本文基于Python软件进行评分卡的制作及使用预测。主要包括确定观察时间窗口、确定表现时间窗口、评分卡的制作、新数据的预测四大部分。内容涉及数据清洗、变量筛选、生成WOE 矩阵、IV值计算、ROC曲线、模型建立、模型评估预测等。
- 数据来源
本项目数据来源于kaggle竞赛Give Me Some Credit。
- 流程如下
1.确定观察时间窗口
- CID:用户ID
- STAGE_BEF:本阶段前的逾期阶段
- STAGE_AFT:本阶段进入的逾期阶段
- CLOSE_DATE:本阶段结束时间
1.1导包
1.2读取数据及描述统计

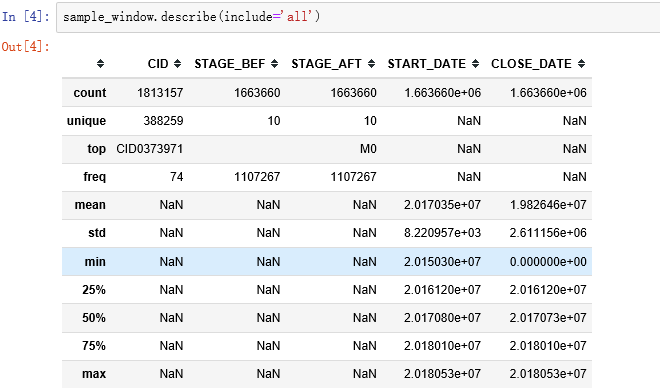
根据描述结果可以看出最后一列即本阶段结束时间最小值为0,且包含缺失值,故需要先处理缺失值再处理异常值0

1.3数据清洗
1.3.1去重

drop_duplicates是数据框去重的函数,可以根据指定的若干列(subset=)去重
1.3.2缺失值的处理
后4列缺失值比例相同约为0.08,若缺失值在同一行,则考虑删除。所以验证各列缺失值是否在同一行。

在同一行,删除

1.3.3异常值的处理

replace:替换数据框中的指定值,输入字典,键是被替换值,值是替换值
1.3.4生成衍生变量
从数据中的进入本阶段时间和本阶段结束时间(4,5列)抽取对应的月份信息 •从本阶段进入的逾期阶段(3列)中抽取逾期指标

1.4构建矩阵
这里的矩阵表示:
•相继时间内逾期状态的变化情况,相继时间表示从一个月到下一个月
•每一行表示开始月份时的逾期状态,每一列表示结束月份时的逾期状态
•开始月份和结束月份是相继的,即间隔一个月
1.4.1逻辑关系
1.每一行数据对应一个本阶段的逾期状态,对应两个月份时间:进入本阶段时间和本阶段结束时间
- 可以将这两个时间都理解为逾期状态对应的时间,即逾期时间
- 生成逾期状态数据框,每行对应三列:id,逾期状态,逾期时间(包含进入本阶段时间和本阶段结束时间)
2.将逾期状态数据框内转置,生成时间数据框:行是id,列是逾期时间
- 转置前事先对数据排序,去重,保留同ID,同时间下逾期状态的最大值
3.使用时间数据框:由于列是已经排序的两列,取前后相继的两列,即相继的两个月,统计逾期状态变化的频数,得到所有相继两列状态变化的频数
- 根据统计的频数,构建矩阵,行表示相继时间中开始时间对应的逾期状态,列表示结束时间对应的逾期状态
4使用得到的矩阵,生成新列:
- 每个状态所有可能的变化,即行和
- 每个状态所有不好的变化,即表示状态的数字变大
- 每个状态不好的变化的占比,即不好的变化除以所有可能的变化
1.4.2生成预期状态数据框


1.4.3生成时间数据框

排序和去重:
- sort_values:依据值排序,缺失值默认在末尾.依据指定列进行排序,设置by=一列或多列(列表)列名即可
- drop_duplicates:根据若干列去重, 设置subset指定列,keep表示要保留的数据,可选"first","last",False(表示去掉所有重复的行)

- set_index:给出若干列,将列作为行索引(每行可以有多个索引)
- unstack:level=-1, fill_value=None, 第一个参数表示以哪列索引作为列, 默认最后一列, 相当于以选定的索引列作为列名, 其他作为行名

