本篇博客中,我将快速搭建一个小型的网络,并对其进行训练、优化器调参,最后查看模型训练效果。
我将本次搭建网络分为一下几个部分
- 下载、读取数据
- 搭建网络
- 准备日志、损失函数和优化器
- 进行网络的训练与测试,
- 模型文件的保存
- 关闭日志并查看训练效果
下载读取数据
本篇博客所写代码使用 python,并且大量使用了 pytorch 第三方库,其中的 torvision.datasets.CIFAR10() 用于读取数据,torch.utils.data.DataLoader()用于封装遍历数据,倘若对这两种函数不熟悉的同学,可以看我前几篇博客。
# load the data and set the constant values
dataset_path = "../data_cifar10"
dataset_train = torchvision.datasets.CIFAR10(root=dataset_path, train=True, transform=torchvision.transforms.ToTensor(),
download=True)
dataset_test = torchvision.datasets.CIFAR10(root=dataset_path, train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader_train = DataLoader(dataset=dataset_train, batch_size=64)
dataloader_test = DataLoader(dataset=dataset_test, batch_size=64)
dataset_train_len = len(dataset_train)
dataset_test_len = len(dataset_test)
搭建网络
搭建网络的内容在前几篇博客已经写过了,不熟悉的同学请自行查看。
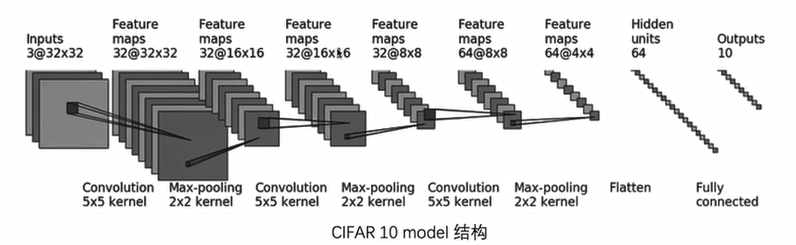
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(start_dim=1, end_dim=-1),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
return self.model(x)
if __name__ == "__main__":
test_data = torch.ones((64, 3, 32, 32))
my_model = MyModel()
data_proceed = my_model(test_data)
print(data_proceed.shape)
准备日志、损失函数和优化器
网络搭建完成之后,我们实例化网络,并打开日志 SummaryWriter,准备好损失函数(交叉熵损失函数)和优化器(SGD),该部分也包括了设置一些常量
# define the net and constant
my_model = MyModel()
learning_rate = 1e-2
my_optimize = torch.optim.SGD(my_model.parameters(), lr=learning_rate)
my_loss_fn = torch.nn.CrossEntropyLoss()
