Windows 10家庭中文版,Python 3.6.4,virtualenv 16.0.0,Scrapy 1.5.0,
使用scrapy命令行工具建立了爬虫项目(startproject),并使用scrapy genspider建立了爬虫,用于抓取某中文门户网站首页的 新闻标题及其链接,全程都在虚拟环境(virtualenv)中执行。
使用scrapy crawl执行爬虫程序并导入一个json文件,此时可以看到,命令行窗口显示的 新闻标题是中文,但在打开导出的json文件时,其新闻标题显示为以u开头的Unicode编码:
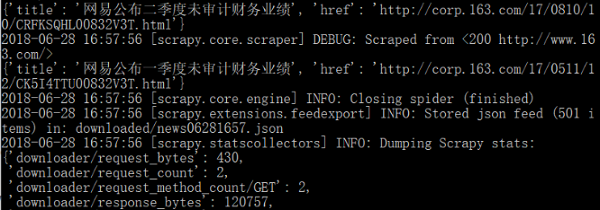
V.S.
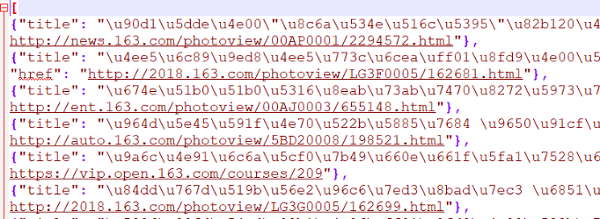
文件中的内容并非孤想要的,需要的是 显示为中文。
在胡乱地使用encode('utf-8')、encode('gbk').decode('utf-8')等代码处理后,结果问题未能解决,而且还导致爬虫程序执行发生异常。
直到发现博主“西瓜的瓜”的文章,问题才得以解决:执行scrapy crawl时添加配置 -s FEED_EXPORT_ENCODING=UTF-8。
配置项FEED_EXPORT_ENCODING的官网介绍:

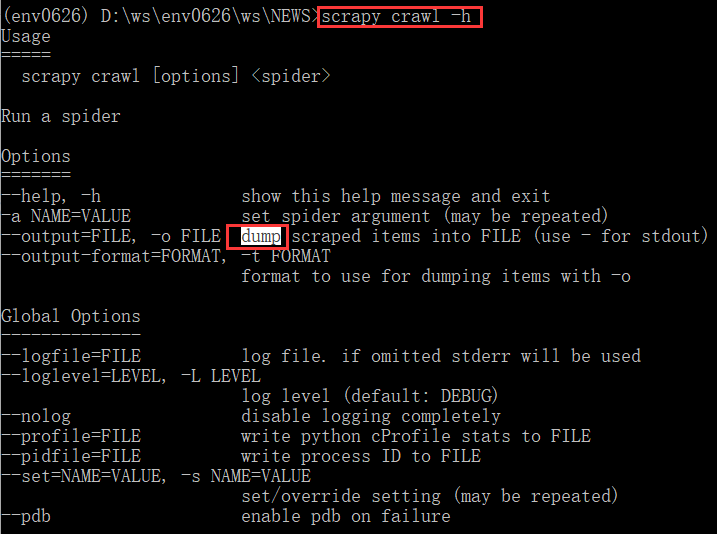
查看scrapy crawl命令的帮助信息:可以看到-o FILE选项是用的“dump”,dump这个词在json模块使用时见到过,而在json中,dump到文件中的非ASCII都被转换为以u开头的形式。不过,这个帮助信息里面没有说怎么更改或设置。
直到今天(30日)看了Scrapy的Settings文档才对此问题有了更透彻的了解:
给爬虫或爬虫项目添加FEED_EXPORT_ENCODING配置项即可解决问题,这个配置项可以是 命令行级别的(最高)、项目级别的、爬虫级别的;默认情况下,在任何一个地方做了配置,使用-o时输出的文件都会按照这个配置来进行编码。
在西瓜的瓜的博文中,是在命令行中进行设置,最高的优先级(方法一)。
今天尝试了在 爬虫项目 的配置文件settings.py中进行设置,也是可以得到想要的结果的(方法二):此时不需要在命令行中添加FEED_EXPORT_ENCODING选项了。
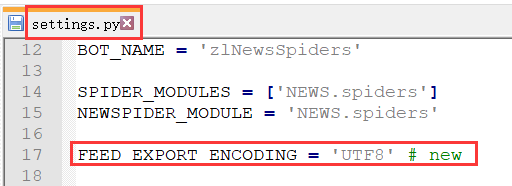
当然,还有方法三、四、五,就不多说了,大家可以仔细看Scrapy的Settings文档。
后记
怎么设置这个到处的编码是best practices呢?设置到哪一级别?是否需要设置?
在本文的示例中,如果不设置的话,Python读取导出的文件时,使用json的loads也是可以获得正确的内容的。
怎么用代码解决这个问题呢?如果使用命令行的-o的话,无法解决,只有通过自己打开、存储内容的方式解决。
在测试过程中,孤还尝试将配置写到项目的scrapy.cfg中,当然,这是错误的。