核心思想
- 将方法和Lambda作为一等值,以及在没有可变共享状态时,函数或方法可以有效、安全地并行执行
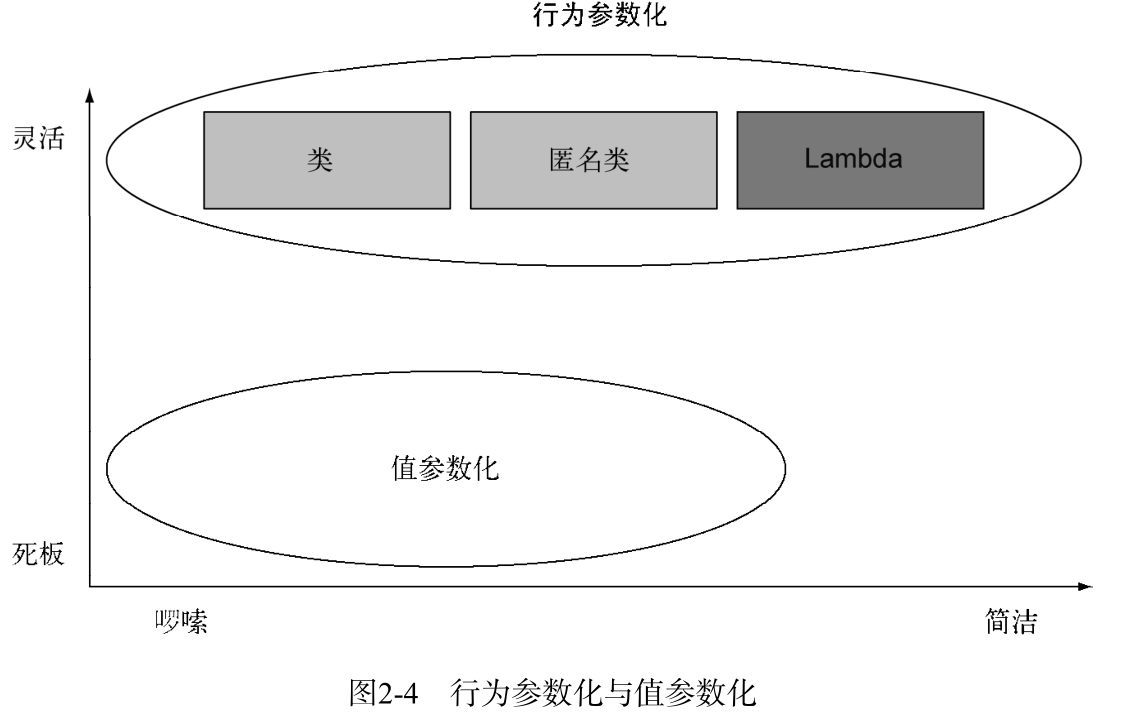
方法的行为参数化
- 具体参数化为抽象。一个方法的行为取决于通过接口对象参数传递的代码,即将接口作为方法参数的一部分,接口不同的实现类可一提供不同的方法,这样的接口参数为方法极大的增强了灵活性和扩展性
函数式接口
-
定义:接口中有且只有一个抽象方法(可选的接口注解,@FunctionInterface)
- 即使也定义了其他
default修饰的默认方法,该接口也是函数式接口。
- 即使也定义了其他
-
优点
- 不必显示去声明很多仅需实例化一次的类。Java8以前可以用
匿名类声明实现一个这样的代码
- 不必显示去声明很多仅需实例化一次的类。Java8以前可以用
-
作用
-
函数式接口可以被赋予一个变量。
Runnable r1 = () -> System.out.println("Hello World!"); -
传递给接受一个函数式接口作为参数的方法。
-
Lambda表达式原理
-
Lambda表达式可以为函数式接口生成一个实例(不必像内部类那样写很多模板代码)
-
Lambda表达式本身并不包含它在实现哪个函数式接口,实现的接口类型是从使用Lambda的上下文推断出来的,上下文(比如,接受它传递的方法的参数或接受它的值的局部变量,
即在Lambda表达式用到的参数推断,或表达式结果值的类型推断出接口函数的类型)中Lambda表达式需要的类型(哪个函数式接口)称为目标类型。推断出哪个函数式接口就可以得出该类型的函数描述符(即函数式接口中抽象方法的签名,形如T->boolean或T->R),最终包含Lambda表达式的方法的任何实际参数都必须匹配目标类型及对应的函数描述符
方法引用
流与集合
- 差异
- 集合是一个内存中的数据结构,它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。(你可以往集合里加东西或者删东西,但是不管什么时候,集合中的每个元素都是放在内存里的,元素都得先算出来才能成为集合的一部分。)
- 相比之下,流则是在概念上固定的数据结构(你不能添加或删除元素),其元素则是按需计算的。流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值与此相反,集合则是急切创建的
-
流操作一次后会被自动关闭
- 同一个流只能遍利一次,遍利完就被消费了。想再次遍利需要重新创建流。