1.4.4生成矩阵
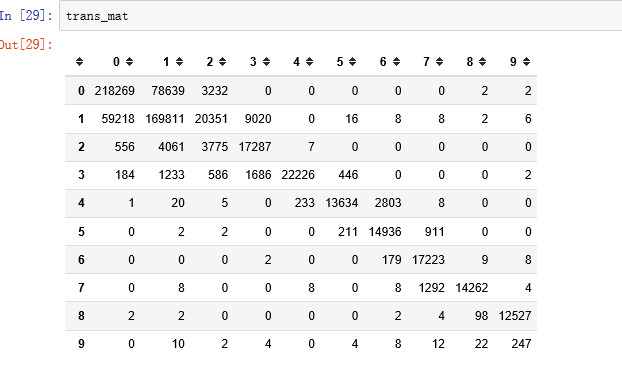

最终矩阵

绘图观察
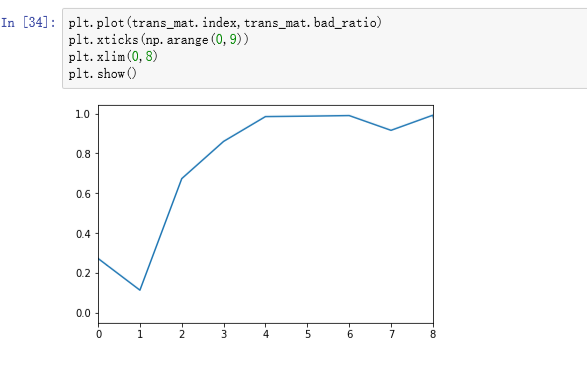
- 可见M1是一个明显的最低点和拐点,到M2阶段以后坏客户的比例迅速增加,因此这里选定的观察时间窗口为M2,即30-60天,我们就可以定义逾期大于30天的客户为坏客户
- 可以根据业务需求进一步调整观察时间窗口
2.确定表现时间窗口
使用用户订单时间表data/CreditFirstUse.csv:
- CID:用户ID
- FST_USE_DT:用户订单时间
2.1数据读取及描述

- 可见没有缺失值,没有重复订单号
- 用户订单时间从2015年1月1日到2017年10月31日,初步判断没有异常值

2.2数据清洗

使用前面生成的时间数据框:
- 由于选取观察时间窗口为M2,对于每个ID:
- 取逾期状态大于等于2的首个月作为逾期月
- 逾期月表示客户开始转向坏客户
- 使用逾期月生成新列

