Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,
提示:此文存在问题,真正测试, 请勿阅读,
07-14 14:26更新:
经过两个多小时的测试,发现此问题的原因是 昨天编写爬虫程序后,给爬虫程序添加了下面的属性:
download_timeout = 20
此属性的解释:
The amount of time (in secs) that the downloader will wait before timing out.
在获取某网站的子域名的robots.txt文件时,需要的时间远远超过20秒,因此,即便有三次重试的机会,也会最终失败。
此值默认为180,因为某网站是国内网站,因此,孤以为它的文件全部都会下载的很快,不需要180这么大,于是更改为20,谁知道,其下子域名的robots.txt却需要这么久:
测试期间更改为30时,状况好了,目前已取消设置此值,已能抓取到需要的数据。
可是,为什么robots.txt会下载这么慢呢?
删除Request中定义的errback进行测试,也可以获取到需要的数据。
那么,在Request中定义errback有什么用呢?
现在,再次在项目内、项目外执行下面的命令都不会发生DNSLookupError了(测试过)(可是,上午怎么就发生了呢?):
scrapy shell "http://money.163.com/18/0714/03/DML7R3EO002580S6.html"
--------可以忽略后面部分--------
昨日写了一个爬虫程序,用来抓取新闻数据,但在抓取某网站数据时发生了错误:超时、重试……开始是超过默认等待180秒的时间,后来自己在爬虫程序中改为了20秒,所以下图显示为20 seconds。
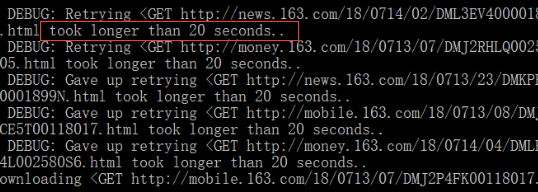
完全不知道怎么回事!上面是使用Scrapy项目内的基于CrawlerRunner编写的程序运行的,看不到更多数据!
尝试将爬虫中的allowed_domains改为下面两种形式(最后会使用第二种)进行测试——以为和子域名有关系:仍然失败。
1 #allowed_domains = ['www.163.com', 'money.163.com', 'mobile.163.com', 2 # 'news.163.com', 'tech.163.com'] 3 4 allowed_domains = ['163.com']
后来又在settings.py中关闭了robots.txt协议、开启了Cookies支持:仍然失败。
1 # Obey robots.txt rules 2 ROBOTSTXT_OBEY = False 3 4 # Disable cookies (enabled by default) 5 COOKIES_ENABLED = True
此时,依靠着之前的知识储备是无法解决问题的了!
使用scrapy shell对获取超时的网页进行测试,结果得到了twisted.internet.error.DNSLookupError的异常信息:
scrapy shell "http://money.163.com/18/0714/03/DML7R3EO002580S6.html"


但是,使用ping命令却可以得到上面失败的子域名的IP地址:
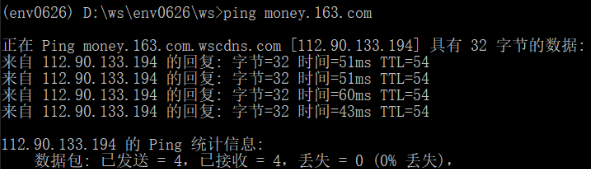
twisted作为一个很常用的Python库,怎么会发生这样的问题呢!完全不应该的!
求助网络吧!最终找到下面的文章:
How do I catch errors with scrapy so I can do something when I get User Timeout error?
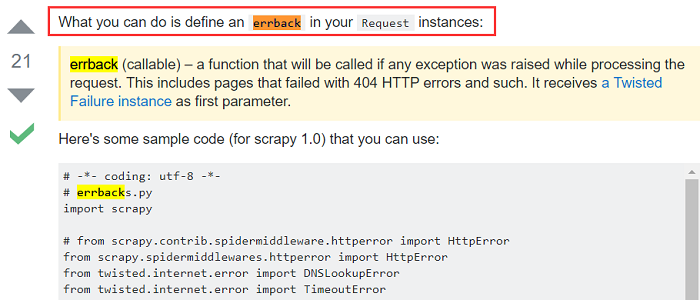
最佳答案!中文什么意思:在Request实例中定义errback!(请读三遍)
这么简单?和处理DNSLookupError错误有什么关系呢?为何定义了回调函数就可以了呢?
没想明白,不行动……
继续搜索,没有更多了……
好吧,试试这个方法,更改某网站的爬虫程序如下:
增加了errback = self.errback_163,其中,回调函数errback_163的写法和上面的参考文章中的一致(后来发现其来自Scrapy官文Requests and Responses中)。
1 yield response.follow(item, callback = self.parse_a_new, 2 errback = self.errback_163)
准备就绪,使用scapy crawl测试最新程序(在将之前修改的配置还原后——遵守robots.txt协议、禁止Cookies、allowed_domains设置为163.com):成功抓取了想要的数据!
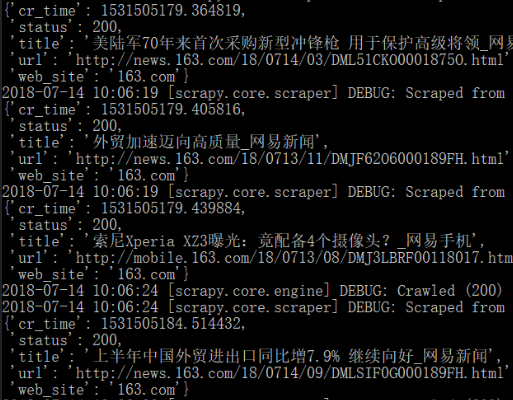
好了,问题解决了。可是,之前的疑问还是没有解决~后续再dig吧!~“神奇的”errback!~