- 对集合操作前需要将其全部存放在内存,可以多次遍利。但慢,耗费内存资源。
-
内部迭代(流)外部迭代(集合)
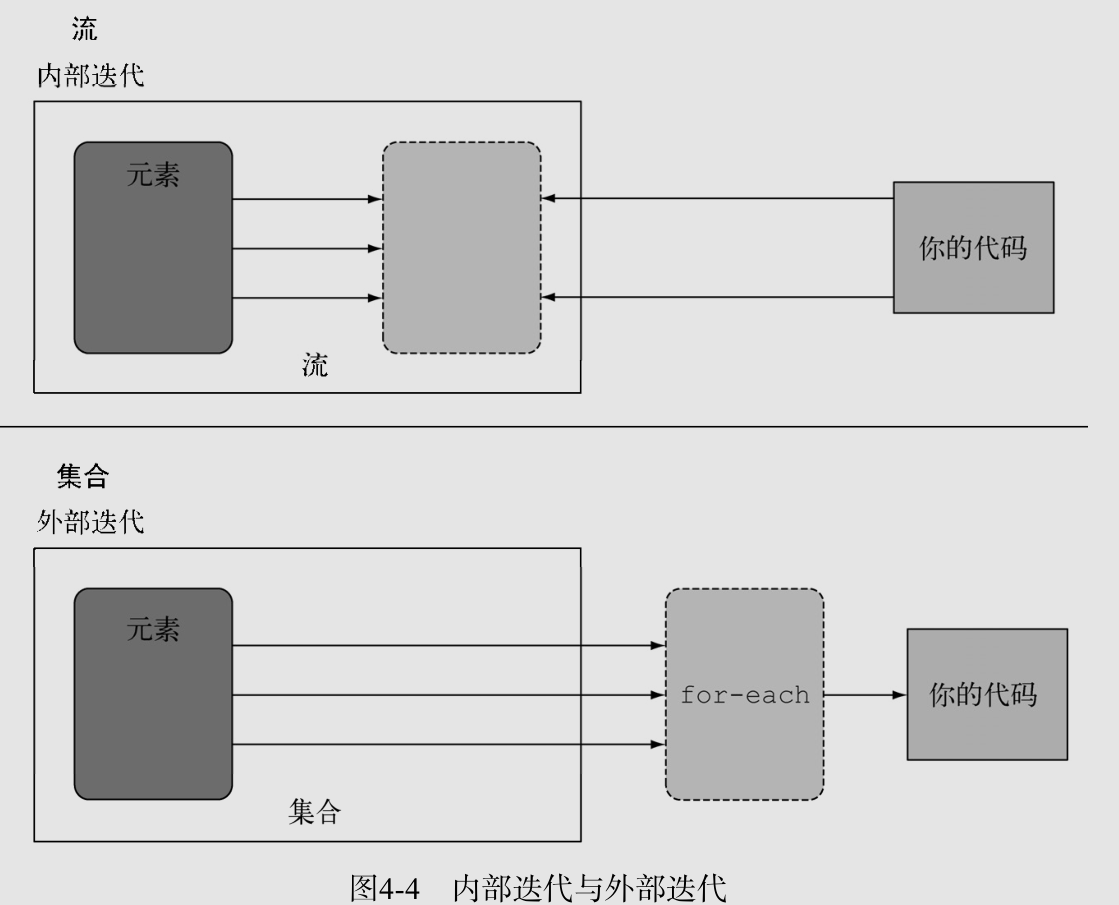
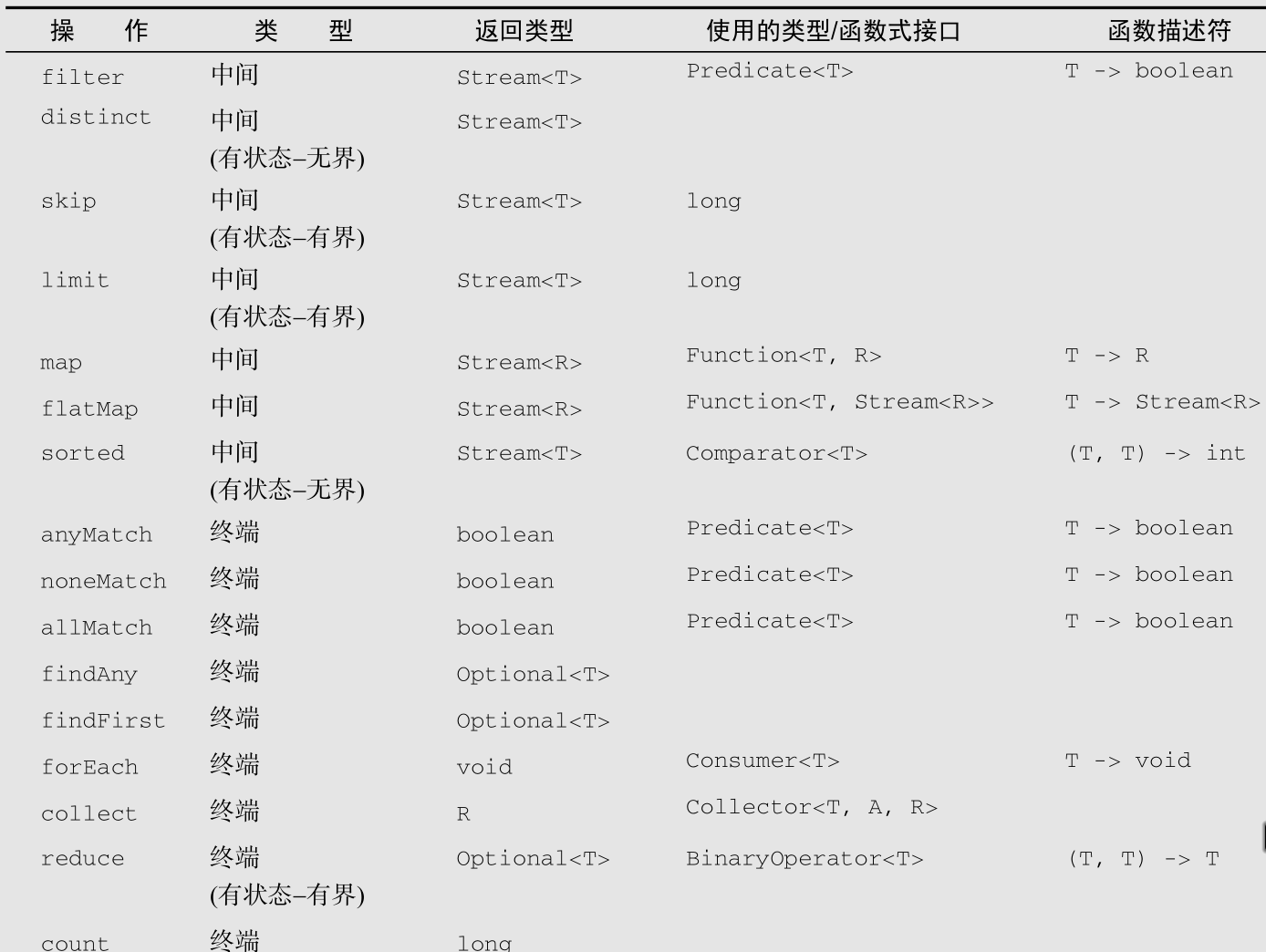
- 中间操作与终端操作
- 中间操作返回一个流
- 终端操作对传来的流进行处理,返回不是流的值
使用流
-
筛选和切片
- 过滤流,filter(Predicate
p) - 去重流,distinct()根据流所生成元素的hashCode和equals方法实现的流。
- 截短流,limit()
- 跳过元素,skip()
- 过滤流,filter(Predicate
-
映射
-
map
-
键提取器
-
flatMap
-
将多维的流扁平化成一维,即多股流化为一股
-
Arrays.stream()将其他流转换为数组流
-
-
Optional
类 - (java.util.Optional)是一个容器类,代表一个值存在或不存在。避免和null检查相关的bug,即允许返回null
-
查找和匹配
- 至少匹配一个,anyMatch(Predicate
p) - 匹配所有,allMatch(Predicate
p) - 包含。findAny(),与Optional
一起使用,若包含一个则立刻返回true - 找到第一个。findFirst()
- 至少匹配一个,anyMatch(Predicate
-
归约:将一个流中的所有元素组合起来得到一个值
- 求和。reduce(初始值,BinaryOperator
),函数接口的描述符 (T,T)->R,Integer中有新静态求和方法sum,reduce(0,Integer::sum) - 重载。reduce的重载变体不接受初始值,返回一个Optional对象。Optional
sum = numbers.stream().reduce((a, b) -> (a + b)); )))) - 求最大/小值。
Optional<Integer> sum = numbers.stream().reduce(Integer::max);Optional<Integer> sum = numbers.stream().reduce(Integer::min)
- 求和。reduce(初始值,BinaryOperator
数值流
-
包装类型流向原始类型转化(映射到数值流)
