2 DynGEM: Deep Embedding Method for Dynamic Graphs
link:https://arxiv.org/abs/1805.11273v1
Abstract
首先这个嵌入是基于deep autoencoder的
该论文提出了三个主要优势:
(1)随着时间的推移,该方法嵌入是稳定的
(2)能处理不断增长的动态图
(3)它比在动态图的每个快照上使用静态嵌入方法具有更好的运行时间
Conclusion
DynGEM使用动态扩展的深度自动编码器来捕获高度非线性的图节点的一阶和二阶近似值。此外,模型利用以前时间步骤的信息,通过在每个时间步骤逐渐学习嵌入来加速训练过程。我们的实验证明了我们的技术在时间上的稳定性,并证明我们的方法在所有评估任务上保持了竞争力,例如图形重建、链接预测和可视化。
Figure and table
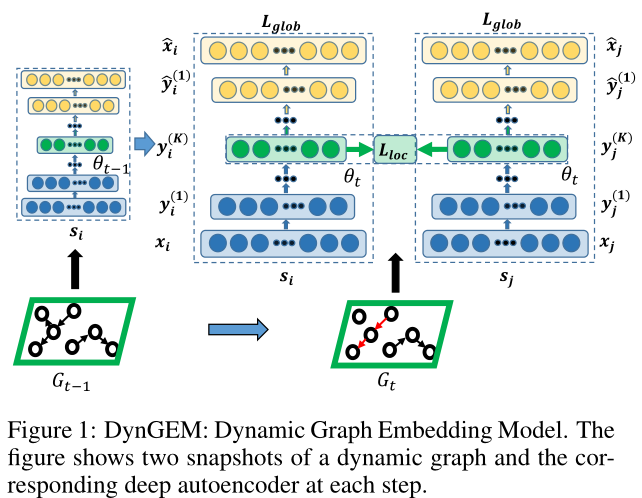
图1 DynGEM的结构
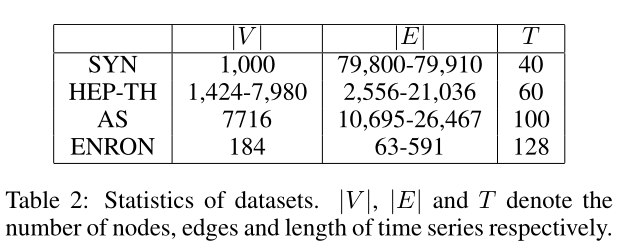
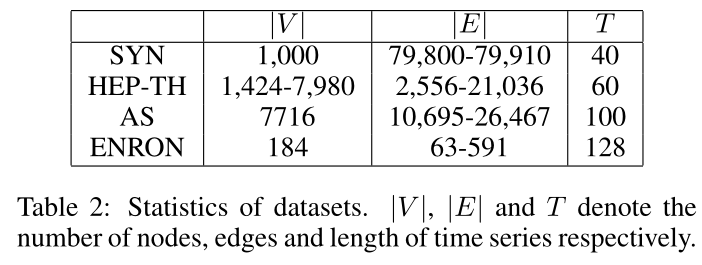
表2 使用的数据集及其参数
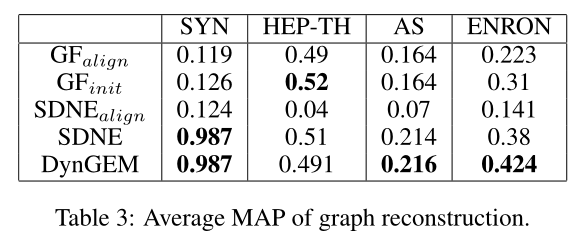
表3:图重构的效果对比(MAP:Mean Average Precision)
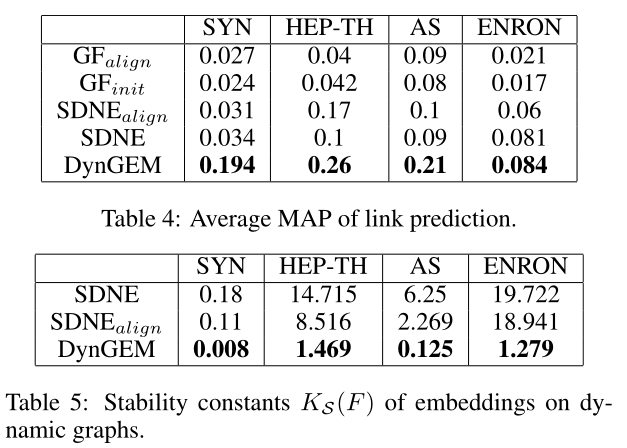
表4:连接预测的效果对比
表5:\(embedding\)稳定系数\(K_s(F)\)对比

图2 社区稳定性图例
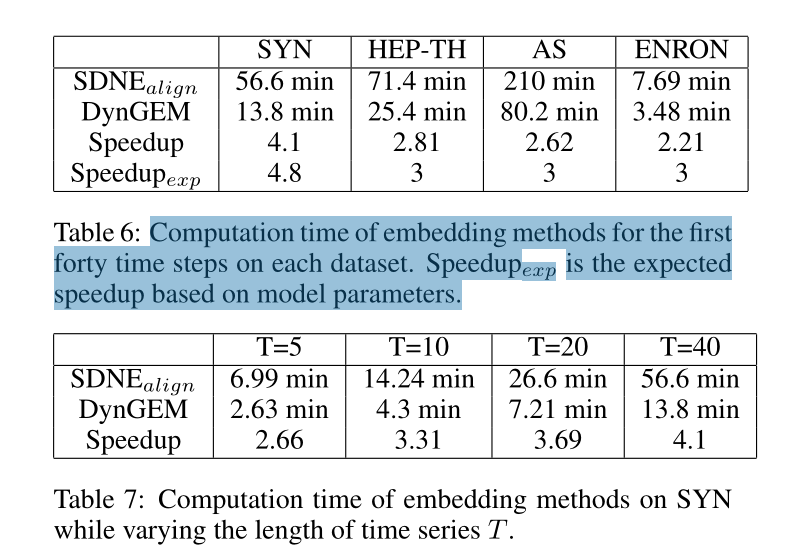
表6,7 运行时的效率对比
Introduction
介绍嵌入的优点,列举了几个静态嵌入的方法:
SVD,拉普拉斯矩阵或高阶邻接矩阵分解,随机游走等
提了一下SDNE这个方法,它利用深度自动编码器处理非线性,以生成更精确的嵌入。
接着传统异能,基本上每一篇论文都这样说:上面的工作都是基于静态图的,但是生活中都是动态图。有一些关于动态图的研究,但都是基于快照机制的,将会导致大量的计算和存储开销。
下一段作者提了几个挑战(就是把摘要中的几个自己的优点又说了一遍,《论paper的写作艺术》):
稳定性:静态方法生成的嵌入是不稳定的,也就是说,在连续的时间步中嵌入的图可能会有很大的不同,即使这些图变化不大
不断增长的图:随着动态图的时间增长,可以在图中引入新节点,并创建到现有节点的新链接。所有现有的方法都假设在学习图嵌入时有固定数量的节点,因此无法处理不断增长的图。
