本文是作者原创,版权归作者所有.若要转载,请注明出处.本文只贴我觉得比较重要的源码,其他不重要非关键的就不贴了
我们知道.使用缓存可以更快的获取数据,避免频繁直接查询数据库,节省资源.
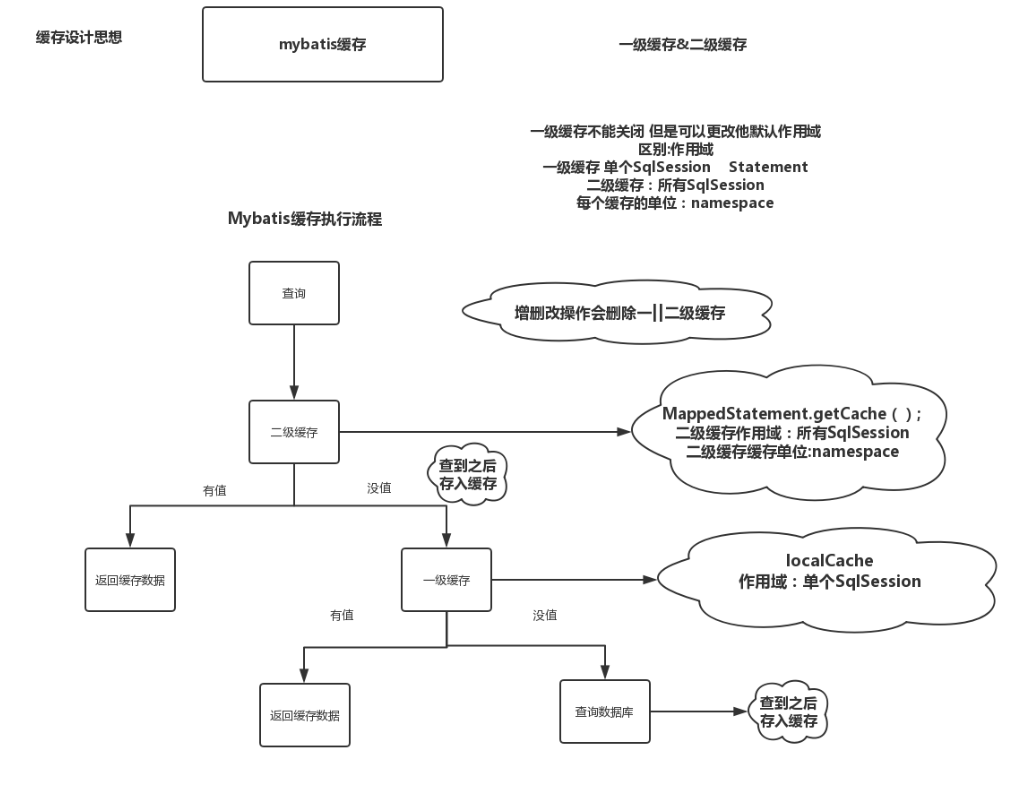
MyBatis缓存有一级缓存和二级缓存.