mapToInt()/mapToDoubld()/mapToLong()这些方法将Stream<T>类型的流转化为对应的int/double/long
-
原始类型流向包装类型转化(转化回对象流)
intStream.boxed()
-
数值范围
- IntStream.rangeClosed(1,100),包含100;IntStream.range(1,100)不包含100
构建流
-
由值创建流
Stream.of()将任意数量的参数转化为一个流Stream.empty()创建一个空流
-
由数组创建
Arrays.stream(T[])传入任意类型的数组,将返回一个流对象
-
由文件生成流
- Files.lines,它会返回一个由指定文件中的各行构成的字符串流。可以使用Files.lines得到一个流,其中的每个元素都是给定文件中的一行。
-
有函数生成流:创建无限流
- 迭代。
Stream.iterate(初始值,UnaryOperator<T>),依次产生的是无限无界的流,需要使用limit()限制。 - 应用:需要依次生成一系列值时使用;生成斐波那契数列
Stream.iterate(new int[]{0,1},t-> new int[]{t[1],t[0]+t[1]}) .limit(20) .map(t->t[0]) .forEach(System.out::println);- 生成。
Stream.generate(Supplier<T>)按需生成一个无限流,有状态,并行避免使用 - 应用。生成随机数。
Stream.generate(Math::random) .limit(5) .forEach(System.out::println); - 迭代。
收集器
-
定义:在需要将流项目重组成集合时,一般会使用收集器(Stream方法collect的参数)。但凡要把流中所有的项目合并成一个结果时就可以用。这个结果可以是任何类型,可以复杂如代表一棵树的多级映射,或是简单如一个整数
-
collect与Collector接口以及Collectors间的关系
-
对流调用
collect方法将对流中的元素触发一个归约操作(由Collector来参数化),一般来说Collector会对元素应用一个转换函数(很多时候是不体现任何转换效果的恒等转化,如toList),Collector接口中的实现决定了如何对流执行归约操作即怎样的收集器实例,而Collectors实用类提供了更多很多静态工厂方法,可以方便的创建常见收集器的实例。
归约和汇总(Collectors中的预定义收集器)
-
查找流中最大值和最小值
