主要内容
-
Topic & partition
-
消息分发策略
-
消息消费原理
-
消息的存储策略
-
partition副本机制
Topic & partition
topic 是存储消息的逻辑概念,每一条消息发送到kakfa集群上都会有一个类别,这个类别就是topic
partition
1、每个topic可以划分多个分区,每个分区的消息是往后追加,顺序递增写入
2、相同topic下的不同分区的消息是不同的
注意:
-
分区会有单点故障问题,所以我们会为每个分区设置副本数
-
分区的编号是从0开始的。
sh kafka-topics.sh --create --zookeeper 192.168.1.103:2181 --replication-factor=1 --partitions 2 --topic sansan

消息分发
【key】->value
自定义分发策略


1 package com.learn.kafka; 2 3 import org.apache.kafka.clients.producer.Partitioner; 4 import org.apache.kafka.common.Cluster; 5 import org.apache.kafka.common.PartitionInfo; 6 7 import java.util.List; 8 import java.util.Map; 9 import java.util.Random; 10 /** 11 * 自定义分发策略 12 */ 13 public class MyPartition implements Partitioner { 14 15 private Random random = new Random(); 16 17 @Override 18 public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { 19 // 获取所有topic 分区 20 List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); 21 int partitionNum = 0; 22 23 if (null == key) { 24 // 随机分区 25 partitionNum = random.nextInt(partitions.size()); 26 } else { 27 partitionNum = Math.abs((key.hashCode() % partitions.size())); 28 } 29 System.out.println("key ->" + key + "->value->" + value + "->" + partitionNum); 30 return partitionNum; // 指定发送的 分区值 31 } 32 33 @Override 34 public void close() { 35 36 } 37 38 @Override 39 public void configure(Map<String, ?> configs) { 40 41 } 42 }
