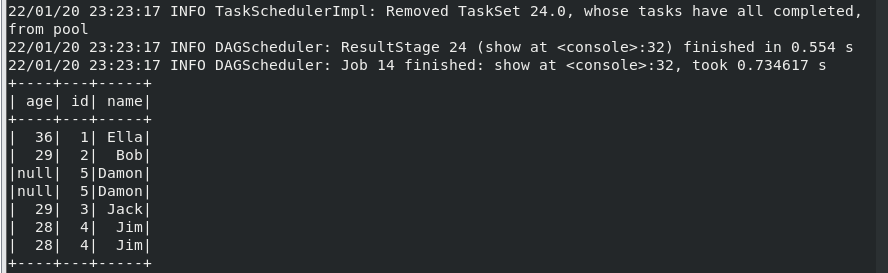
(7) 取出前 3 行数据;

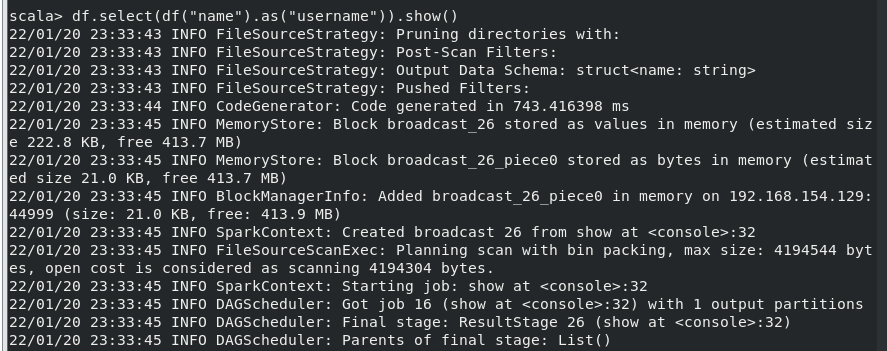
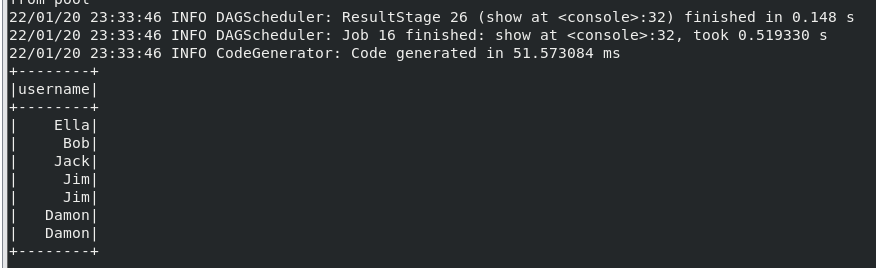
(8) 查询所有记录的 name 列,并为其取别名为 username;
(9) 查询年龄 age 的平均值;


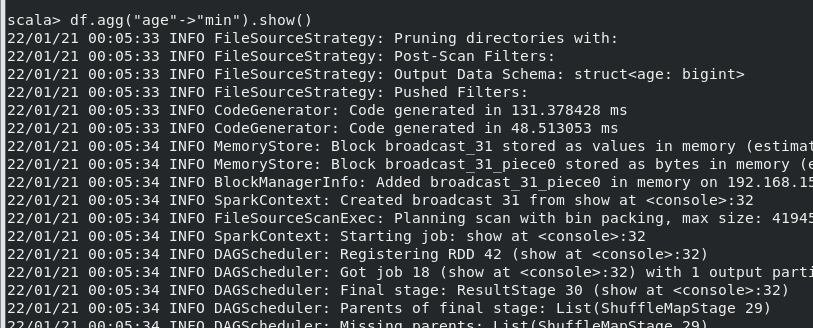
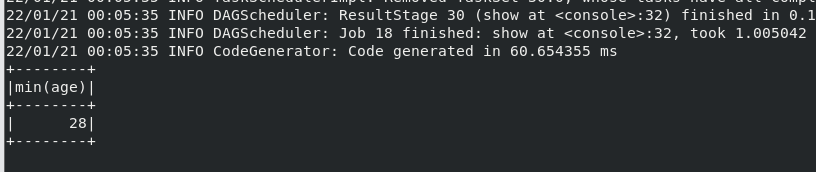
(10) 查询年龄 age 的最小值。
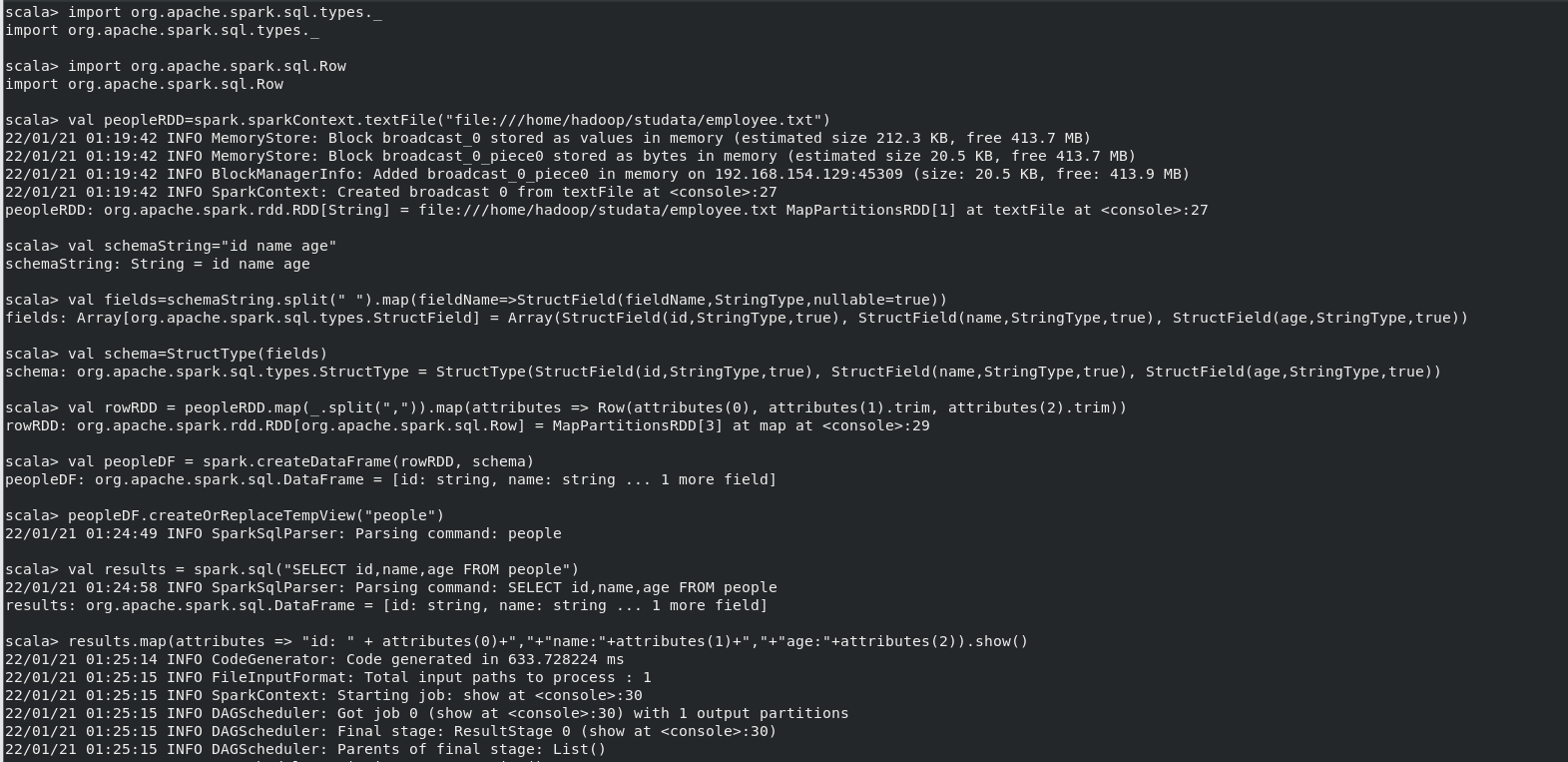
2.编程实现将 RDD 转换为 DataFrame
有关命令如下:
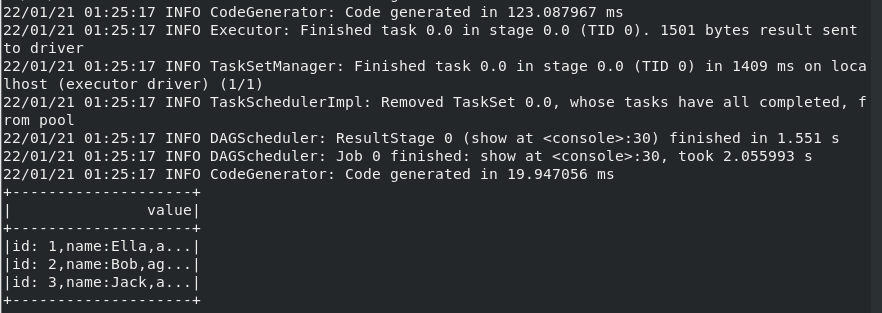
scala> import org.apache.spark.sql.types._ import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row import org.apache.spark.sql.Row scala> val peopleRDD=spark.sparkContext.textFile("file:///home/hadoop/studata/employee.txt") 22/01/21 01:19:42 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 212.3 KB, free 413.7 MB) 22/01/21 01:19:42 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 20.5 KB, free 413.7 MB) 22/01/21 01:19:42 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.129:45309 (size: 20.5 KB, free: 413.9 MB) 22/01/21 01:19:42 INFO SparkContext: Created broadcast 0 from textFile at <console>:27 peopleRDD: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/studata/employee.txt MapPartitionsRDD[1] at textFile at <console>:27 scala> val schemaString="id name age" schemaString: String = id name age scala> val fields=schemaString.split(" ").map(fieldName=>StructField(fieldName,StringType,nullable=true)) fields: Array[org.apache.spark.sql.types.StructField] = Array(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true)) scala> val schema=StructType(fields) schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true)) scala> val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim, attributes(2).trim)) rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[3] at map at <console>:29 scala> val peopleDF = spark.createDataFrame(rowRDD, schema) peopleDF: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field] scala> peopleDF.createOrReplaceTempView("people") 22/01/21 01:24:49 INFO SparkSqlParser: Parsing command: people scala> val results = spark.sql("SELECT id,name,age FROM people") 22/01/21 01:24:58 INFO SparkSqlParser: Parsing command: SELECT id,name,age FROM people results: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field] scala> results.map(attributes => "id: " + attributes(0)+","+"name:"+attributes(1)+","+"age:"+attributes(2)).show() 22/01/21 01:25:14 INFO CodeGenerator: Code generated in 633.728224 ms 22/01/21 01:25:15 INFO FileInputFormat: Total input paths to process : 1 22/01/21 01:25:15 INFO SparkContext: Starting job: show at <console>:30 22/01/21 01:25:15 INFO DAGScheduler: Got job 0 (show at <console>:30) with 1 output partitions 22/01/21 01:25:15 INFO DAGScheduler: Final stage: ResultStage 0 (show at <console>:30) 22/01/21 01:25:15 INFO DAGScheduler: Parents of final stage: List() 22/01/21 01:25:15 INFO DAGScheduler: Missing parents: List()
3. 编程实现利用 DataFrame 读写 MySQL 的数据
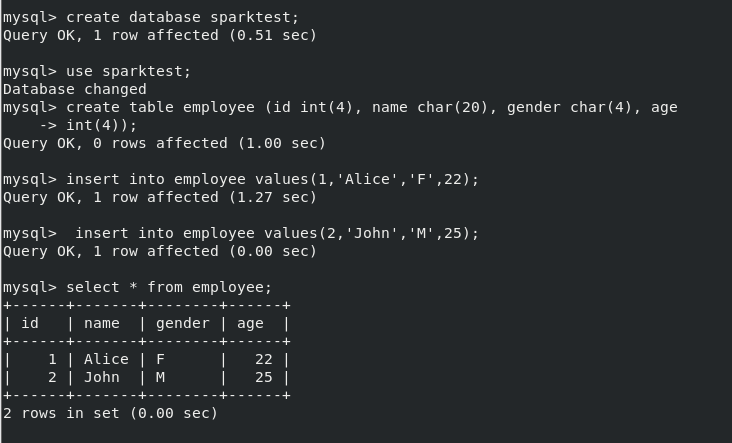
数据库建表:
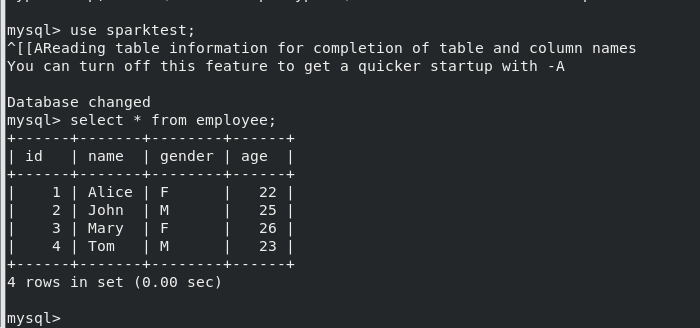
create database sparktest; use sparktest; create table employee(id int(4),name char(50), gender char(20), age int(10)); insert into employee values(1,'Alice','F',22); insert into employee values(2,'John','M',25); select * from employee;
启动spark
启动命令
spark-shell --jars /home/hadoop/stuzip/mysql-connector-java-5.1.46-bin.jar --driver-class-path /home/hadoop/stuzip/mysql-connector-java-5.1.46-bin.jar
运行程序
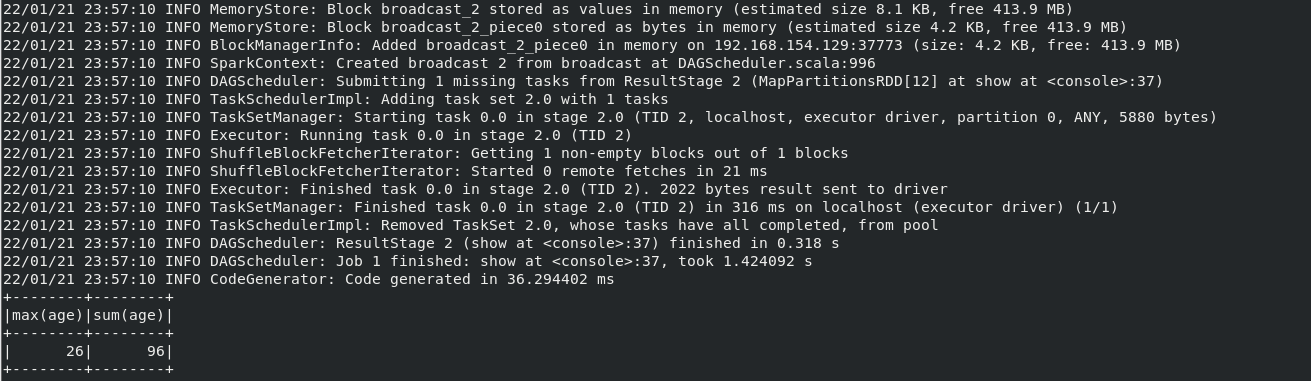
