本文基于Python 3.6.5的标准库文档编写,罗列了英文文档中介绍的所有内建函数,并对其用法进行了简要介绍。
下图来自Python官网:展示了所有的内置函数,共计68个(14*4+12),大家可以根据需要查询相应函数的具体用法。

内置函数简述
abs(x)
返回数字的绝对值,可以是整数或浮点数;
如果是复数,返回复数的模数(magnitude),比如,2+2j的模数是2.8284271247461903。
all(iterable)
参数为可迭代对象(iterable),如果可迭代对象中的元素全部判断为True,返回True,否则,返回False。
any(iterable)
参数为可迭代对象,只要可迭代对象中任意一个元素为True,就返回True。
ascii(object)
返回包含参数对象的可打印表述形式的字符串,对于非ASCII字符,使用x、u或U进行转义。

和repr()对比:第三条参数为“公理”时有差别

bin(x)
将一个整数转换为以“0b”开头的字符串,这个字符串是一个有效的Python表达式。
>>> bin(3)
'0b11'
不喜欢前缀“0b”,可以用format()函数进行转换。
class bool([x])
根据标准的真值测试机制,返回一个布尔值,True或者False。
class bytearray([source[, encoding[, errors]]])
返回一个新的字节数组。
bytearray类是整数(范围[0,256))的可变序列。
source参数是可选的,官网给出了几种选择:string, integer, 实现了buffer接口的对象, 可迭代对象。
没有参数时,返回一个长度为0的数组。
class bytes([source[, encoding[, errors]]])
返回一个bytes对象,整数(范围[0,256))的不可变序列。
bytes是上面的bytearray的不可变版本。
参数解释同bytearray。
bytes对象也可以直接使用字符串建立,比如,b'fsdf'就是一个bytes对象,具体方法请参考String and Bytes literals。
callable(object)
检查object是否可以被调用,是的话,返回True。
注意两点:
类似可以被调用的,返回True;
类要是定义了__call__()方法,那么,其实例返回True。
chr(i)
返回表示一个字符的字符串(Python中没有专门的字符类型),这个字符的Unicode码点值为i。
比如,chr(97)返回'a',char(8364)返回'€'。
和chr(i)相反的函数为ord()。
i的范围:0 到 0x10FFFF(1,114,111),超出范围时产生ValueError异常。
@classmethod
在类定义里面使用,用于定义类函数。
类函数的第一个参数默认为类,可以用于修改类变量。
类函数可以被类名和类实例名调用。
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
将source编译为code或AST对象。code对象可以被exec()或eval()执行。
source可以是普通字符串、字节字符串 或 AST对象(ast模块有更多信息)。
TBD
class complex([real[, imag]])
返回一个复数,如果real、imag都存在,返回的值为real + imag * 1j,或者,将一个字符串 或 数字转换为复数。
示例:当参数为字符串时,加号前后不能有空格!

delattr(object, name)
删除object中名称为name的属性。
示例:delattr(x, 'foobar'),效果同del x.foobar。
属性不存在时,产生异常AttributeError。
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
创建一个新的字典。
dir([object])
没有参数时,返回当前本地域包含的名称的列表。
存在参数时,获取object的有效属性列表。
对象若拥有魔法方法__dir__(),那么这个方法被调用,并返回一个属性列表。
还涉及到定制魔法方法__getattr__()、__getattribute__()等,不再赘述。
用法推测:可以使用这个方法查找对象或类的所有或定制开放的属性,并根据获得的信息执行某些操作,反射机制?应该有模块提供了获取对象或类的全部属性的方式,需要dig一番!
divmod(a, b)
a、b是数字(不是复数),此函数用于获取 被除数a 除以 除数b 的 商和余数,用元组形式返回。
a、b同为整数时,结果为(a // b, a % b);
a、b至少一个为浮点数时,结果为(q, a % b),具体规则参考下面原文:
For floating point numbers the result is
(q, a% b), where q is usuallymath.floor(a / b)but may be 1 less than that. In any caseq * b + a % bis very close to a, ifa % bis non-zero it has the same sign as b, and0 <= abs(a % b) < abs(b).
