在实际的爬虫项目开发过程中,对待抓取的URL列表的设计时很重要的一部分。很多时候,顺序很重要,比如:伦理道德上讲究长幼有序;对应URL,要先抓取哪一个页面呢?对于决定这些URL顺序的方法,成为抓取策略。
接下来介绍几种常见的抓取策略:深度优先遍历策略、宽度优先遍历策略、大站优先策略、最佳优先搜索策略。
深度优先遍历策略
深度优先策略和广度优先策略相对。
定义:深度优先遍历策略是指爬虫从起始页开始,一个链接一个链接的跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
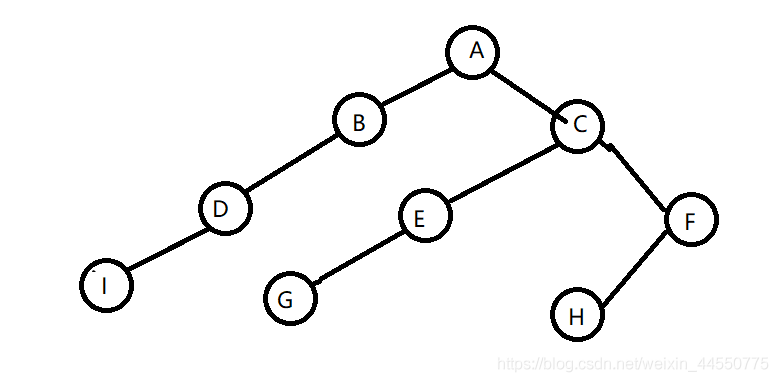
上图中,依据深度优先遍历策略顺序为:A→B→D→I→C→E→G→F→H。
宽度优先遍历策略
宽度优先策略的基本思路是:将新下载网页中发现的链接直接插入到待抓取URL对列中的末尾。也就是说,网页爬虫首先会抓取起始网页链接中的所有网页,然后选择其中一个网页,继续抓取此网页链接中的所有网页。
使用宽度优先遍历策略的话,同样的网页,抓取顺序为:A→B→C→D→E→F→I→G→H。
大站优先策略
定义:以网站单位来进行主题选择,确定优先性,对于待爬取URL队列中的网页,根据所属网站归类,如果那个网站等待下载页面最多,则优先下载这些链接。
关键点:判断待下载页面的多少。
本质:倾向于下载大型网站,因为大型网站往往包含更多的页面。
原因:鉴于大型网站往往是著名企业的内容,其网页质量一般较高。
实验表明,这个算法效果也要略优于宽度优先遍历策略。
最佳优先搜索策略
定义:按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或机构URL进行抓取。它只访问经过网页分析算法认为“有用”的网页。
关键点:访问经过分析,认为“有用”的网页。
不足:在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种足部最优搜索算法。因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点。