可扩展性:独立学习每个快照的嵌入会导致快照数量的运行时间呈线性。由于学习单个嵌入在计算上已经很昂贵,这种简单的方法无法扩展到具有许多快照的动态网络。
说明自己工作和其他人的区别:其他工作有尝试加入正则化来使得快照之间平滑过渡的,这种方法不适用于连续时间步长可能显著不同的动态图,因此无法用于异常检测等应用。《Deep coevolutionary network:
Embedding user and item features for recommendation》学习动态图的嵌入,但是他们关注的是专门用于用户-物品的二部图
接着引出自己的方法DynGEM,说自己的方法是基于deep-autoenconder的方法,每次更新\(t\)时刻的嵌入都是从\(t-1\)时刻进行增量构建的,而不是从头开始训练一个嵌入。这种方法不仅确保了嵌入在时间上的稳定性,而且还导致了有效的训练,因为在第一个时间步之后的所有嵌入只需要很少的迭代就可以收敛。为了处理节点数量不断增加的动态图,该模型使用自己探索出的算法——PropSize,逐步增大神经网络的大小,以动态确定每个快照所需的隐藏单元数。除了提出的模型,我们还引入了动态图嵌入的严格稳定性度量。(这个度量指标好像很关键)
Method
*2 Definitions and Preliminaries
这里介绍了一些图基本概念,节点v映射为embedding的定义

接着是动态图\({\cal G}\)的定义
作者认为\({\cal G}\)是一系列快照的集合,即\({\cal G}=\{G_1,...,G_T\}\),其中\(G_t=(V_t,E_t)\),\(T\)为快照的数量。对于增长图的操作,考虑为新节点加入动态图并创建到现有节点的链接,即\(V_t⊆ V_{t+1}\)。对于删除图的操作,考虑被删除图的节点依旧为图的一部分,只是该节点与剩下点的权值为0。作者认为,假设\(E_t\)和$E_{t+1} $之间没有关系。
扩展于动态图的概念,定义了动态图的嵌入,给定一个动态图\({\cal G}=\{G_1,···,G_T\}\),一个动态图的嵌入定义为为一组映射的时序集合\({\cal F} = \{ f_1, ··· , f_T \}\),即\(f_t\)是\(G_t\)的图嵌入映射
重点来了:作者认为一个好的动态图映射应该是稳定的(“稳定”这个词,作者已经提及很多次了并且都在各种显眼的位置,这篇论文对于作者来说稳定就是最大卖点)。直观地说,一个稳定的动态嵌入是这样一种嵌入:如果基础图的变化不大,则连续嵌入只会有少量的差异,即如果\(G_{t+1}\)与\(G_t\)相差不大,则嵌入输出\(Y_{t+1}=f_{t+1}(G_{t+1})\)和\(Y_t=f_t(G_t)\)也只会有少量的变化。