scala> import java.util.Properties import java.util.Properties scala> import org.apache.spark.sql.types._ import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row import org.apache.spark.sql.Row scala> import org.apache.spark.sql.SparkSession import org.apache.spark.sql.SparkSession scala> val spark=SparkSession.builder().appName("TestMySQL").master("local").getOrCreate() 22/01/21 23:49:42 WARN SparkSession$Builder: Using an existing SparkSession; some configuration may not take effect. spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@23eb6d13 scala> import spark.implicits._ import spark.implicits._ scala> val employeeRDD=spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" ")) employeeRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[1] at map at <console>:34 scala> val schema=StructType(List(StructField("id",IntegerType,true),StructField("name",StringType,true),StructField("gender",StringType,true),StructField("age",IntegerType,true))) schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,IntegerType,true), StructField(name,StringType,true), StructField(gender,StringType,true), StructField(age,IntegerType,true)) scala> val rowRDD=employeeRDD.map(p=>Row(p(0).toInt,p(1).trim,p(2).trim,p(3).toInt)) rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[2] at map at <console>:36 scala> val employeeDF=spark.createDataFrame(rowRDD,schema) employeeDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more fields] scala> val prop=new Properties() prop: java.util.Properties = {} scala> prop.put("user","root") res0: Object = null scala> prop.put("password",".Xuan0613") res1: Object = null scala> prop.put("driver","com.mysql.jdbc.Driver") res2: Object = null scala> employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest?characterEncoding=utf-8&useSSL=false", "sparktest.employee", prop) 22/01/21 23:55:05 INFO SparkContext: Starting job: jdbc at <console>:45 22/01/21 