enumerate(iterable, start=0)
返回enumerate对象,其中,参数iterable必须是一个序列、迭代器 或者 其它支持迭代的对象。
start参数默认为0,用于修改获得的结果的开始序号。
示例如下(来自官网):

eval(expression, globals=None, locals=None)
eval是evaluate的缩写,有“求...的值”的翻译,也正是此函数在这里的作用,求表达式expression的值。
后面的globals、locals不是很清楚。
expression参数被解析或评估为(使用globals、locals字典作为全局和局部名称空间的)Python表达式。
在globals、locals都缺省的情况下,expression在eval()被调用处的环境中被执行。
eval是有返回值,返回的是根据expression计算得到的值。
如果expression解析出错,会产生语法错误(syntax)。
eval函数还可以用于执行任意的code对象(比如使用compile()创建的),在这种情况下,传递一个code对象而不是字符串。若是这个code对象使用模式参数“exec”编译,那么,eval()的返回值会是None。
注意:动态执行语句请使用exec()函数。
更多dig:globals、locals如何使用(globals、locals里面的名称所代表的变量可以拿到表达式中参与计算?)?eval的使用场景?TBD
示例:

exec(object[, globals[, locals]])
此函数支持Python代码的动态执行,参数object必须是一个字符串或code对象。
若是字符串,将会被解析为一系列Python语句,然后执行;
若是code对象,直接执行。
注意,return和yield语句不能被使用...(没翻译清楚,下面是原文引用)
Be aware that the return and yield statements may not be used outside of function definitions even within the context of code passed to the exec() function.
返回值为None。
关于globals、locals的使用,TBD
示例:

关于eval和exec的区别:
eval执行表达式,exec执行语句(表达式和语句的区别?);
eval返回表达式求得的值,exec始终返回为None;
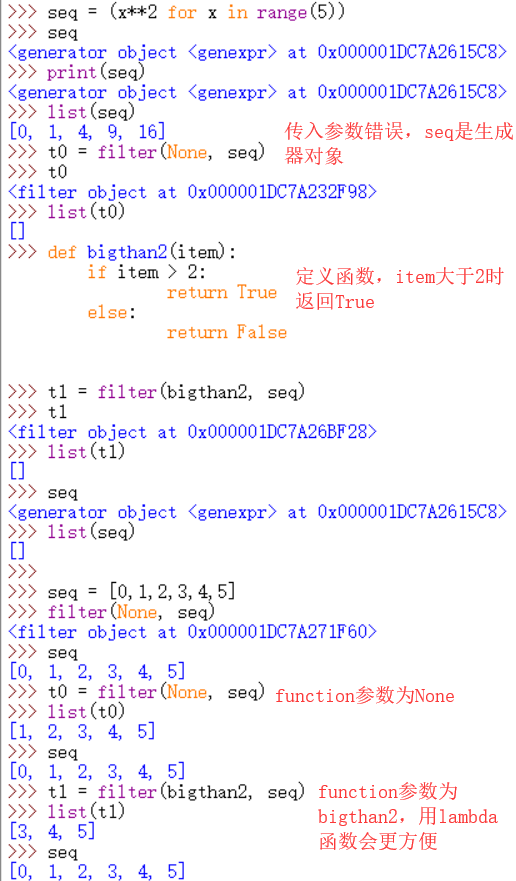
filter(function, iterable)
过滤掉(删除)可迭代对象iterable中使用function执行后返回False的元素,并构建一个新的迭代器对象。
如果function是None,则使用identify函数替代。
function不为None:(item for item in iterable if function(item))
function为None:(item for item in iterable if item)
示例:
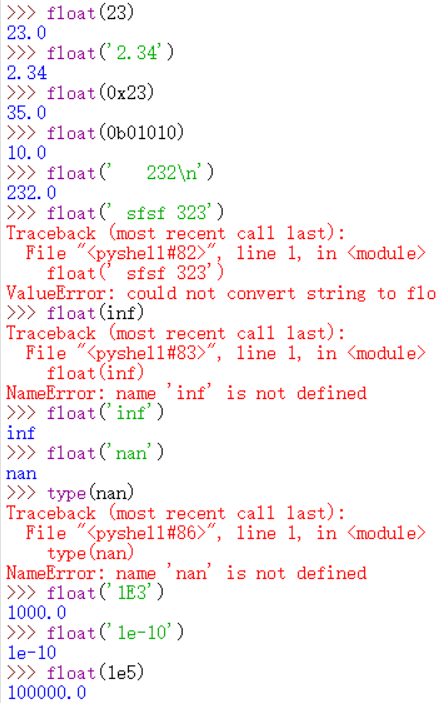
class float([x])
根据x的值返回一个浮点数,x可以是数字或字符串。
也可能返回NaN(not-a-number),或者正无穷或负无穷。
超出了Python的浮点数范围后,还会产生OverflowError异常。
链接:关于Python浮点数的定义。
不区分大小写,比如,inf、Inf、InfinitY等都被认为是正无穷。
没有参数时,返回0.0。
示例:部分来自官方,包含科学记数法
format(value[, format_spec])
将value根据format_spec进行格式化。