更具体的说,设\(S_t(\tilde{V})\)为节点集\(\tilde{V}⊆ V_t\)的诱导子图的加权邻接矩阵,\(F_t(\tilde{V})∈ \Bbb {R}^{|\tilde{V}|×d}\)作为在时间\(t\)下的快照节点集\(\tilde{V}⊆ V_t\)的所有的节点嵌入,作者定义绝对稳定性为:
换句话说,任何嵌入\(\cal {F}\)的绝对稳定性是嵌入之间的差值与邻接矩阵之间的差值之比。由于稳定性的定义取决于所涉及矩阵的大小,我们定义了另一种称为相对稳定性的度量,它对邻接矩阵和嵌入矩阵的大小是不变的:
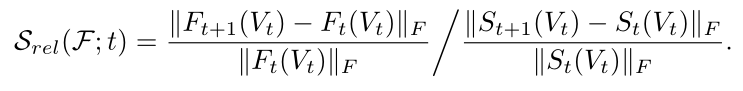
进一步定义了稳定常数
作者认为如果动态嵌入\(\cal {F}\)是稳定的,则它要有一个小的稳定常数。显然,\(\cal {K}_S (F)\)越小,嵌入\(\cal {F}\)就越稳定。在实验中,使用稳定性常数作为度量,将DynGEM算法的稳定性与其他基线进行比较。
3 DynGEM: Dynamic Graph Embedding Model
DynGEM:基于deep-autoencoder架构。
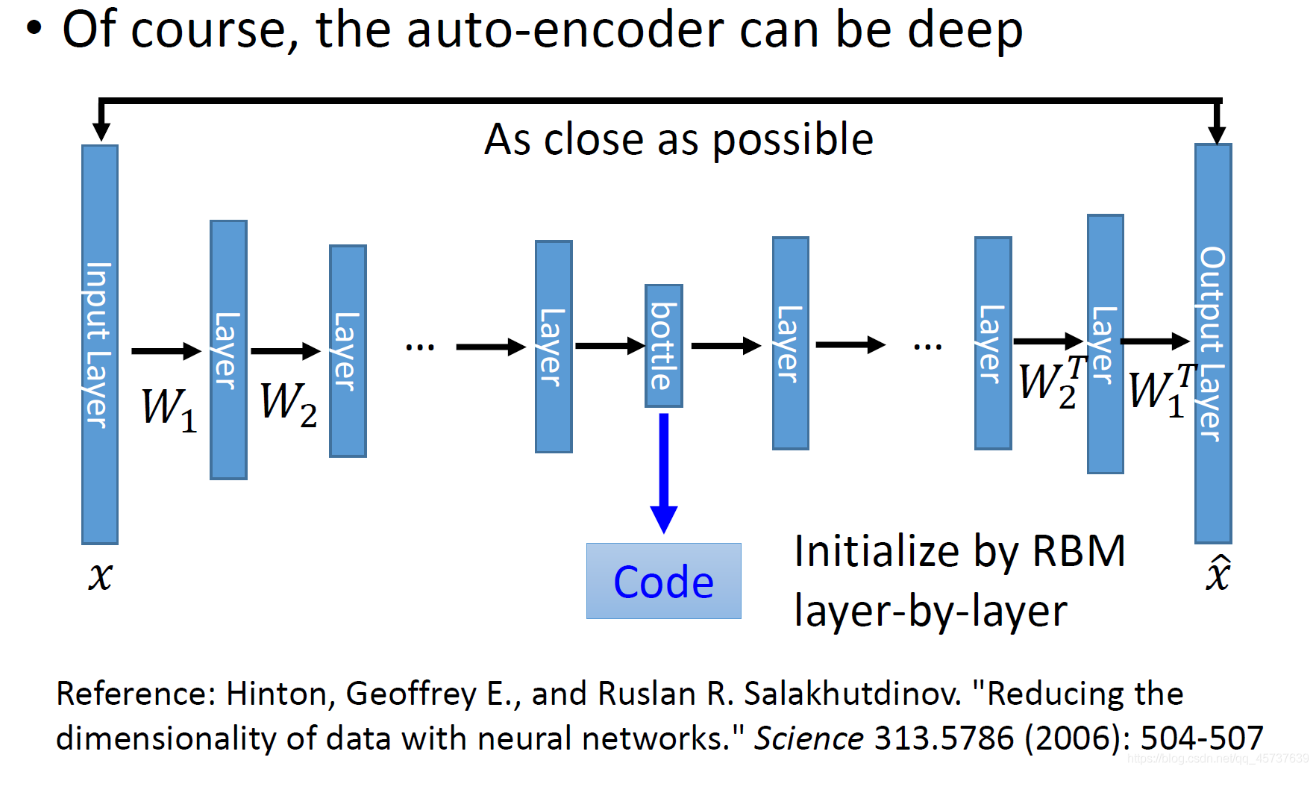
deep-autoencode架构图
可以看见就是一个 \(input\ x_i \to encode \to embedding \ y_i \to decode \to reconstructed \ \hat{x_i}\)
的结构,最后用\(x_i\)和\(\hat{x_i}\)做\(loss\)
3.1 Handling growing graphs
作者在这里提出了一种PropSize的算法,
PropSize:
连续的两层\((l_k, l_{k+1})\)之间(不包括\(bottle\)层)的维度需要满足
其中$ 0 <ρ < 1\(,是一个超参数,如果上述条件不满足,则应该增加\)l_{k+1}\(的维度,但对于\)bottle\(来说,\)bottle\(的维度是恒定的,若\)bottle$和上一层不满足这个关系,则需要在两者之间添加更多层(大小满足上式),直至整个架构满足不等式。
在确定层的数量和每层中隐藏单元的数量后,采用Net2WiderNet和Net2DeeperNet方法来扩展深度自动编码器。
Net2WiderNet:允许我们加宽层,即向现有神经网络层添加更多隐藏单元,同时大致保留该层计算的函数。