Collectors.maxBy(Comparator<T>)和Collectors.minBy(Comparator<T>)返回最值的收集器实例
-
计数(可以省略Collectors,调用的方法全是静态方法返回Collectos实例)
collect(Collectors.counting())collect(Collectors.summinInt(Function<T,R> f)接收一个把对象映射为求和所需int的函数,参数Function是一个转换函数,下同collect(Collectors.averagingInt(Function<T,R> f))求平均数collect(Collectors.summarizingInt())返回转换函数的最大/小值和平均值,总和
-
连接字符串
collect(Collectors.join())joining工厂方法返回的收集器会把对流中每一个对象应用toString方法得到的所有字符串连接成一个字符串,内部使用的是StringBuilder把生成的字符串逐个加起来。collect(Collectors.join(","))joining工厂方法重载版本,每个字符串用指定的delimiter分界符隔开组合成一个字符串collect(Collectors.join(",","(",")"))joining工厂方法重载版本,用,隔开每个字符串然后组合成一个字符串,并且在组合成的一个字符串首部和尾部追加前缀prefix (和后缀suffix )
分组(Java8函数式风格)
-
一级分组
collect(Collector.groupingBy(Function)),给groupingBy方法传递了一个Function(以方法引用的形式),Function叫作分类函数,因为它用来把流中的元素分成不同的组。分组函数返回的值作为映射的键,把流中所有具有这个分类值的项目的列表作为对应的映射值。
-
二级分组(多级分组)
collect(groupingBy(Function),groupingBy(Function))外层Map的键是第一级分类函数生成的值,而这个Map的值又是一个新Map,其中新Map的键是二级分类函数生成的值,第二级map的值是流中元素构成的List,是分别应用第一级和第二级分类函数所得到的对应第一级和第二级键的值
分区(partitioningBy)
- 分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean,于是它最多可以分为两组——true是一组,false是一组。