同时在初始化kafka生产者时,增加自定义配置
// 设置key序列化 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerSerializer"); properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.learn.kafka.MyPartition"); producer = new KafkaProducer<Integer, String>(properties);
metadata.max.age.ms 10 分钟更新一次
消息消费
增减consumer、broker、partition会导致Rebalance
分区分配策略
Kafka消费者组三种分区分配策略roundrobin,range,StickyAssignor
Range(范围分区) ->默认
Range是对每个Topic而言的(即一个Topic一个Topic分),首先对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。然后用Partitions分区的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。
假设n=分区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的(消费者数量-m)个消费者每个分配n个分区。
假如有10个分区,3个消费者线程,把分区按照序号排列0,1,2,3,4,5,6,7,8,9;消费者线程为C1-0,C2-0,C2-1,那么用partition数除以消费者线程的总数来决定每个消费者线程消费几个partition,如果除不尽,前面几个消费者将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程,10/3 = 3,而且除除不尽,那么消费者线程C1-0将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
C1-0:0,1,2,3 C2-0:4,5,6 C2-1:7,8,9
如果有11个分区将会是:
C1-0:0,1,2,3 C2-0:4,5,6,7 C2-1:8,9,10
RounBobin (轮询)
将所有的partition,和consumer 的数量都列出来,然后按照hashCode 排序,在轮询
什么时候触发rebalance(策略)
1、对于consumer group新增消费者的时候,会触发Rebalance
2、消费者离开consumer group
3、topic中新增了分区
4、消费者主动取消订阅 topic
partition.assignment.strategy
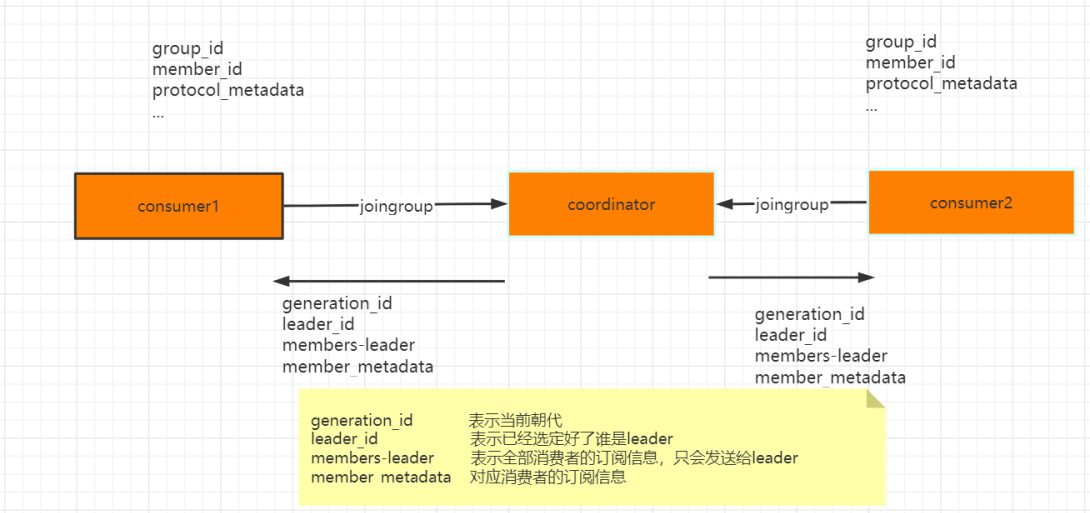
怎么确定Coordinator ->GroupCoordinatorRequest 返回负载最小的broker节点的id