Net2DeeperNet:过使新的中间层紧密复制身份映射,在两个现有层之间插入一个新层。层可以用ReLU激活,但不能用sigmoid激活。
3.2 Loss function and training
架构中的相关术语和符号含义如下表

模型损失如下:
其中\(α\)、\(ν_1\)和\(ν_2\)是超参数,用于加权求和各项损失
$L_{loc} =\sum_{i,j}^{n} {s_{ij}}||y_i− y_j||_2^2 $:对应于图的局部结构的一阶近似
\(L_{glob} =\sum_{i=1}^{n} ||(\hat{x}_i− x_i)\bigodot b_i||_2^2=||(\hat{X}− X)\bigodot B||_F^2\):对应于图的全局结构的二阶近似
其中\(b_i\)为惩罚项,\(b_i\)是一个向量,当\(s_{ij}=0\)时(即\(i,j\)之间没有边时),\(b_{ij}=1\),反之\(b_{ij}=\beta > 1\)。作者认为观测到的边上的错误decode惩罚应该比未观测到的边上的错误decode大。
\(L_1,L_2\)皆为正则化项
$L_1 =\sum_{k=1}{K}(||W{(k)}||_1+||\hat{W}^{(k)}||_1) $
$L_2 =\sum_{k=1}{K}(||W{(k)}||_F2+||\hat{W}{(k)}||_F^2) $
3.3 Stability by reusing previous step embedding

算法如上,第一次训练时 ,autoencoder的权重随机产生,后面的每一次训练,都使用上一次的权重进行。
3.4 Techniques for scalability
介绍了一下使用的激活函数和优化器,SCD,ReLU,nesterov等
Experiment
4 Experiments
4.1 Datasets
四个数据集

数据集的具体参数如下
4.2 Algorithms and Evaluation Metrics
选取了几个baseline:

接着介绍了自己模型初始化的结构和选取的超参数等,
首先对ENRON数据集的嵌入维度选择是20,其他数据集是100
模型初始都是两层,ENRON的每层网络神经节点数量为[100, 80],其他为[500,300]
其余超参数如下
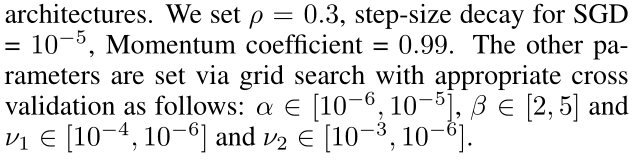
该实验做了图形重建、链接预测、嵌入稳定性和异常检测方面的性能测试。对于前两项任务,即图形重建和链接预测,使用平均精度(MAP)作为度量。为了评估动态嵌入的稳定性,我们使用第2节中定义的稳定常数\(\cal {K}_S (F)\)。
实验环境如下

5 Results and Analysis
相关图表已在开头的Figure and table展示
5.1 Graph Reconstruction
图重构性能见表3,照例sota,除了在HEP-TH上
5.2 Link Prediction
链接预测见表4,照例sota
5.3 Stability of Embedding Methods
稳定性指标见表5,照例sota
5.4 Visualization
见图2,证明了自己算法的稳定性。改变了社区的节点的DynGEM嵌入准确地跟踪原社区结构,而不会干扰其他节点的嵌入。在子图(b)中,有0.3的点都被改变了社区,在时间步结束后,回到了自己应该在的社区,并且三个社区的位置依旧非常稳定
5.5 Application to Anomaly Detection
该模型定义了一个\(∆_t=||F_{t-1}(V_{t-1})-F_{t}(V_t)||_F\)来代表嵌入在连续时间下的变化,如果这个变化大于某个值就认为有异常事件发生,效果图如下
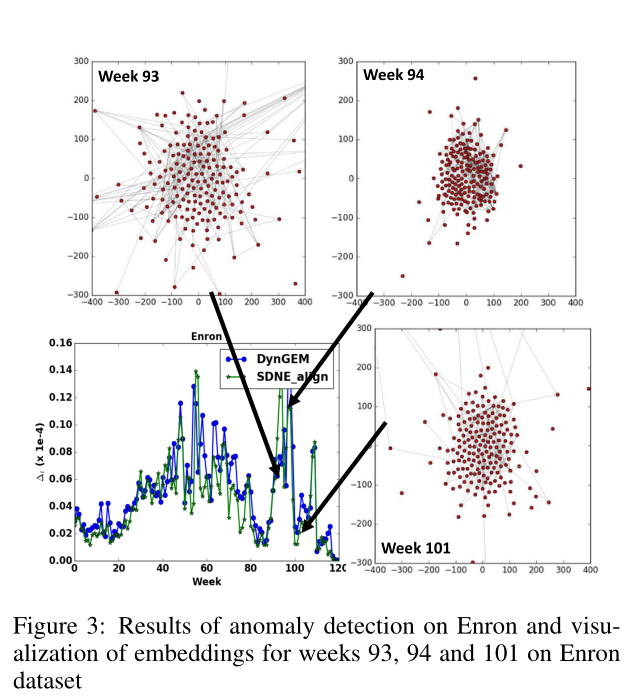
其在45周,55周,94周的主要峰值分别对应事件:杰弗里·斯基林于2001年2月接任首席执行官;罗夫于2001年6月剥离了能源股,联邦调查局于2002年1月开始对首席执行官辞职和犯罪调查。
图3显示了在第94周左右嵌入可视化效果。在第93周和第101周可以观察到分散的嵌入,这两幅图对应这期间员工之间的沟通程度较低。相反,在第94周,沟通程度显著增加(通过高度紧凑的嵌入表示)。
5.6 Effect of Layer Expansion
说了一下PropSize这个算法的有效性,作者说如果不使用该算法, DynGEM表现会明显下降。对于SDNE和SDNEalign,作者在每个时间步选择最佳模型。如果使用PropSize可以避免这种需求,并自动为后续时间步选择一个良好的神经网络大小。
5.7 Scalability
运行效率见表6和7,照例吊打
Summary
这篇文章最大的卖点就是生成稳定嵌入,作者在文中已经不止一次提到稳定这个词,甚至还构造了一个评估稳定性的系数\(\cal {K}_S (F)\),作者利用上次的输出作为这次的输入这样的想法,保证每一次的嵌入就是在上一次嵌入的上下浮动,从而达到稳定性。这篇文章让我感到了写作的艺术(雷军在mix3发布时对比相机性能的金句:肯定是我们好,因为我们不好我们不会挑出来)