格式参数format_spec的解释依赖于参数value的类型,请参考Format Specfication Mini-Language。
格式参数format_spec为空时,得到的结果和str(value)相同。
class frozenset([iterable])
返回一个新的frozenset对象(内建类),其元素可以从可选参数iterable中获得。
请参考:frozenset官文
更多容器类的知识点需要参考内建的set, list, tuple, dict类,以及collections模块。
getattr(object, name[, default])
返回对象object的名为name的值,没有的话,返回默认值default,否则,产生AttributeError。
globals()
返回一个代表当前全局符号表的字典(对于函数或方法来说,返回值为其定义所在的模块,而非调用的模块,固定的)。
hasattr(object, name)
检查对象object是否有名为name的属性。
hash(object)
返回对象object的hash值。
相等的数字会有相同的hash值,即便其类型不同,比如,1和1.0。
注意:对于定义了__hash__()方法的对象,hash()函数会基于主机的位宽缩短(truncate)其返回值,请参考__hash__()。
help([object])
调用内建的help系统,和交互式控制台的help用法相同。
如果参数为空,则会启动一个交互式控制台。
hex(x)
将一个整数转换为以“0x”开头的使用小写字母组成的16进制表示的字符串,比如,hex(255)返回'0xff',hex(-42)返回'-0x2a'。
如果参数x不是整数,那么,它需要定义__index__()方法并返回一个整数才可。
如果有更多格式转换需求,可以使用%、format 或 f‘{...}’ 的方式进行转换。
id(object)
返回对象object的identify(特征?),是一个整数,在对象object的生命周期中保证唯一性的常量。
在CPython中,这个值为对象在内存中的地址。
input([prompt])
执行后,在控制台输出提示prompt(也可以为空),用户再输入一行(A LINE),回车,此时,input读取用户输入的一行内容并将之转换为字符串返回。
更多:可以和readline模块配合使用,以提供精细化的行编辑和历史记录功能,TBD。
class int(x=0)
class int(x, base=10)
根据传入的数字参数或字符串,返回一个整数,没有参数时,返回0。
对象x定义了__init__(),返回x.__init__()。
对象x定义了__trunc__(),返回x.__trunc__()。
对于浮点数,返回靠近0的结果,比如,int(1.5)返回1,int(-1.5)返回-1。
关于base参数:
有base参数时,x必须为字符串、bytes 或 bytearray实例。
一个base为n的文本包含数字0到n-1(a/A到z/Z表示10~35,因此,n最大为36)。
base默认为10,可选值为0和2~36。
base为2、8、16时,数字可以选择用0b/0B、0o/0O、0x/0X开头。
base为0时,表示按照代码文本进行解析,请参考下面原文(在示例测试后,发现base为0时,智能解析2、8、10、16进制的数据):
Base 0 means to interpret exactly as a code literal, so that the actual base is 2, 8, 10, or 16, and so that int('010', 0) is not legal, while int('010') is, as well as int('010', 8).