1.一级缓存也叫本地缓存,默认开启,在一个sqlsession内有效.当在同一个sqlSession里面发出同样的sql查询请求,Mybatis会直接从缓存中查找。如果没有则从数据库查找
下面我们贴一下一级缓存的测试结果
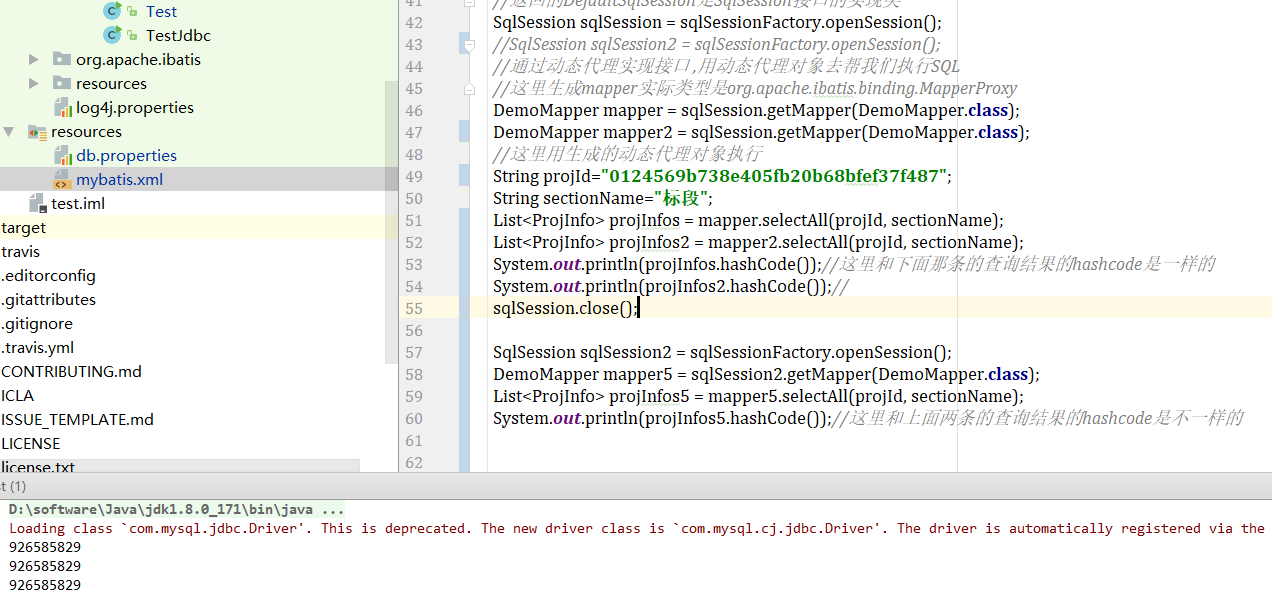
String resource = "mybatis.xml"; //读取配置文件,生成读取流 InputStream inputStream = Resources.getResourceAsStream(resource); //返回的DefaultSqlSessionFactory是SqlSessionFactory接口的实现类, //这个类只有一个属性,就是Configuration对象,Configuration对象用来存放读取xml配置的信息 SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); //SqlSession是与数据库打交道的对象 SqlSession对象中有上面传来的Configuration对象, //SqlSession对象还有executor处理器对象,executor处理器有一个dirty属性,默认为false //返回的DefaultSqlSession是SqlSession接口的实现类 SqlSession sqlSession = sqlSessionFactory.openSession(); //SqlSession sqlSession2 = sqlSessionFactory.openSession(); //通过动态代理实现接口 ,用动态代理对象去帮我们执行SQL //这里生成mapper实际类型是org.apache.ibatis.binding.MapperProxy DemoMapper mapper = sqlSession.getMapper(DemoMapper.class); DemoMapper mapper2 = sqlSession.getMapper(DemoMapper.class); //这里用生成的动态代理对象执行 String projId="0124569b738e405fb20b68bfef37f487"; String sectionName="标段"; List<ProjInfo> projInfos = mapper.selectAll(projId, sectionName); List<ProjInfo> projInfos2 = mapper2.selectAll(projId, sectionName); System.out.println(projInfos.hashCode());//这里和下面那条的查询结果的hashcode是一样的 System.out.println(projInfos2.hashCode());// sqlSession.close(); sqlSession = sqlSessionFactory.openSession(); DemoMapper mapper5 = sqlSession.getMapper(DemoMapper.class); List<ProjInfo> projInfos5 = mapper5.selectAll(projId, sectionName); System.out.println(projInfos5.hashCode());//这里和上面两条的查询结果的hashcode是不一样的

好,我们可以看到,上面两条的查询结果的hashcode一样,第三条不一样,一级缓存生效了
2.二级缓存是mapper级别的,就是说二级缓存是以Mapper配置文件的namespace为单位创建的。
二级缓存默认是不开启的,需要手动开启二级缓存,如下需要在mybatis配置文件中的settting标签里面加入开启
<settings>
<!-- 开启二级缓存。value值填true -->
<setting name="cacheEnabled" value="true"/>
<!-- 配置默认的执行器。SIMPLE 就是普通的执行器;
REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。默认SIMPLE -->
<setting name="defaultExecutorType" value="SIMPLE"/>
</settings>
实现二级缓存的时候,MyBatis要求返回的对象必须是可序列化的,如图
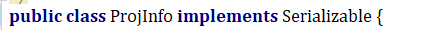
还要在mapper,xml文件中添加cache标签,标签里的readOnly属性需填true 如下:
<cache readOnly="true" ></cache>
<select id="selectAll" resultType="com.lusaisai.po.ProjInfo">
SELECT id AS sectionId,section_name AS sectionName,proj_id AS projId
FROM b_proj_section_info
WHERE proj_id=#{projId} AND section_name LIKE CONCAT('%',#{sectionName},'%')
</select>
我们再来看下二级缓存的运行结果
我们可以看到二级缓存也生效了.
