我们需要做很多很多小矩阵相乘(维数只有几十),但是次数很多,所以用哪个矩阵库的函数对我们很重要。这里写一个很小的测试代码,测试lapack(包含着朴素的blas),cblas,还有手写函数,对比它们做小矩阵相乘的效率。
对于给定的维数,这三种办法,每种都做1000次方阵相乘\(AB = C\),每次相乘用的矩阵 \(A,B\) 都是随机的。计时用的是 clock(),取的是 cpu 时间。
#include<iostream>
using namespace std;
#include<fstream>
#include<cmath>
#include<vector>
#include<complex>
#include "mkl.h"
extern "C" void dgemm_(char *TRANSA, char *TRANSB, int *M, int *N, int *K, double* ALPHA, double *A, int* LDA, double *B, int* LDB, double* BETA, double *C, int* LDC);
/*
* wraps dgemm_() in lapack, uses one of the optional modes of it to do C := A B
* int n dimension
* double * A A[ n*n ]
* double * B B[ n*n ]
* double * C C[ n*n ]
*/
void lapack_dgemm( int n, double * A, double * B, double * C ){
// dgemm (... ) : C = alpha * op( A ) * op( B ) + beta * C
char TRANSA='N'; // op( A ) = A
char TRANSB='N'; // op( B ) = B
int M=n; // number of rows in A
int N=n; // number of columns in B
int K=n; // number of columns in A, also equals number of rows in B
double ALPHA=1.0; // alpha
double BETA=0.0; // beta
int LDA=n; // leading dimension of A
int LDB=n; // leading dimension of B
int LDC=n; // leading dimension of C
dgemm_(&TRANSA, &TRANSB, &M, &N, &K, &ALPHA, B, &LDA, A, &LDB, &BETA, C, &LDC);
// because dgemm is written in fortran, it actually gets B^\top A^\top = ( AB )^\top, an (AB)^\top will actually be stored in fortran manner, that is AB in C++
}
void mtx_multiply( int n, double * A, double * B, double * C ){
double y;
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
y = 0;
for(int k=0;k<n;k++) y += A[i*n+k] * B[k*n+j];
C[i*n+j] = y;
}
}
};
void cmtx_multiply( int n, complex<double> * cA, complex<double> * cB, complex<double> * cC ){
//#pragma omp parallel for
for(int i=0;i<n;i++){
complex<double> y;
for(int j=0;j<n;j++){
y = 0;
for(int k=0;k<n;k++) y += cA[i*n+k] * cB[k*n+j];
cC[i*n+j] = y;
}
}
};
void cblaszgemm3m( int n, complex<double> * A, complex<double> * B, complex<double> * C ){
complex<double> alpha = {1,0}, beta = {0,0};
cblas_zgemm3m( CblasRowMajor, CblasNoTrans, CblasNoTrans, n, n, n, &alpha, A, n, B, n, &beta, C, n );
}
void cblaszgemm( int n, complex<double> * A, complex<double> * B, complex<double> * C ){
complex<double> alpha = {1,0}, beta = {0,0};
cblas_zgemm( CblasRowMajor, CblasNoTrans, CblasNoTrans, n, n, n, &alpha, A, n, B, n, &beta, C, n );
}
void printmtx( int n, complex<double> * A ){
for(int i=0;i<n;i++){
for(int j=0;j<n;j++)cout<< A[i*n+j]<<", ";
cout<<endl;
}
}
void randcmtx( int n, complex<double> * A ){
for(int i=0;i<n*n;i++) A[i] = ((double)rand())/RAND_MAX;
}
void randmtx( int n, double * A ){
for(int i=0;i<n*n;i++) A[i] = ((double)rand())/RAND_MAX;
}
int main(){
/*
// test: A = [ 0, 1, 0, 0 ], B = [ 0, 1, -1, 0 ]
// AB = [ -1, 0, 0, 0 ], A^T B^T = [ 0, 0, 0, -1 ]
int n = 2;
double A[4] = { 0, 1, 0, 0 };
double B[4] = { 0, 1, -1, 0 };
double C[4];
lapack_dgemm( n, A, B, C );
cout<<"C: "; for(int i=0;i<4;i++) cout<<C[i]<<","; cout<<endl;
*/
vector<int> dim = {10, 20, 30, 40 };
vector<double> ave_t_lapack_dgemm;
vector<double> ave_t_cblas_dgemm;
vector<double> ave_t_hand_dgemm;
vector<double> ave_t_cblas_zgemm3m;
vector<double> ave_t_cblas_zgemm;
vector<double> ave_t_hand_zgemm;
vector<double> ratio;
int nrepeat = 1000; double x;
for(auto n : dim ){
cout<<" n = "<<n<<endl;
double * A = new double [ n*n ];
for(int i=0;i<n*n;i++) A[i] = ((double)rand())/RAND_MAX;
double * B = new double [ n*n ];
for(int i=0;i<n*n;i++) B[i] = ((double)rand())/RAND_MAX;
double * C = new double [ n*n ];
clock_t t1, t2, t3, t4;
double alpha = 1, beta = 0;
double t_lapack_dgemm = 0, t_cblas_dgemm = 0, t_hand_dgemm = 0;
for(int i=0;i<nrepeat;i++){
randmtx( n, A ); randmtx( n, B );
t1 = clock(); lapack_dgemm( n, A, B, C ); t2 = clock(); t_lapack_dgemm += (t2-t1);
t1 = clock();
cblas_dgemm( CblasRowMajor, CblasNoTrans, CblasNoTrans, n, n, n, alpha, A, n, B, n, beta, C, n );
t2 = clock(); t_cblas_dgemm += (t2-t1);
t1 = clock(); mtx_multiply( n, A, B, C ); t2 = clock(); t_hand_dgemm += (t2-t1);
}
x = t_lapack_dgemm/CLOCKS_PER_SEC/nrepeat;
cout<<" lapack dgemm: " << x <<" s."<<endl;
ave_t_lapack_dgemm.push_back( x );
x = t_cblas_dgemm/CLOCKS_PER_SEC/nrepeat;
cout<<" cblas dgemm: "<< x <<" s."<<endl;
ave_t_cblas_dgemm.push_back( x );
x = t_hand_dgemm/CLOCKS_PER_SEC/nrepeat;
cout<<" hand written gemm: " << x << " s."<<endl;
ave_t_hand_dgemm.push_back( x );
complex<double> * cA = new complex<double> [ n*n ];
complex<double> * cB = new complex<double> [ n*n ];
complex<double> * cC = new complex<double> [ n*n ];
double t_cblas_zgemm3m = 0, t_cblas_zgemm = 0, t_hand_zgemm = 0;
for(int i=0;i<nrepeat;i++){
randcmtx(n, cA); randcmtx(n, cB);
t1 = clock(); cblaszgemm3m( n, cA, cB, cC ); t2 = clock(); t_cblas_zgemm3m += (t2-t1);
t1 = clock(); cblaszgemm( n, cA, cB, cC ); t2 = clock(); t_cblas_zgemm += (t2-t1);
t1 = clock(); cmtx_multiply( n, cA, cB, cC ); t2 = clock(); t_hand_zgemm += (t2-t1);
}
x = t_cblas_zgemm3m /CLOCKS_PER_SEC/nrepeat;
cout<<" cblas zgemm3m: " << x <<" s."<<endl;
ave_t_cblas_zgemm3m.push_back( x );
x = t_cblas_zgemm /CLOCKS_PER_SEC/nrepeat;
cout<<" cblas zgemm: " << x <<" s."<<endl;
ave_t_cblas_zgemm.push_back( x );
x = t_hand_zgemm / CLOCKS_PER_SEC/nrepeat;
cout<<" hand zgemm: " << x <<" s."<<endl;
ave_t_hand_zgemm.push_back( x );
delete [] A; delete [] B; delete [] C;
delete [] cA; delete [] cB; delete [] cC;
}
cout<<" ave_t_lapack_dgemm = [ "; for(auto t : ave_t_lapack_dgemm) cout<<t<<", "; cout<<"]\n";
cout<<" ave_t_cblas_dgemm = [ "; for(auto t : ave_t_cblas_dgemm) cout<<t<<", "; cout<<"]\n";
cout<<" ave_t_hand_dgemm = [ "; for(auto t : ave_t_hand_dgemm) cout<<t<<", "; cout<<"]\n";
cout<<" ave_t_cblas_zgemm3m = [ "; for(auto t : ave_t_cblas_zgemm3m) cout<<t<<", "; cout<<"]\n";
cout<<" ave_t_cblas_zgemm = [ "; for(auto t : ave_t_cblas_zgemm) cout<<t<<", "; cout<<"]\n";
cout<<" ave_t_hand_zgemm = [ "; for(auto t : ave_t_hand_zgemm) cout<<t<<", "; cout<<"]\n";
return 0;
}
编译:
icc gemm.cpp -qmkl -lblas -lgsl -O3
运行:
./a.out
做出来的结果如下
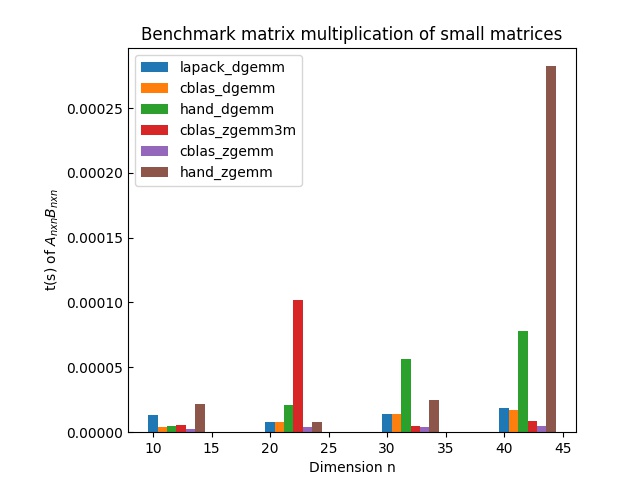
结论是 cblas 比 朴素的 blas或者手写函数都要强(of course)。
但实践中有几个点我要记一下:
- 编译时如果不开 -O3,cblas 很慢,在 n=10, 20 时不如手写
- 如果不是在代码中运行 1000 次取平均,只跑一次进行比较的话,cblas 在 n=10,20,30 也不如手写函数。这个我不是完全理解,但考虑到实践中是密集的矩阵运算,所以运行1000次取平均似乎更接近实际场景。在实践中用 cblas 确实也比手写更快,PVPC Si28 中用 zgemm3m 比用手写函数要耗时少25%,用手写函数要 16s, 用 zgemm3m 要 12s。所以暂时不纠结这个问题了,先用着 cblas。
- 图中zgemm 似乎比 zgemm3m 还快一点,实践中也得到了印证,在 PVPC Si28 中,用 zgemm 只要 10s。