示例:

请参考Numeric Types — int, float, complex。
isinstance(object, classinfo)
如果对象object是classinfo类或其子类(直接、间接继承,Okay,but 虚拟继承(virtual)呢?)的实例,返回True。
如果classinfo是一个type对象的元组,只要object是其中一个type对象的实例就返回True。
如果classinfo是其它参数,产生TypeError。
issubclass(class, classinfo)
判断class是否为参数classinfo定义的类信息的子类,classinfo参数的解释同上面的isinstance()函数。
在Python中,一个类可以被认为是它自己的子类,返回True。
iter(object[, sentinel])
返回一个迭代器对象。
第一个参数会因为第二个参数的存在而有非常不同的解释。
当第二个参数不存在时,object必须是一个支持迭代协议(__iter__())的集合对象,或者必须支持序列协议(__getitem__()方法的整数参数需要从0开始),否则,产生TypeError。
当第二个参数存在时,object必须是一个callable对象,此时将创建一个迭代器并不使用参数的方式调用object,每次调用会执行其__next__()方法,如果返回的值等于sentinel(翻译:岗哨、哨兵),StopInteration会产生(这段翻译的有些问题,TBD)。
使用第二个参数的一个很有用的场景是 读取文件的每一行,示例如下——来自官网:
1 with open('mydata.txt') as fp: 2 for line in iter(fp.readline, ''): 3 process_line(line)
更多参考:迭代器类型 官文
len(s)
返回对象s的长度——包含的元素的数量。
参数s可以是一个序列(string, bytes, tuple, list, range) 或 collection容器(dictionary, set, frozen set)。
class list([iterable])
返回一个序列类型list——可变的序列类型。
locals()
更新并返回一个代表当前本地标志表的字典。
当它在一个函数块中(不是类块)被调用时,free variables(是什么?)也会被返回。
注意:返回的字典的内容不应被修改;修改不会影响解释器中使用的本地和free变量的值。
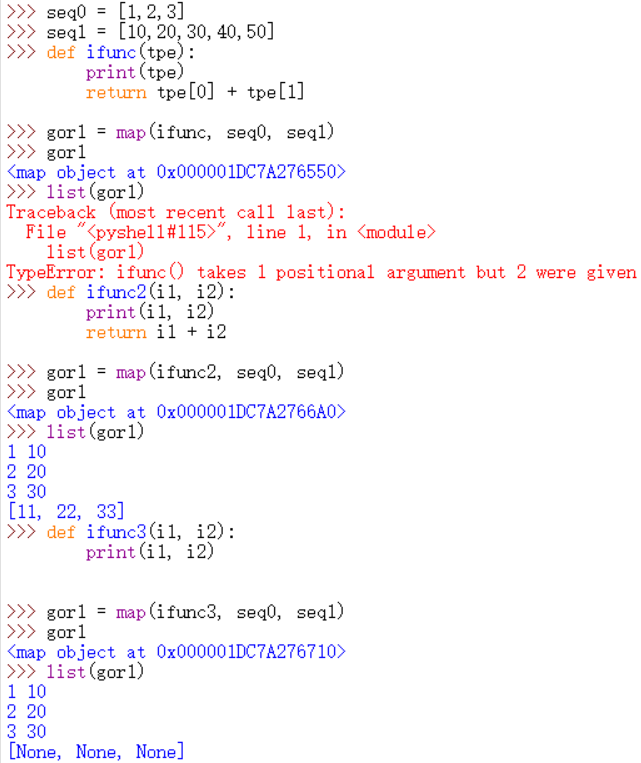
map(function, iterable, ...)
对可迭代对象iterable中的元素执行一次函数function,然后返回一个包含执行后的元素的生成器。
可以提供多个可迭代对象,但相应的function就需要多个参数来匹配,迭代会以最短的可迭代对象为准。
函数function的输入参数已经被安排为 元组 了?参考官文:
For cases where the function inputs are already arranged into argument tuples, see itertools.starmap().
示例:
max(iterable, *[, key, default])
max(arg1, arg2, *args[, key])
返回可迭代对象iterable中的最大的元素,或者,2个或更多参数中最大的参数。
两个可选的关键词参数——key、default,key指定一个排序安苏,default指定一个对象在iterable为空时返回。
如果iterable为空,但没有指定default,产生一个ValueError。
如果有多个最大值,返回第一个——这与其它的一些排序函数的做法一致。
memoryview(obj)
返回obj的一个memory view对象(是什么,有什么用?),请参考Memory View。
这个obj的类型还是有要求的,下面是一个测试时发生的错误:
TypeError: memoryview: a bytes-like object is required, not 'list'
只接受bytes-like的对象。
min(iterable, *[, key, default])
min(arg1, arg2, *args[, key])
返回最小值。
相关解释可参考上面的max()函数。
next(iterator[, default])
返回迭代器的下一个值——通过调用其__next__()方法。迭代器的值耗尽时,如果default存在,则返回default的值,否则产生StopIteration。
class object
object类,所有类(包括type类)的基类。
注意,object类没有__dict__属性,因此,不能给它的实例指派任何属性。

oct(x)
把一个整数转换成以“0o”开头的八进制的字符串。
返回值是一个有效的Python表达式。
x不是int对象时,它必须定义一个__index__()方法并返回整数。
和hex、bin一样,可以使用%、format、f'{...}'进行格式化。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
哇哦,原来open(...)函数可以有这么多参数啊!
打开文件,会那会相应的file对象。如果文件不能被打开,产生OSError。
file参数:一个类似文件路径的对象(绝对路径 或 相对于当前工作目录的路径(os.getcwd()可得)),或者,一个将被包装起来整数文件描述符(FD)(如果给的是FD,那么,文件将在返回的I/O对象被关闭时关闭,除非closefd被设置为False)。孤目前就用过路径。
mode参数:r, w, x, a, b, t, +,更详细信息见官文,默认是r(rt)。
文件以二进制(b)模式打开时,返回的是没有任何decoding的bytes对象;在文本模式时(r),返回str,bytes也按照平台相关的或者指定的编码协议解码。
注意:Python不会依赖底层操作系统的文本文件的概念,所有的处理都是由Python自己搞定,所以它是平台独立的。
buffering参数:可选,设置缓存策略。0表示关闭缓存。1表示选择行缓存——在text模式有用。大于1表示指定缓存大小——字节长度。
没有buffering参数时,默认的缓存策略如下:
二进制文件使用fixed-size chunks进行缓存,相关参数io.DEFAULT_BUFFER_SIZE,通常为4096或8192字节;
交互式文本文件(不懂,isatty()返回返回为True)的使用行缓存,其它文本文件使用和二进制文件相同的策略。
encoding参数:编解码文件内容的编码协议,默认和平台相关,请参考codecs获取完整的编码协议信息。
errors参数:指明了编解码错误要怎么处理——在二进制模式下不可用(一些标准的错误处理请参考Error Handlers),虽然错误处理名称可以使用codecs.register_error()注册,但标准的名称有:strict, ignore, replace, surrogateescape, xmlcharrefreplace, backslashreplace, namereplace等。
newline参数:TBD
closefd参数:TBD
opener参数:TBD
新创建的file是不可(被子进程)继承的(non-inheritable)。
还有更多文件处理模块,比如,fileinput, io, os, os.path, tempfile和shutil。
ord(c)
chr()函数的逆过程,返回给定字符串(包含一个字符的字符串)的Unicode码点,比如,ord('a')返回97,ord('€')返回8364。
pow(x, y[, z])
pow(x,y):返回x的y次方,等于x ** y;
pow(x,y,z):返回x的y次方再对z求模,效率比pow(x, y) % z更高。
关于参数类型,这部分有些复杂:
必须都是数字类型(numeric types);
对于不同的类型,使用强制转换(coercion rules)为更高精度的;
对于int型操作数,结果和操作数类型相同,除非第二个操作数为负数,在这种情况下,所有参数被转换成浮点数,并且浮点数结果将产生,比如pow(10,2),返回100,pow(10,-2),返回0.01;
在第二个参数为负数时,第三个参数必须被忽略;
如果z存在,x、y必须是整形,并且y必须为非负数,0肯定也不行的(官方文档没说不能为0,但程序里面是禁止了的);
print(*objects, sep=' ', end='
', file=sys.stdout, flush=False)
将1个或多个对象输出到文本流文件(参数file,默认为标准输出)中,使用参数sep定义的分隔符和参数end的结束符。
sep, end, file 和 flush参数如果存在的话,必须使用关键字形式(因为第一个参数为*objects)。
所有的非关键字参数都会被转换字符串(类似str()函数做的),并被写到文本流中。
没有objects时,print()输出参数end。
file参数必须是一个有write(string)方法的对象,默认为sys.stdout。
print()不能用于二进制模式文件对象!
输出是否缓存通常是由file决定的,但如果参数flush设置为True,文本流会被强制flushed。
Done!
class property(fget=None, fset=None, fdel=None, doc=None)
Return a property attribute. (property、attribute都可以翻译成属性,这句怎么翻译呢?)
其实,这是一个装饰器函数,用于将类中的一些函数指定为某个属性的获取fget、设置fset、删除fdel、文档描述doc函数。
官文例子:定义了一个x属性,getx, setx, delx都是类中定义的函数。
x = property(getx, setx, delx, "I'm the 'x' property.")
上面的函数执行后,即可使用instance.x获取x的值,instance.x = value设置值,del instance.x删除属性x。
对于doc参数,如果没有给出,就会使用fget函数的文档字符串来替代。
@property装饰器使用 官文示例:
1 class C: 2 def __init__(self): 3 self._x = None 4 5 @property 6 def x(self): 7 """I'm the 'x' property.""" 8 return self._x 9 10 @x.setter 11 def x(self, value): 12 self._x = value 13 14 @x.deleter 15 def x(self): 16 del self._x
在孤看来,__init__()函数中的self._x = None这句很关键,不能丢——丢了会怎样?还可以使用@property吗?
请看官文,讲解的很清楚了。
range(stop)
range(start, stop[, step])
这个函数经常出现并用到。
实际上呢,range是一个不可变序列类型。
更多信息参考Ranges。
repr(object)
返回一个对象的可打印表示的字符串。
对于很多类型,这个函数会尝试返回一个字符串,这个字符串会生成一个传递给eval()函数时获取的相同值的对象(翻译有问题,请看引用:this function makes an attempt to return a string that would yield an object with the same value when passed to eval()),否则,表达式将包括一对尖括号(angle brackets)括起来的字符串,包含对象的类型已经额外的名称、地址等信息。
一个类可以控制这个函数的返回值,只要定义了魔法方法__repr__()即可。
示例:

reversed(seq)
返回一个反向迭代器。
参数seq必须有包含一个__reserved__()方法,或者支持序列协议。
round(number[, ndigits])
返回一个小数点后ndigits精度的数,类似于四舍五入,但不同之处是:
round()函数并不是用的四舍五入法,而是在一个数距离最接近的两个整数相同的情况下,选择偶数返回(但浮点数的使用有些不同)。
ndigits默认为None,返回的数为整数,任意整数值都可以——整数、0、负数。
返回值默认为整数——ndigits为None,否则,返回值的类型和number相同。
示例:

class set([iterable])
返回一个新的set对象,可以选择从可迭代对象iterable中获取元素。
set是一个内建类,请参考Set Types -- set, frozenset。
setattr(object, name, value)
getattr()函数的最佳搭档!
设置参数object的已存在属性的值,或者,给实例添加一个新属性。
疑问,给实例添加一个新属性有什么用呢?序列化、反序列化后可以得到这个属性?应用场景是?
class slice(stop)
class slice(start, stop[, step])
中文一般翻译为 分片,但一般不使用这个函数的,直接使用序列对象 和 中括号里面的start、stop、stop解决问题,后台,或许会调用此函数。
返回一个 由range(start, stop, step)函数指明序号的集合 slice对象(翻译有问题)。
参数start、step默认为None。
slice对象拥有start, stop, step属性,它们没有其它明确的功能,但是,它们会被Numerical Python和其它第三方扩展使用。
slice对象也会在扩展序号语法(extended indexing syntax)被使用时产生,例如,a[sart:stop:step] 或者 a[start:stop, i]。
查看itertools.islice()官文可以找到一个返回迭代器的替代版本。
sorted(iterable, *, key=None, reverse=False)
返回一个参数iterable中元素的排序后的列表。
第二个参数时一个星号(*),什么意思?
有两个可选的参数——key、reverse,必须指明是关键字参数。
key指定一个只有一个参数的函数,这个函数用于从每一个列表元素中提取一个比较关键字,比如,key=str.lower。默认为None,直接比较元素。
reverse是一个boolean值。如果为True,将对没有设置时的结果进行反转。
使用functools.cmp_to_key()去转换旧的cmp函数为key函数。
内建的sorted()函数保证是稳定的。排序是稳定的是指,它能保证不改变比较后相等元素的相对顺序——这是很有用。
更多资料请查看Sorting HOW TO。
@staticmethod
将一个函数变为静态函数。在类的内部使用,静态函数不用接受默认的第一个参数(相对于实例函数、类函数而言)。
静态函数可以被类名和类实例调用。
和所有装饰器一样,像普通函数一样调用staticmethod也是可以的,并对其返回结果做一些什么。在某些情况下,这是有需要的。比如,你需要类里面一个函数的引用,并且想要避免其自动转换为实例方法,此时,使用下面的用法(还是不完全清楚):
class C: builtin_open = staticmethod(open)
更多信息请参考The standard type hierarchy。
class str(object='')
class str(object=b'', encoding='utf-8', errors='strict')
返回对象的str版本,更新信息参考str()。
sum(iterable[, start])
求和,从start开始,start默认为0,顺序,从左到右(小index到大index)。
iterable的元素通常为数字,start不能为字符串。
对于某些用例,有更好的替代方法:
把一个序列合并成字符串可以调用''.join(sequence);
为浮点数添加扩展精度,math.fsum();(没搞懂)
把一系列的可迭代对象链接起来,itertools.chain()。
super([type[, object-or-type]])
返回一个代理对象,这个代理对象代理了 父类 或者 type的兄弟姐妹类(后面这个没搞懂)的方法调用。
在访问已被重写的、继承的方法时很有用。搜索的顺序和getattr()函数相同,除了type本身被忽略了。
type的__mro__列出了getattr()和super()的解析查找顺序,这个属性是动态的,而且可以在任何继承结构被更新时改变。
如果第二个参数没有制定,那么,返回的super对象时unbound。如果第二个参数时一个对象,isinstance(obj, type)必须是True。如果第二个参数是一个type,那么,issubclass(type2, type)必须是True。(有什么用?)
两个super的应用场景:单继承、多继承。
在单继承情况下,super可以被用于应用父类而不用明确地指明它们,这使得代码更具有可维护性。这和一些其它语言中的使用情况非常相似;
在多继承情况下,TBD(太多了,再研究吧)。
注意,super()是作为绑定过程的一部分实现的,用于明确地使用点号查找属性,比如super().__getitem__(name)。它通过实现它自己的_getattribute__()方法用可预测的顺序(支持多继承)查找类而实现。因此,super()使用语句或操作数(如super()[name])等隐含查找是没有定义的。
还要注意,除了没有参数的形式外,super()没有被限制使用内部方法。(未翻译完成)
更多内容请参考guide to using super()。
读完后,还是只会用super()获得父对象,然后调用其方法,当然还知道了有其它形式,但没用过,所以,不知所以。
tuple([iterable])
使用iterable的元素构建一个元组并返回,不仅仅是一个函数,还是一个不可变的序列类型。
class type(object)
class type(name, bases, dict)
只有一个参数时,返回object的类型,返回值是一个type对象,通常和object.__class__相同。
有3个参数的版本,返回一个新的type对象,可以认为是class语句的动态版本——新建类。name参数是字符串,表示类名称,会变为__name__属性;bases元组包含了新类的基类,会变为__bases__属性;dict字典属性包含类体重包含的定义——方法和属性,会被拷贝到标准的字典类型中,并成为__dict__属性。
type,也叫元类,定义类的类。
更多内容,请参考官文Type Objects。
3.6版本更新提示:type的子类不会重写type.__new__,那么,它们将不能使用一个参数的形式去获取一个对象的类型。
vars([object])
返回一个模块、类、实例或其它有__dict__属性的对象的__dict__属性。
模块和实例等对象拥有可更新的__dict__属性,但是,其它对象可能对__dict__属性有写入限制。
没有参数的vars()表现类似locals()。
注意,locals字典仅在更新被忽略时有用(翻译的有些问题,请看引用)。
Note, the locals dictionary is only useful for reads since updates to the locals dictionary are ignored.
zip(*iterables)
这个函数也是最早接触的函数。
它使用iterables中的元素进行聚合以制造一个迭代器对象返回,一个多个元组的迭代器。
没有参数时,返回一个空的迭代器。
当可迭代对象的元素数量不相等时,以最少元素的可迭代对象为准,其它的多余的会被忽略。
zip()和星号(*)操作符结合,可以执行unzip操作。
示例:

__import__(name, globals=None, locals=None, fromlist=(), level=0)
这个函数被import语句调用。
直接使用__import__()是不建议的,可以使用importlib.import_module()。
此函数更多内容就不说了。
注意事项
1.官网介绍的round()函数并不是用的四舍五入法,而是在一个数距离最接近的两个整数相同的情况下,选择偶数返回;
rounding is done toward the even choice
后记
从昨天开始,今天终于写完了。
好费时啊!而且,由于水平问题——英文和Python语法语义的理解,文档质量并不高。
希望后续继续努力吧!
对于这些内建函数,熟悉了总是好的,其中某些函数都可以单独拿出来写一篇博文的,再配上一些示例。
但还有更多需要熟悉的。
时间宝贵,要重点突破。