目的:
1.描述性统计分析
2.频数表和;列连表
3.相关系数和协方差
4.t检验
5.非参数统计
在上一节中使用了图形来探索数据,下一步就是给出具体的数据来描述每个变量的分布和关系
1.描述性统计分析
探究案例:各类车型的油耗如何?对车型的调查中,每加仑汽油行驶的英里数分布是什么形式(均值,标准差,中位数,值域等)
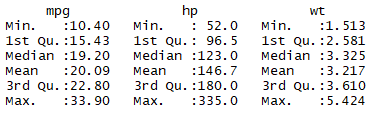
1.1使用内置的summary函数来获取最小值,最大值,四分位数和数值型变量的均值
1 myvals <- c('mpg','hp','wt') 2 head(mtcars[myvals]) 3 summary(mtcars[myvals])
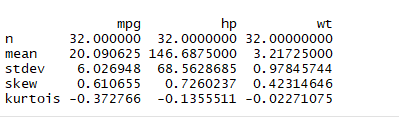
1.2.使用sapply和自定义函数计算描述性统计量
计算均值,长度,偏度,丰度
1 mystats <- function(x,na.omit=F){ 2 if(na.omit){ 3 x <- x[!is.na(x)] 4 } 5 m <- mean(x) 6 n <- length(x) 7 s <- sd(x) 8 skew <- sum((x-m)^3/s^3)/n 9 kurt <- sum((x-m)^4/s^4)/n-3 10 return(c(n=n,mean=m,stdev=s,skew=skew,kurtois=kurt)) 11 } 12 myvals <- c('mpg','hp','wt') 13 sapply(mtcars[myvals], mystats)
1.3第三方包实现描述性统计分析
1 library(Hmisc) 2 describe(mtcars[myvals])

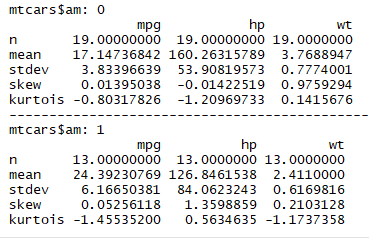
1.4分组计算描述性统计量
# by()第一个参数数数据集,第二个参数是要分组的项,第三个参数是要执行的统计函数
1 dstats <- function(x){sapply(x, mystats)} 2 by(mtcars[myvals],mtcars$am,dstats)
2.频数表和列连表
探究案例:在进行新药试验后,用药组和安慰剂组的治疗结果相比如何?实验参与者的性别是否对结果有影响?
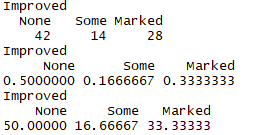
2.1一维列联表
1 library(vcd) 2 # 使用table韩式生成频数表 3 mytable <- with(Arthritis,table(Improved)) 4 mytable 5 # 转化成比例值 6 prop.table(mytable) 7 # 转化成百分比 8 prop.table(mytable)*100
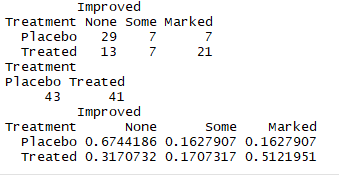
2.2二维列联表
结论:与接受安慰剂的治愈率16%相比,使用特效药的治愈率达到了51%
# 使用xtab函数实现多变量频数
1 mytable <- xtabs(~ Treatment + Improved,data = Arthritis) 2 mytable
# 下标1表示mytable数据集的第一个变量 3 margin.table(mytable,1) 4 prop.table(mytable,1)
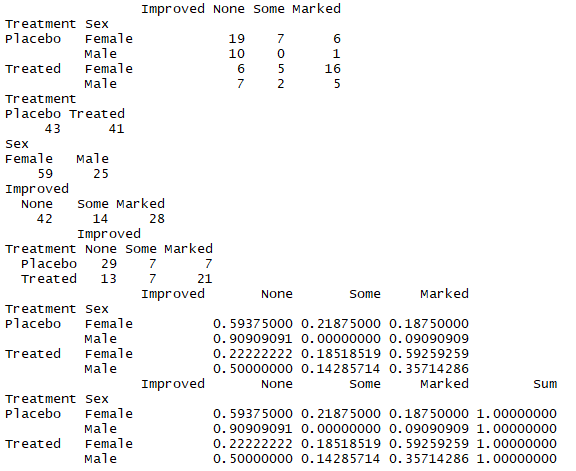
2.3多维连列表
结论:在治疗组中男性有36%的改善,女性有59%的改善,说明性别对于药效有影响
1 mytable <- xtabs(~ Treatment+Sex+Improved,data=Arthritis) 2 mytable 3 ftable(mytable) 4 # 计算单独变量的编辑频数 5 margin.table(mytable,1) 6 margin.table(mytable,2) 7 margin.table(mytable,3) 8 # 治疗情况和改善情况的边际频数 9 margin.table(mytable,c(1,3)) 10 # 治疗情况和性别的改善情况比例 11 ftable(prop.table(mytable,c(1,2))) 12 ftable(addmargins(prop.table(mytable,c(1,2)),3))
3.相关
探究案例:收入和预期寿命的相关性如何
3.1使用cor.test()来查看两个变量是否相关接近1为正相关,接近-1位负相关,接近0无关
1 cor.test(states[,3],states[,5])
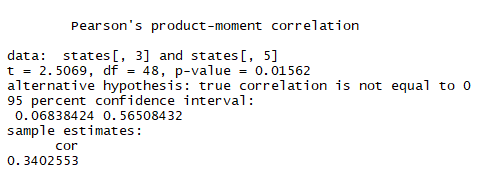
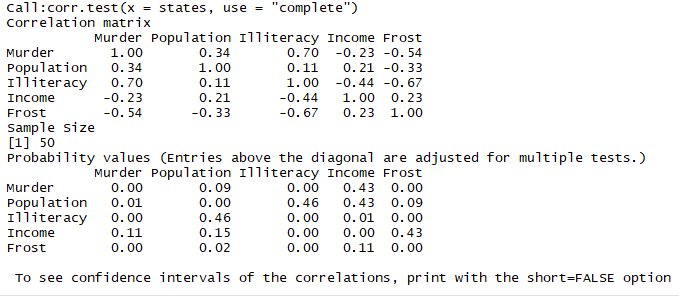
3.2查看多个变量之间的相关性
结论:谋杀率与文盲率是最大的相关变量,与天气是最小的相关变量
1 library(psych) 2 corr.test(states, use="complete")
4.t检验
4.1 独立样本t检验
探究案例:如果你在南方犯罪,是否更有可能被判监禁?
结论:是的,在南方犯罪更容易判监禁
1 library(MASS)
# 在以下的代码中,使用了双马尾t检验,生成了南方group1和非南方的group0的值 2 t.test(Prob~So,data = UScrime)