23:55:05 INFO DAGScheduler: Got job 0 (jdbc at <console>:45) with 1 output partitions 22/01/21 23:55:05 INFO DAGScheduler: Final stage: ResultStage 0 (jdbc at <console>:45) 22/01/21 23:55:05 INFO DAGScheduler: Parents of final stage: List() 22/01/21 23:55:05 INFO DAGScheduler: Missing parents: List() 22/01/21 23:55:05 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[6] at jdbc at <console>:45), which has no missing parents 22/01/21 23:55:06 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 11.3 KB, free 413.9 MB) 22/01/21 23:55:07 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 5.9 KB, free 413.9 MB) 22/01/21 23:55:07 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.129:37773 (size: 5.9 KB, free: 413.9 MB) 22/01/21 23:55:07 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:996 22/01/21 23:55:07 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[6] at jdbc at <console>:45) 22/01/21 23:55:07 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 22/01/21 23:55:08 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 6101 bytes) 22/01/21 23:55:08 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 22/01/21 23:55:08 INFO Executor: Fetching spark://192.168.154.129:40823/jars/mysql-connector-java-5.1.46-bin.jar with timestamp 1642779886941 22/01/21 23:55:09 INFO TransportClientFactory: Successfully created connection to /192.168.154.129:40823 after 76 ms (0 ms spent in bootstraps) 22/01/21 23:55:09 INFO Utils: Fetching spark://192.168.154.129:40823/jars/mysql-connector-java-5.1.46-bin.jar to /tmp/spark-e15d3973-bc69-4a13-9752-b12974ebfefb/userFiles-2281114d-1daf-43ea-9085-dd54276bb045/fetchFileTemp3424382579403996176.tmp 22/01/21 23:55:10 INFO Executor: Adding