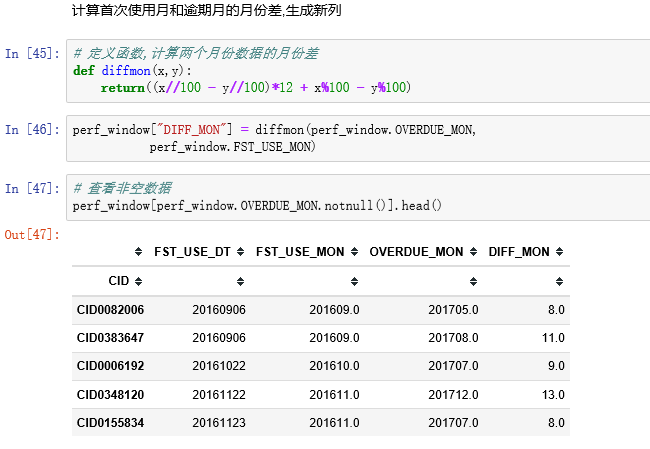
统计月份差异的频数,并且排序
- 发现有的时间差是负的,把排序后前面负的时间差去掉
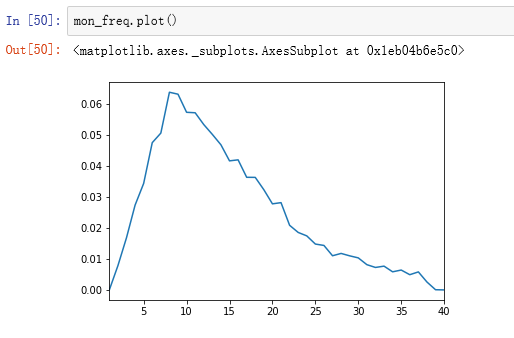
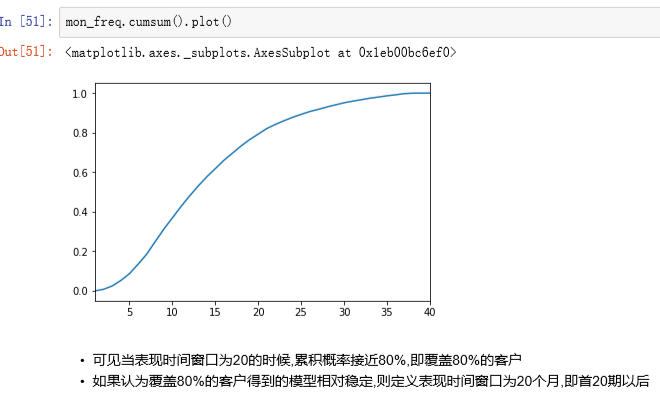
2.3定义y的总结
- 通过之前的数据筛选和汇总,我们定义观察时间窗口为M2(30-60天),表现时间窗口为20
- 即对于所有客户来说,我们认为在订单生成20个月内
- 有M2以上的逾期,即逾期天数>=31天,为坏客户
- 有M1以下的逾期,即逾期天数<=3天,为好客户
- 中间状态的样本认为是不确定的不进入模型
3 . 评分卡制作
该数据是信贷数据,来自kaggle2011年的竞赛数据:Give Me Some Credit,评判指标是AUC
- SeriousDlqin2yrs:出现90天或更长时间的逾期行为(即定义好坏客户)
- RevolvingUtilizationOfUnsecuredLines:贷款以及信用卡可用额度与总额度比例
- age:借款人借款年龄
- NumberOfTime30-59DaysPastDueNotWorse:过去两年内出现35-59天逾期但是没有发展的更坏的次数
- DebtRatio:每月偿还债务,赡养费,生活费用除以月总收入
- MonthlyIncome:月收入
- NumberOfOpenCreditLinesAndLoans:开放式贷款和信贷数量
- NumberOfTimes90DaysLate:借款者有90天或更高逾期的次数
- NumberRealEstateLoansOrLines:抵押贷款和房地产贷款数量,包括房屋净值信贷额度
- NumberOfTime60-89DaysPastDueNotWorse:过去两年内出现60-89天逾期但是没有发展的更坏的次数
- NumberOfDependents:家庭中不包括自身的家属人数(配偶,子女等)
3.1 读取数据以及描述统计
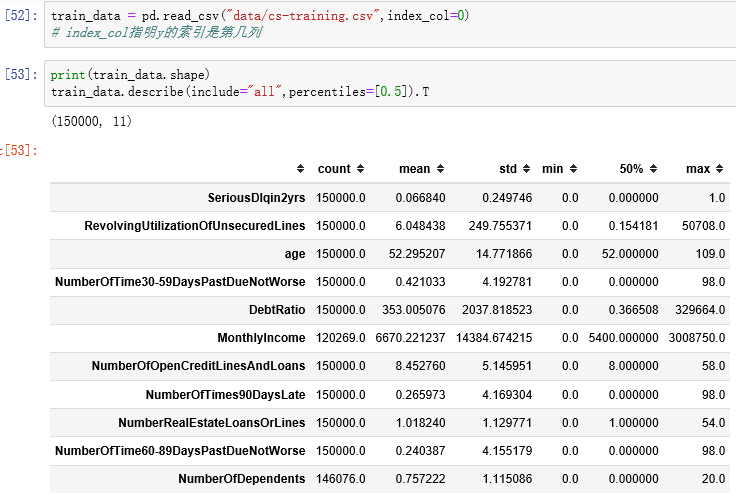
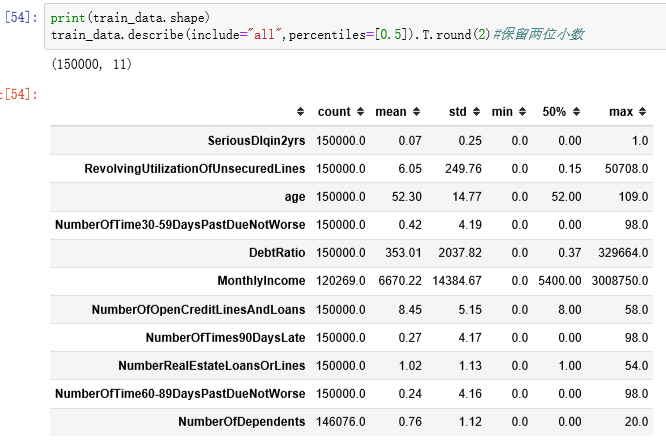
修改列名:由于一些算法中,列名中的某些符号会带来问题甚至报错,例如这里的"-",会在回归公式中被认为是减号,所以换成"_"
3.1.1去重