4.2 非独立样本t检验
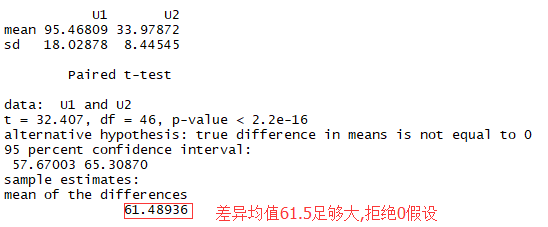
探究案例:年轻男性的失业率是否要比年长男性要高
结论:年轻男性的失业率高于年长男性
1 sapply(UScrime[c('U1','U2')], function(x){c(mean=mean(x),sd=sd(x))}) 2 with(UScrime,t.test(U1,U2,paired = T))
5 组间差异的非参数校验
5.1两组的比较
结论:和4.1,4.2的结论相同
1 # 使用wilcox函数秩和检验 2 with(UScrime,by(Prob,So,median)) 3 wilcox.test(Prob ~ So,data=UScrime) 4 5 sapply(UScrime[c('U1','U2')],median) 6 with(UScrime,wilcox.test(U1,U2,paired = T))
5.2大于两组的比较
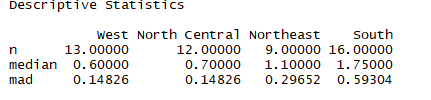
案例探究:比较美国四个地区的文盲率是否相同
结论:四个地区的文盲率不同,南部文盲率最高,北部最低
1 state <- data.frame(state.region,state.x77) 2 kruskal.test(Illiteracy~state.region,data=states)

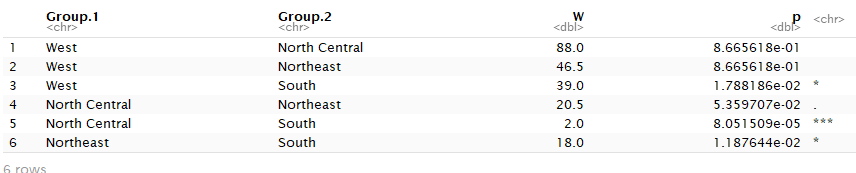
5.3自定义远程函数处理多组因子
source('http://www.statmethods.net/RiA/wmc.txt') state <- data.frame(state.region,state.x77) # wmc是在远程服务器的自定义函数 wmc(Illiteracy~state.region,data=states,method='holm')