file:/tmp/spark-e15d3973-bc69-4a13-9752-b12974ebfefb/userFiles-2281114d-1daf-43ea-9085-dd54276bb045/mysql-connector-java-5.1.46-bin.jar to class loader 22/01/21 23:55:11 INFO CodeGenerator: Code generated in 572.440461 ms 22/01/21 23:55:11 INFO CodeGenerator: Code generated in 431.471957 ms 22/01/21 23:55:15 INFO CodeGenerator: Code generated in 602.088524 ms 22/01/21 23:55:16 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1297 bytes result sent to driver 22/01/21 23:55:16 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 8454 ms on localhost (executor driver) (1/1) 22/01/21 23:55:16 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 22/01/21 23:55:16 INFO DAGScheduler: ResultStage 0 (jdbc at <console>:45) finished in 8.589 s 22/01/21 23:55:16 INFO DAGScheduler: Job 0 finished: jdbc at <console>:45, took 11.096234 s scala> val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/sparktest?characterEncoding=utf-8&useSSL=false").option("driver","com.mysql.jdbc.Driver").option("dbtable", "employee").option("user", "root").option("password", ".Xuan0613").load() jdbcDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more fields] scala> jdbcDF.agg("age" -> "max", "age" -> "sum").show() 22/01/21 23:57:08 INFO CodeGenerator: Code generated in 338.804129 ms 22/01/21 23:57:08 INFO CodeGenerator: Code generated in 24.233598 ms 22/01/21 23:57:09 INFO SparkContext: Starting job: show at <console>:37 22/01/21 23:57:09 INFO DAGScheduler: Registering RDD 9 (show at <console>:37) 22/01/21 23:57:09 INFO DAGScheduler: Got job 1 (show at <console>:37) with 1 output partitions 22/01/21 23:57:09 INFO DAGScheduler: Final stage: ResultStage 2 (show at <console>:37) 22/01/21 23:57:09 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 1) 22/01/21 23:57:09 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 1)
运行结果: