一定要动手去写
1. 边学边练,适度刷题
2. 多问、多思考、多互动
B站学习:https://www.bilibili.com/video/av685670
https://github.com/wangzheng0822/algo/tree/master/python
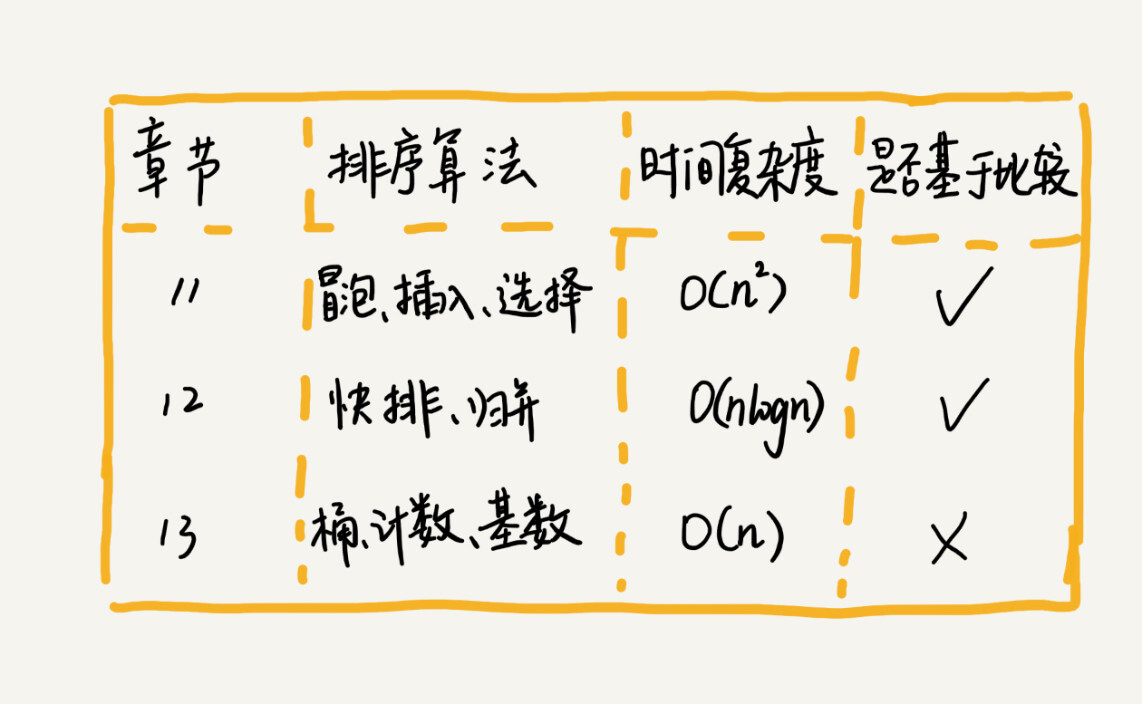
经典排序算法
各种排序演示图:https://visualgo.net/en
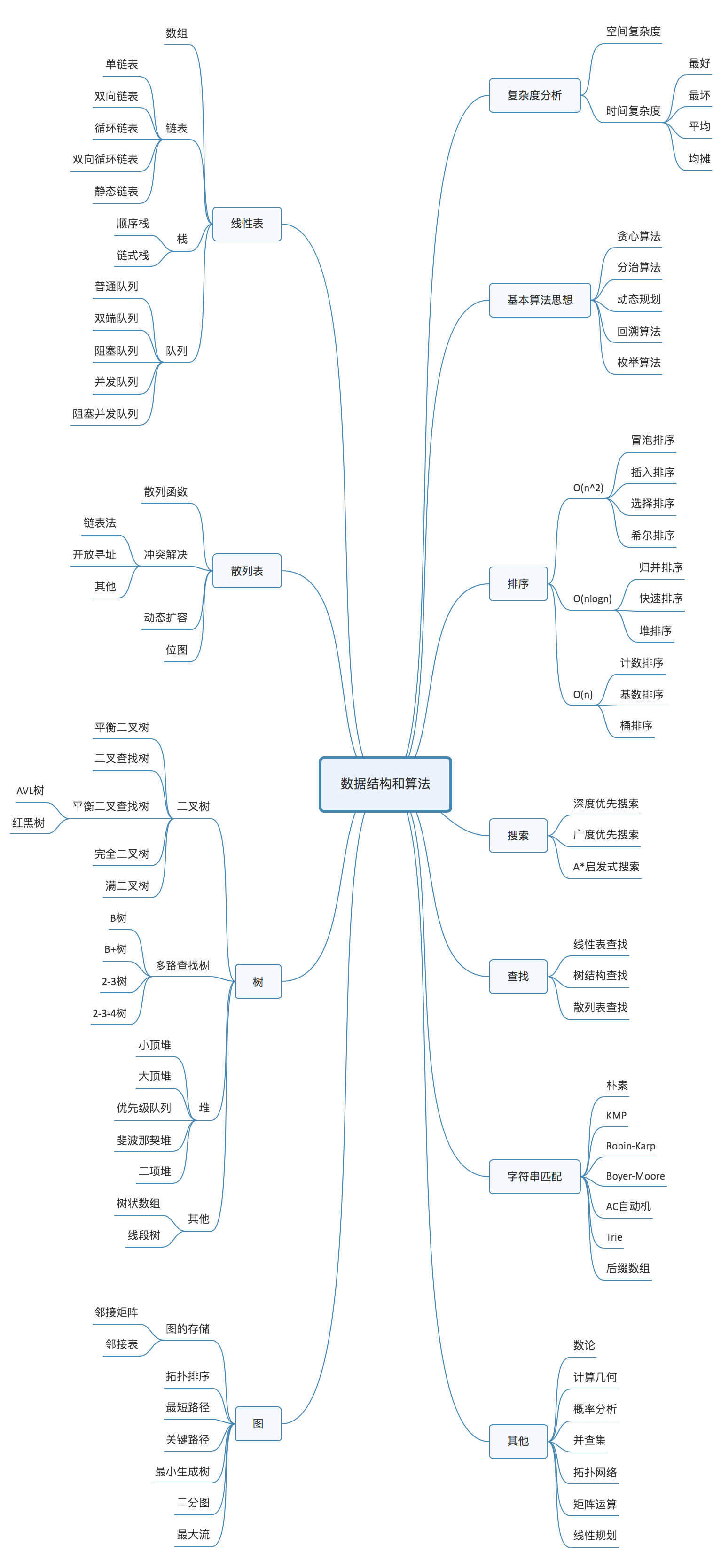
链表 & 数组:
一、什么是链表?