下面来看看缓存的源码,大家猜底层是使用什么实现的,前面的流程就不一一看了,主要贴一下缓存的代码,
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { // BoundSql boundSql = ms.getBoundSql(parameterObject); CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); //这个跟进去看戏,应该是真正的jdbc操作了 return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
我们可以看到,上面的生成了一个缓存的key,具体怎么实现的就先不看了,看下key这个对象有什么属性吧
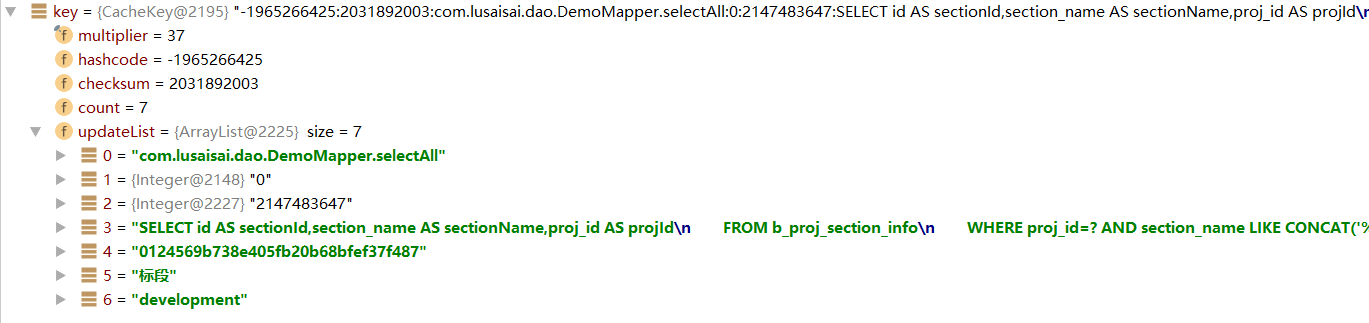
我们可以看到,key对象有这条sql语句除了结果之外的所有信息,还有hashcode等等,我们继续跟进去
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { //MappedStatement的作用域是全局共享的,这里的cache是接口,有多个实现类 Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } //前面是缓存处理跟进去 return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
我们看下Cache 的实现类

有很多,这里就不深究了,继续往下看,我们看下list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql)这行代码,这是处理一级缓存的方法,点进去看下
这里用到我们前面生成的key了
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { //进这里,继续跟 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } // issue #601 deferredLoads.clear(); if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // issue #482 clearLocalCache(); } } return list; }
我们关注下list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;这行代码,点进去看下
@Override public Object getObject(Object key) { return cache.get(key); }
我截个图,看下上图的PerpetualCache对象底层是怎么实现的
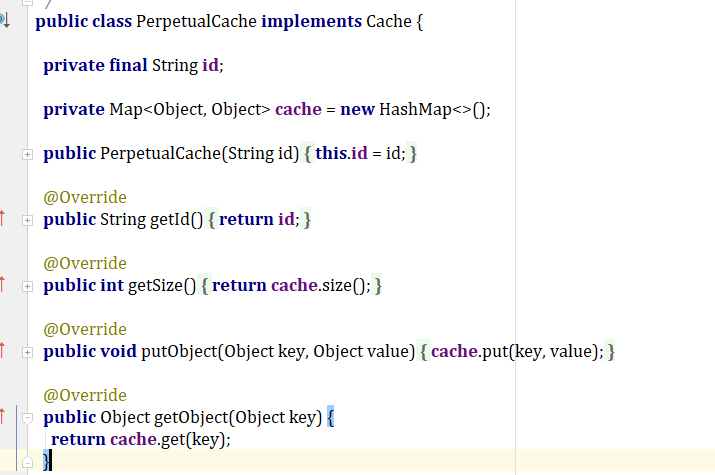
好,很明显了,这里一级缓存是用的hashmap实现的.
下面我们看下二级缓存的代码,上面的List<E> list = (List<E>) tcm.getObject(cache, key);这行代码跟进去
public Object getObject(Cache cache, CacheKey key) { return getTransactionalCache(cache).getObject(key); }
继续跟
@Override public Object getObject(Object key) { // issue #116 Object object = delegate.getObject(key); if (object == null) { entriesMissedInCache.add(key); } // issue #146 if (clearOnCommit) { return null; } else { return object; } }
截个图看下delegate对象的属性,很多层
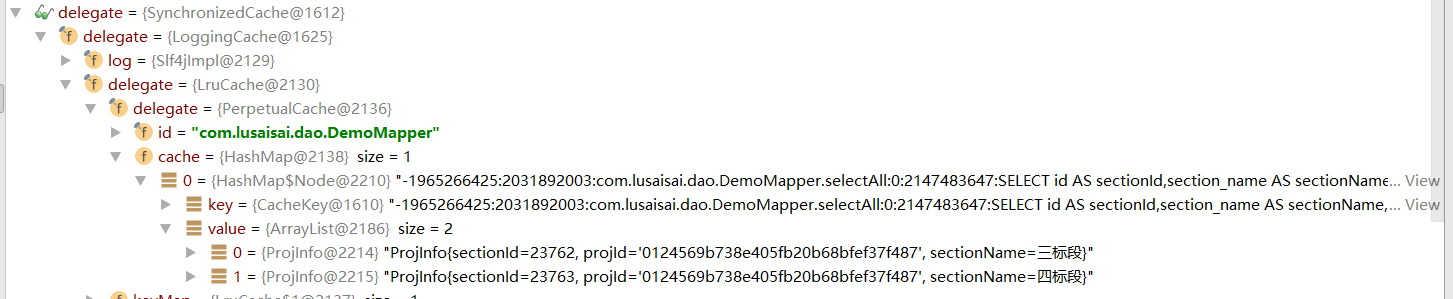
我们可以看到所有数据都在这里了.网上找的图

再来一段缓存的关键代码,这里就是包装了一层层对象的代码
private Cache setStandardDecorators(Cache cache) { try { MetaObject metaCache = SystemMetaObject.forObject(cache); if (size != null && metaCache.hasSetter("size")) { metaCache.setValue("size", size); } if (clearInterval != null) { cache = new ScheduledCache(cache); ((ScheduledCache) cache).setClearInterval(clearInterval); } if (readWrite) { cache = new SerializedCache(cache); } cache = new LoggingCache(cache); cache = new SynchronizedCache(cache); if (blocking) { cache = new BlockingCache(cache); } return cache; } catch (Exception e) { throw new CacheException("Error building standard cache decorators. Cause: " + e, e); } }
好,再来张图总结一下
最后,如果我们和spring整合,那么此时mybatis一级缓存就会失效,因为sqlsession交给spring管理,会自动关闭session.
关于如何和spring整合就后面再来讲吧,下面一段时间,我会先研究一下spring源码,spring专题见啦