2010年IEEE Secon的一篇文章。当然了,应该是之前就写好了,发表过,还是直接投到Secon了呢?直接投的吧,Secon不接受已发表过的吧。
本文的着笔点:有线网与DSAN(启用了DSA特性的WLAN)集成的情况下的TCP性能研究。就是DSAN网与传统网路通信时,其整体的TCP性能研究。场景就是“最后一英里”,典型的可以想象的是,家里的光纤到户,连一个BS,然后呢,所有的手机、PAD、Laptop等终端都通过BS上网。而这部分无线节点都启用了DSA特性,那这就是一个典型的本文要研究的一个场景。
有线——BS(负责有线网与DSAN的通信)——DSAN
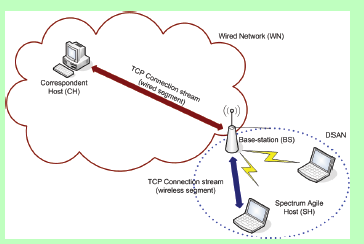
好了。本文就是研究这种情形下,TCP的性能受到那些因素影响、并提出方案解决(DSASync)、再实验验证提出的方案就是好,这样一篇文章。
第一:TCP受那些影响呢。前一篇博文中提到过。这里只说,对无线网而言,主要是高误码率(high bit-error),当然已经研究的差不多了,所以不用担心。DSA中的TCP受哪些影响呢,时延和丢包(由DSA的基本操作引起的,如频谱嗅探、信道切换等等)
第二:文章重心在于提出的DSASync方案。其实就是链路层协议,利用缓存和流量控制(buffering、traffic-shipping)来给TCP做预处理。有两个模块,一个用于从DSA MAC/PHY协议收集参数、向上传递(DSASync_LL模块),一个接受参数,作分析决策(DSASync_TCP模块);然后才向上层传递给传输层的TCP协议。
注:DSASync是部署在BS上的,DSAN内部节点并没有部署(但正如文章future work所提出的,在以后的工作中,会尝试给每个节点部署DSASync,做成分布式)
重点说作决策的模块DSASync_TCP,这是核心所在。它自身又可以分为三个模块。
1、DSASync_TCP_CH-SH,就是管理从有线到DSAN网路的下行流量。它的输入是从DSASync_LL模块传入的参数,做决策的算法有两个,一个是根据参数决定包是被缓存还是被加入到传输队列,考虑的因素包括剩余缓存的大小、是否处于静默期等等;另一个算法是判断是否发送rwin=0(tcp的receive window)给CH,这样就可以达到控制流量的目的。
(这里可以有代码)
2、DSASync_TCP_SH_CH,就是上行流量。它核心的工功能是:把上行的包,均匀分配,在静默期也可以保持向CH发包,而不至于中断或有较大延迟。因为在静默期,整个DSAN内部是不能发包的,这时,BS可以依旧利用本地缓存的包,继续向CH发包。这样保持了上行线路的平稳。不至于在静默期触发CH端TCP的重发机制而导致信道利用率降低。
3、DSASync_TCP_CAP,这个是拥塞控制,主要发生在信道切换时。这个时候,信道的容量(capacity)可能会发生大幅的下降,而这一点,TCP是无法处理的。(传统情形下,TCP不会遇到信道性能经常出现很大起伏的情况,因而在出现小的起伏时,TCP只须重传即可。并不会持续很久,且浪费信道利用率。但在DSAN中信道切换时,大的信道性能起伏就会出现,这一点TCP协议中并没有做处理)。而解决方案也很简单,正如DSASync设计的那样,在判断出新的信道性能不能满足需求时,模块会传递给sender 3个重复的ACK,这样就触发tcp的快重传机制,cwin降为一半,而不是直接降为1(如果BS不发送3个重复的ACK,而receiver又无法返回确认信息(因为信道性能大幅下降),则导致sender TCP的慢恢复,cwin直接降为1),这样其实就减弱了信道切换对TCP性能的影响。
(这里可以有代码)
注:DSASync_TCP_CH_SH其实只对下行流量做处理即可。因为在发生信道切换导致的信道性能降低时,处于DSAN的上行流量本身就直接受到影响了,因为不需要去单独“警告”或通知。就好像从一条大路连着一条泥泞小道。从大路开过来的车,你要通知他,前方是小路,要开慢点;而从小路开向大路的车,你不用管他,因为它自己就在小路上呃,根本就开不快。。。
第三:实验效果
先说下实现(implementation),本文作者是把DSASync做成了linux kernel的一个模块,利用了强化的(启用了DSA特性的)The MadWifi device driver。
然后是实验设备参数:
6个laptop(SHs)无线网卡是Atheros-based Linksys WPC 55AGwireless card.
另一个laptop(AP)充当BS,连接有线网和DSAN。
还有个laptop,充当PU(incumbent transmitter),起干扰的角色。
Iperf产生TCP traffic,TCPdump用来观察记录。
PHY data-rate 24Mbps,AP buffer capacity 500M,
平均信道利用率20%(incumbent channel utilization)
SH的平均嗅探开销5%(sensing overhead)
初始的TCP send receive window 256KB
每个实验持续20s
其他。。。
性能度量:
1、主要的,应用层的throughput
2、从接受端观测到的端到端时延。
好了,现在是实验结果:
1.微观上(Microbenchmarks)四个


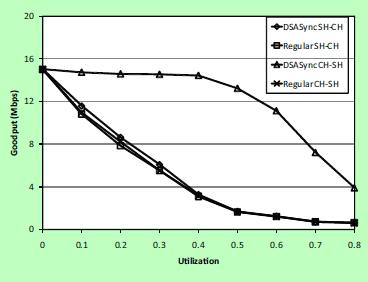

实际吞吐率和重发比率:
DSASync CH-SH有74%的显著提升。
端到端时延:
DSASync SH-CH有很明显的改善。
存在PU干扰情形下的吞吐率:
DSASync CH-SH有很好的表现。
PHY性能变化时的吞吐率:
DSASync CH-SH is good。
2、宏观上(Macrobenchmarks):scalability
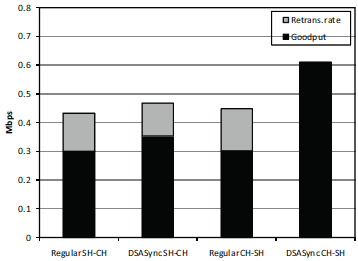
参数:6个终端,各开4个TCP连接,频谱共有4个信道
DSASync CH-SH 有明显优势。
注:从上面的结果我们看到,DSASync的优势主要体现在了CH-SH上吞吐量的提升、或在恶劣情形下依旧保持较好的性能。主要原因在于BS可以对CH-SH的流量做出调整,从而影响这个方向上的TCP性能。而从SH-CH,DSASync唯一做到的是在静默期依旧发包,这样在试验中端到端时延这一指标上,做出了明显改进(在这一指标上只有它显示了明显改进),SH-CH也仅在这一指标上显示了优势。其他三个指标上表现一般,因为部署在BS上的DSASync无法对DSAN内部的网络情况做任何改进,它只是在边界上起调节作用,因为更多的是起到了辅助CH的作用,故而在CH-SH上在三个指标上都有明显优势。(future work考虑在DSAN内部每个节点部署DSASync就是考虑到要提升SH-CH的性能,单靠BS是无法实现的,因为无法对DSAN内部网路做出改变。)
第四:future work
正如上面注释提到的,第一个future work就是做成分布式的DSASync,以期在SH-CH线路上做出明显改进。
第二个是横向拓展。对UDP进行优化(UDP、不可靠传输、主要用于多媒体传输)。