joingroup
1、从consumer group中选举一个consumer担任leader角色
2、分配分区策略
offset 在哪里维护?对于每个分区offset是唯一的
__consumer_offsets(topic)默认50个分区, 用来保存消费者消费的位置
("KafkaConsumerDemo2".hashCode())%50 找到当前的consumer group的offset维护在哪个分区中
消息的存储
sh kafka-console-consumer.sh --topic __consumer_offsets --partition 5 --bootstrap-server 192.168.1.101:9092,192.168.1.111:9092 --formatter "kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter"
消息的保存路径
->topic (逻辑)
->partition

顺序写入
操作系统每次从磁盘读写数据的时候,需要先寻址,也就是先要找到数据在磁盘上的物理位置,然后再进行数据的读写,如果是机械硬盘,寻址就需要较长的时间。kafka的设计中,数据其实是存储在磁盘上面,一般来说,会把数据存储在内存上面性能才会。但是kafka用的是顺写,追加数据是追加到末尾,磁盘顺序写的性能极高,在磁盘个数一定,转数达到一定的情况下,基本和内存速度一致随机写的话是在文件的某个位置修改数据,性能会较低
零拷贝(IO瓶颈)
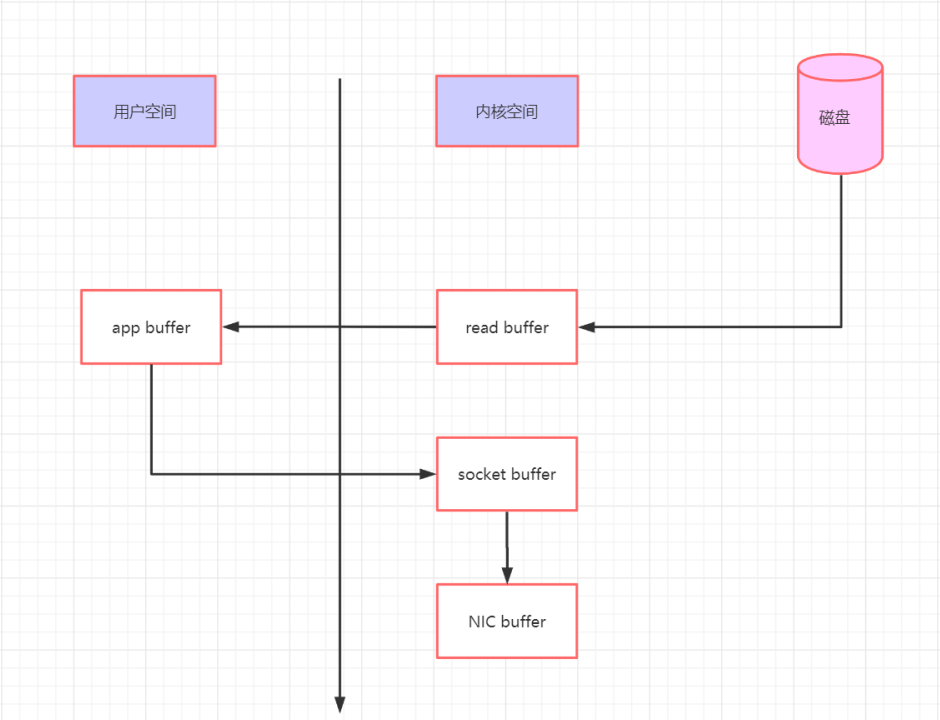
传统的文件读写
传统的文件读写或者网络传输,通常需要将数据从内核态转换为用户态。应用程序读取用户态内存数据,写入文件 / Socket之前,需要从用户态转换为内核态之后才可以写入文件或者网卡当中。
数据首先从磁盘读取到内核缓冲区,这里面的内核缓冲区就是页缓存(PageCache)。然后从内核缓冲区中复制到应用程序缓冲区(用户态),输出到输出设备时,又会将用户态数据转换为内核态数据。
零拷贝
对于常见的零拷贝,下面的介绍我们基于磁盘文件拷贝的方式去讲解。
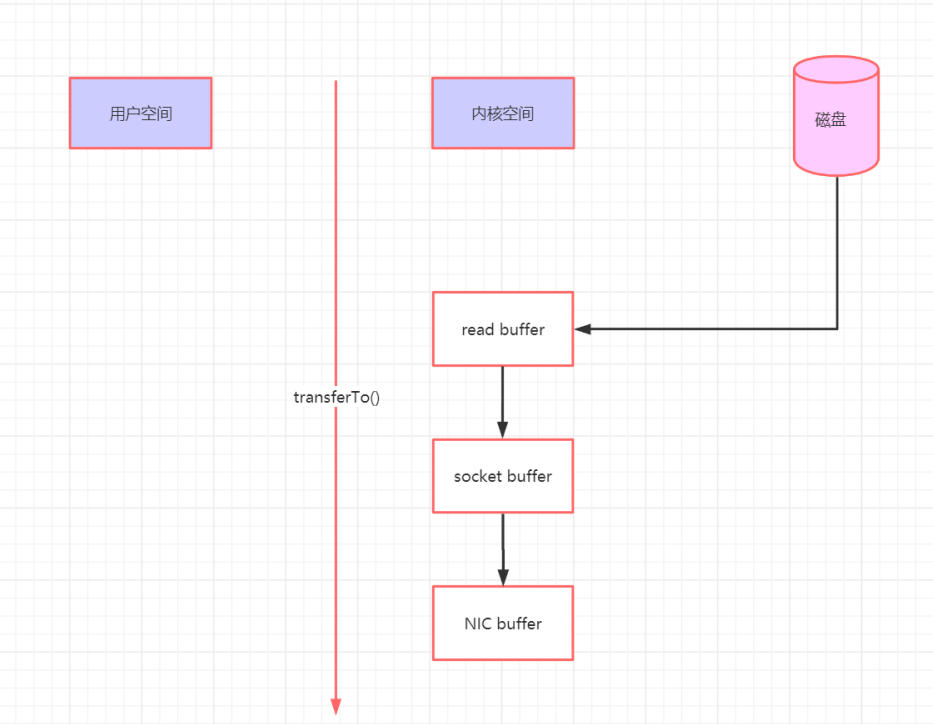
可以看到数据的拷贝从内存拷贝到kafka服务进程那块,又拷贝到socket缓存,整个过程耗费的时间比较高,kafka利用了Linux和sendfile技术(NIO),省去了进程切换和一次数据拷贝,让性能变得更好。
logSegment日志分段
index -> log index 对应log ,这个两是完全匹配的,index 是索引,而log是消息内容
index -> log
通过以下命令可以查看日志内容
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /temp/kafka-logs/test-lisa-0/00000000000000000000.log --print-data-log