3.2缺失值处理
缺失值处理方法的选择,主要依据是业务逻辑和缺失值占比,在对预测结果的影响尽可能小的情况下,对缺失值进行处理以满足算法需求,所以要理解每个缺失值处理方法带来的影响,下面的缺失值处理方法没有特殊说明均是对特征(列)的处理:
- 占比较多:如80%以上:删除缺失值所在的列
- 如果某些行缺失值占比较多,或者缺失值所在字段是苛刻的必须有值的,删除行
- 占比一般:如30%-80%:将缺失值作为单独的一个分类
- 如果特征是连续的,则其他已有值分箱
- 如果特征是分类的,考虑其他分类是否需要重分箱
- 占比少:10%-30%:多重插补:认为若干特征之间有相关性,则可以相互预测缺失值
- 需满足的假设:MAR:Missing At Random:数据缺失的概率仅和已观测的数据相关,即缺失的概率与未知的数据无关,即与变量的具体数值无关
- 迭代(循环)次数可能的话超过40,选择所有的变量甚至额外的辅助变量
- 详细的计算过程参考:Multiple Imputation by Chained Equations: What is it and how does it work?
- 占比较少:10%以下:单一值替换,如中位数,众数
- 在决策树中可以将缺失值处理融合到算法里:按比重分配
这里的占比并不是固定的,例如缺失值占比只有5%,仍可以用第二种方法,主要依据业务逻辑和算法需求
3.2.1查看缺失值分布情况

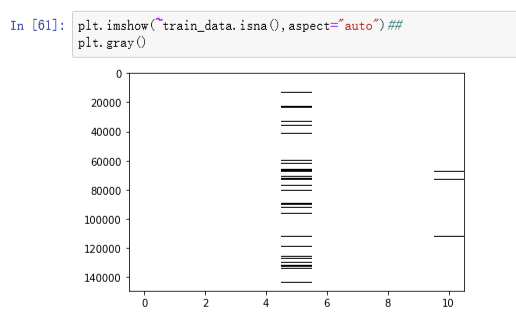
本数据的缺失值处理逻辑:
- 对于信用评分卡来说,由于所有变量都需要分箱,故这里缺失值作为单独的箱子即可
- 对于最后一列NumberOfDependents,缺失值占比只有2.56%,作为单独的箱子信息不够,故做单一值填补,这列表示家庭人口数,有右偏的倾向,且属于计数的数据,故使用中位数填补
- 这里没必要进行多重插补,下面的多重插补只是为了让读者熟悉此操作
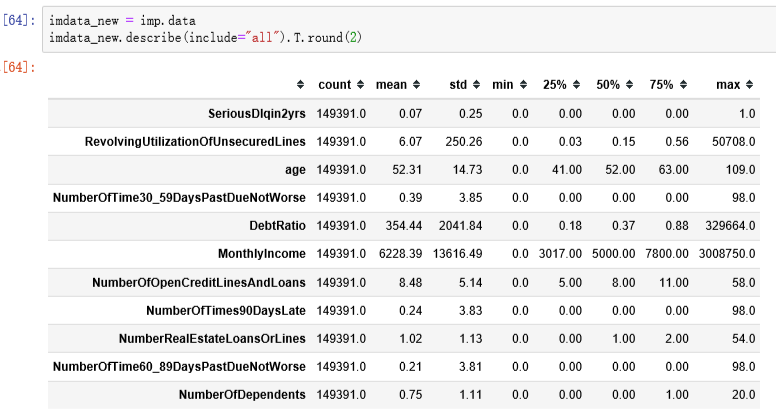
3.2.2多重差补
3.2.3单一值替换

3.3异常值处理
异常值常见的处理方法:
- 删除所在的行
- 替换成缺失值,与缺失值一起处理
- 盖帽法处理
结合业务逻辑和算法需求判断是否需要处理异常值以及如何处理,一般情况下盖帽法即可,即将极端异常的值改成不那么异常的极值,当然一些算法例如决策树中连续变量的异常值也可以不做处理
3.3.1定义盖帽法函数