1.和数组一样,链表也是一种线性表。
2.从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构。
3.链表中的每一个内存块被称为节点Node。节点除了存储数据外,还需记录链上下一个节点的地址,即后继指针next。
二、为什么使用链表?即链表的特点
1.插入、删除数据效率高O(1)级别(只需更改指针指向即可),随机访问效率低O(n)级别(需要从链头至链尾进行遍历)。
2.和数组相比,内存空间消耗更大,因为每个存储数据的节点都需要额外的空间存储后继指针。
三、常用链表:单链表、循环链表和双向链表
1.单链表
1)每个节点只包含一个指针,即后继指针。
2)单链表有两个特殊的节点,即首节点和尾节点。为什么特殊?用首节点地址表示整条链表,尾节点的后继指针指向空地址null。
3)性能特点:插入和删除节点的时间复杂度为O(1),查找的时间复杂度为O(n)。
2.循环链表
1)除了尾节点的后继指针指向首节点的地址外均与单链表一致。
2)适用于存储有循环特点的数据,比如约瑟夫问题。
3.双向链表
1)节点除了存储数据外,还有两个指针分别指向前一个节点地址(前驱指针prev)和下一个节点地址(后继指针next)。
2)首节点的前驱指针prev和尾节点的后继指针均指向空地址。
3)性能特点:
和单链表相比,存储相同的数据,需要消耗更多的存储空间。
插入、删除操作比单链表效率更高O(1)级别。以删除操作为例,删除操作分为2种情况:给定数据值删除对应节点和给定节点地址删除节点。对于前一种情况,单链表和双向链表都需要从头到尾进行遍历从而找到对应节点进行删除,时间复杂度为O(n)。对于第二种情况,要进行删除操作必须找到前驱节点,单链表需要从头到尾进行遍历直到p->next = q,时间复杂度为O(n),而双向链表可以直接找到前驱节点,时间复杂度为O(1)。
对于一个有序链表,双向链表的按值查询效率要比单链表高一些。因为我们可以记录上次查找的位置p,每一次查询时,根据要查找的值与p的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
4.双向循环链表:首节点的前驱指针指向尾节点,尾节点的后继指针指向首节点。
四、选择数组还是链表?
1.插入、删除和随机访问的时间复杂度
数组:插入、删除的时间复杂度是O(n),随机访问的时间复杂度是O(1)。
链表:插入、删除的时间复杂度是O(1),随机访问的时间复杂端是O(n)。
2.数组缺点
1)若申请内存空间很大,比如100M,但若内存空间没有100M的连续空间时,则会申请失败,尽管内存可用空间超过100M。
2)大小固定,若存储空间不足,需进行扩容,一旦扩容就要进行数据复制,而这时非常费时的。
3.链表缺点
1)内存空间消耗更大,因为需要额外的空间存储指针信息。
2)对链表进行频繁的插入和删除操作,会导致频繁的内存申请和释放,容易造成内存碎片,如果是Java语言,还可能会造成频繁的GC(自动垃圾回收器)操作。
4.如何选择?
数组简单易用,在实现上使用连续的内存空间,可以借助CPU的缓冲机制预读数组中的数据,所以访问效率更高,而链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法预读。
如果代码对内存的使用非常苛刻,那数组就更适合。
指针 & 引用
有些语言有指针的概念,如C;但有的语言没有指针,取而代之的是引用,如Java,Python。实际上意思是一样的,都是存储所指对象的内存地址。
将某个变量赋值给指针,实际上就是将该变量的地址赋值给该指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量
堆 & 栈
内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构。
内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区。
代码区:存储方法体的二进制代码。高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换。
静态数据区:存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收。
栈区:存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。
堆区:new一个对象的引用或地址存储在栈区,指向该对象存储在堆区中的真实数据。
为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗?
其实,我们不一定非要用栈来保存临时变量,只不过如果这个函数调用符合后进先出的特性,用栈这种数据结构来实现,是最顺理成章的选择。
从调用函数进入被调用函数,对于数据来说,变化的是什么呢?是作用域。所以根本上,只要能保证每进入一个新的函数,都是一个新的作用域就可以。而要实现这个,用栈就非常方便。在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。
为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗?
其实,我们不一定非要用栈来保存临时变量,只不过如果这个函数调用符合后进先出的特性,用栈这种数据结构来实现,是最顺理成章的选择。
从调用函数进入被调用函数,对于数据来说,变化的是什么呢?是作用域。所以根本上,只要能保证每进入一个新的函数,都是一个新的作用域就可以。而要实现这个,用栈就非常方便。在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。