互换y值(0,1互换)

3.4汇总清洗过程,生成函数

3.5 对每个x生成分箱对象

- 1.定义y的名字
- 2.初始化IV值对象

3.5.1 对“RevolvingUtilizationOfUnsecuredLines”分箱


保存IV值

对每个变量都进行上边的步骤分箱
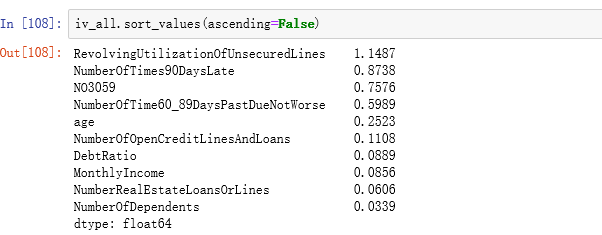
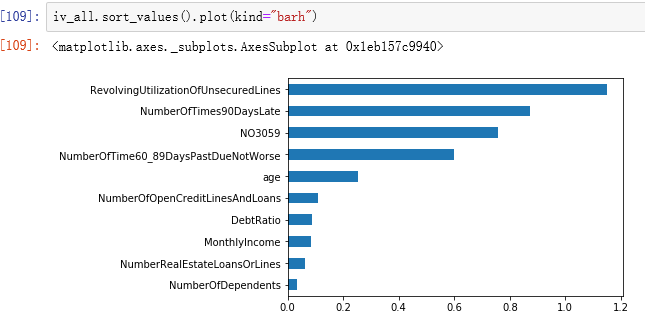
3.6查看所有IV值
IV(information Value):信息值,表示变量的重要性.
IV<0.02对预测几乎没用,应该删除;0.02≤IV<0.1,有一定的帮助;0.1 ≤ IV < 0.3,对预测较重要;IV ≥ 0.3,对预测十分重要。
3.7 生成WOE数据
WOE(Weight of Evidence):证据权重,与违约比例同方向变动,可以看到不同分箱的重要性
之前smbin和smbin_cu得到的对象根据IV值筛选后,放在一个列表中

3.7.1使用smgen函数根据得到的列表生成新数据

3.7.2要求
- 抽取WOE列作为预测数据X
- 加常数项列
- 抽取响应列作为Y
3.8建模
建立逻辑回归模型,拟合数据,查看回归结果
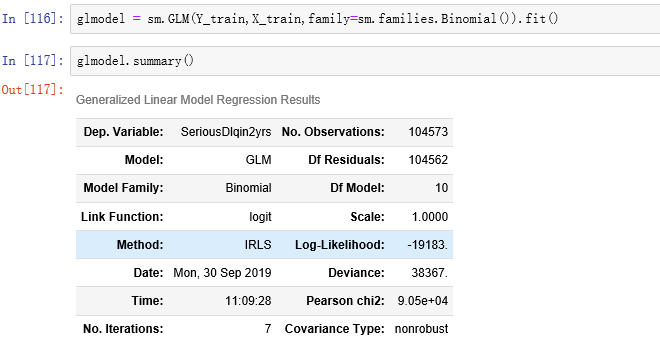
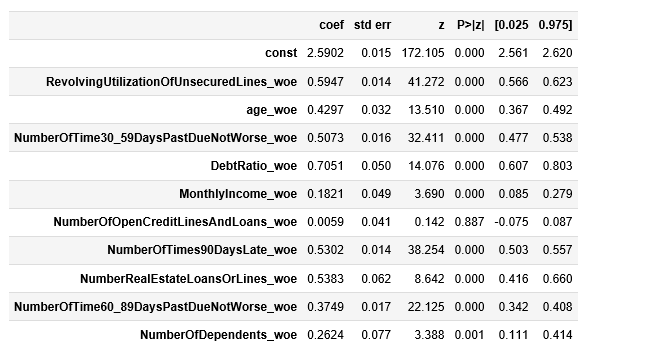
可以看出NumberOfOpenCreditLinesAndLoans_woe不显著,应该从模型中剔除


从3.7部分重新运行,模型回归结果如下:

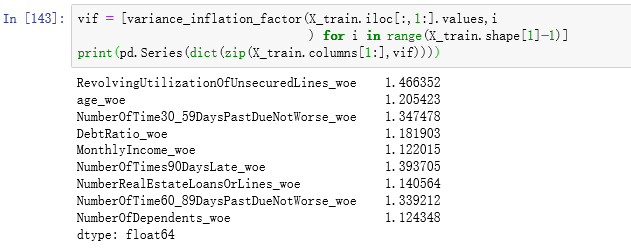
3.8.1查看多重共线性
根据VIF值判断,大于10则存在多重共线性,显然不存在。
3.9生成评分卡
- 根据逻辑回归模型和之前筛选得到的列表,给定参数,生成评分卡
- 调整参数,使得评分卡分数范围满足需求

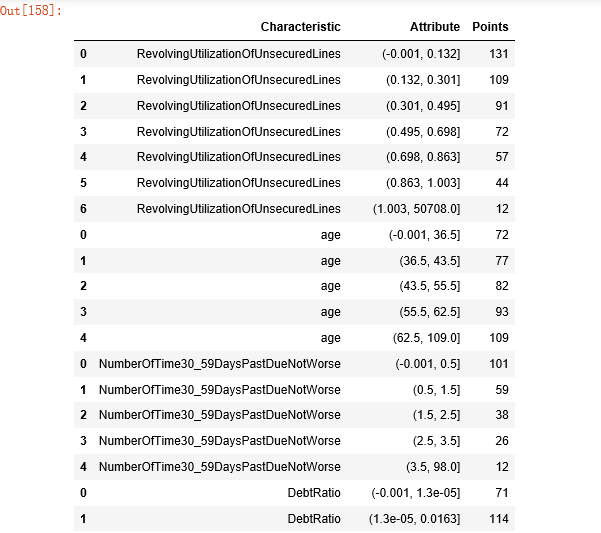
...

3.10模型评估
根据之前的分卡对象得到测试集分数

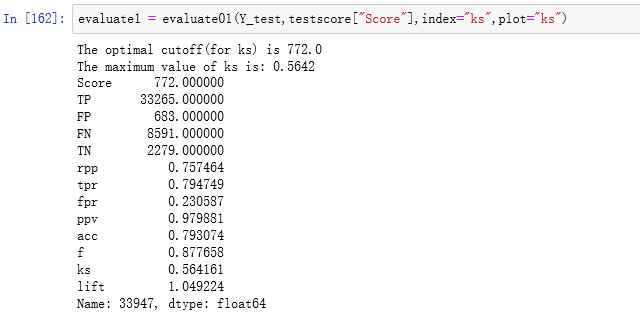
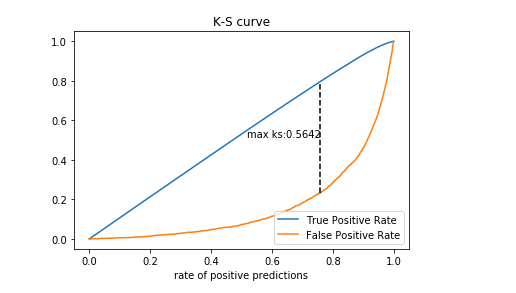
ROC曲线
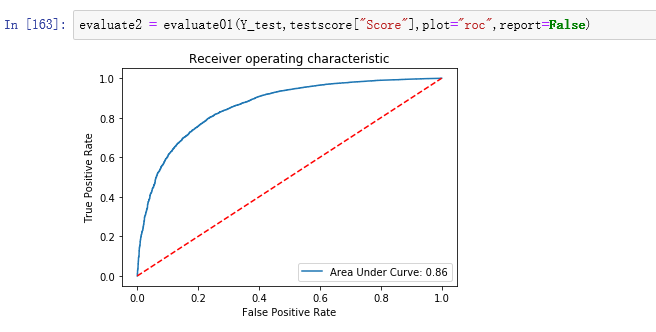
由上图可知AUC值0.86,说明该模型的拟合效果较好
4.新数据的预测
4.1读取数据

4.2清洗数据

4.3生成WOE矩阵
抽取WOE数据生成预测用数据 •要加常数项列

4.4预测
4.4.1预测每一行数据是好客户的概率

4.4.2预测每行数据的分数,生成总分数和每个特征的分数

4.5标签
根据分数和训练得到的阈值判断客户的好坏,好客户是1,坏客户是0

完结。