train_step = 0
test_step = 0
max_epoch = 100
writer = SummaryWriter("./logs")
网络的训练和测试
网络的训练过程时,训练前加入 my_model.train(),测试前加入 my_model.test()
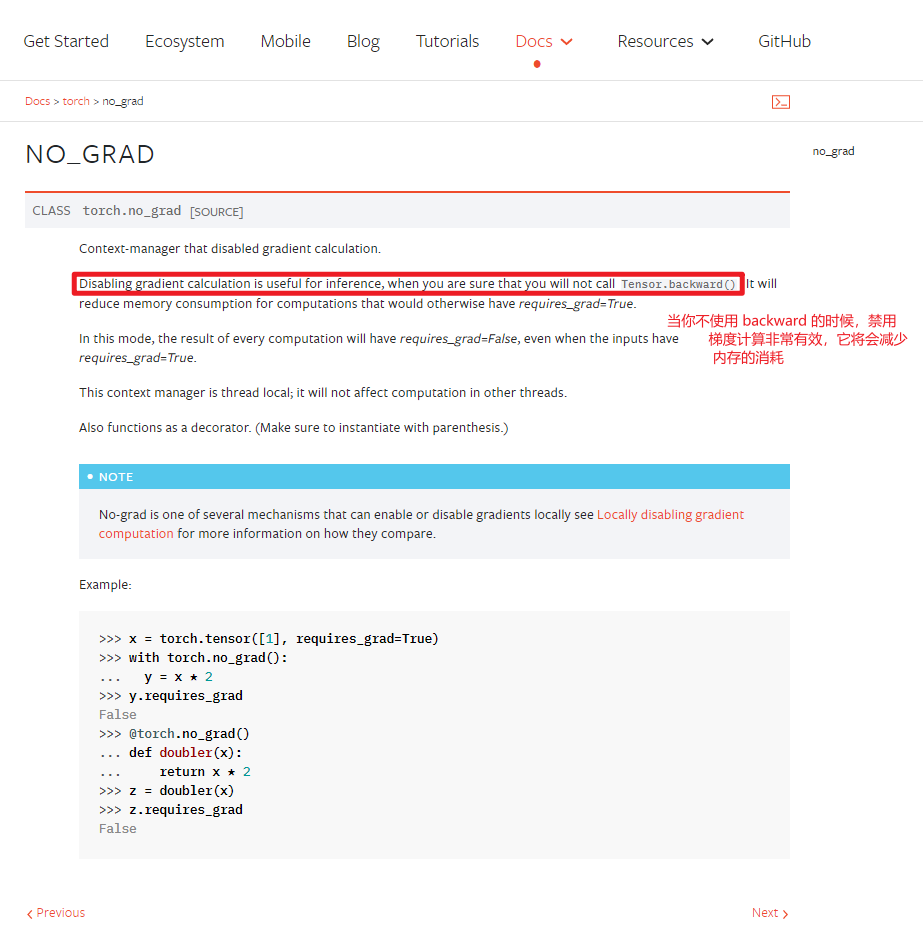
因为前几篇博客并没有讲到 train()和eval()函数,这里我贴一下官方帮助文档的翻译:
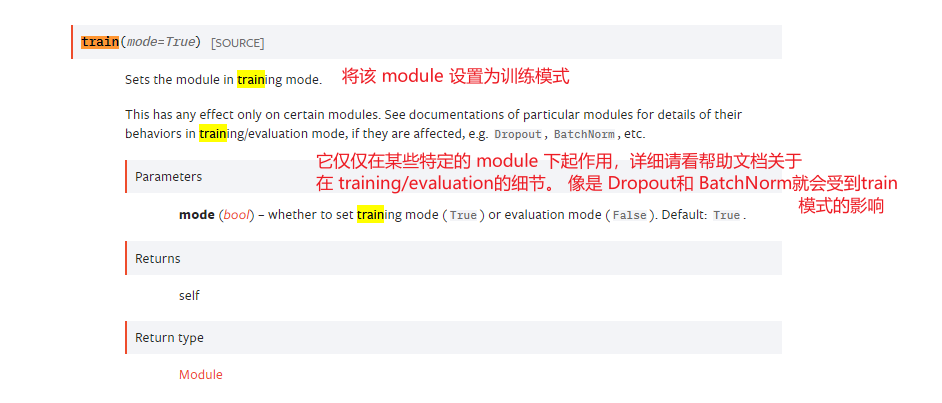

还望注意一下 train 和 test 的区别,是否会 optim.zero_grad(),损失函数数值backward(),和 optim.step()
# begin training and testing
for epoch in range(max_epoch):
print("-------The {} Epoch is Running!-------".format(epoch))
# train the data
my_model.train()
train_sum_loss = 0
for images, targets in dataloader_train:
outputs = my_model(images)
train_loss = my_loss_fn(outputs, targets)
train_sum_loss += train_loss.item()
if train_step % 100 == 0:
print(f"train {epoch}, step:{train_step}, train_loss{train_loss}")
my_optimize.zero_grad()
train_loss.backward()
my_optimize.step()
train_step += 1
print(f"train {epoch}, train_epoch_loss{train_sum_loss}")
writer.add_scalar("train epoch loss", train_sum_loss, epoch)
# test the data
my_model.eval()
with torch.no_grad():
test_sum_loss = 0
predict_right_cnt = 0
for images, targets in dataloader_test:
output = my_model(images)
test_loss = my_loss_fn(output, targets)
test_sum_loss += test_loss.item()
predict_right_cnt += (torch.argmax(output, dim=1) == targets).sum()
writer.add_scalar(f"predict right rate", predict_right_cnt / dataset_test_len, epoch)
print(f"test {epoch}, test_epoch_loss{test_sum_loss}")
writer.add_scalar("test epoch loss", test_sum_loss, epoch)
模型文件的保存
之前的博客讲过模型保存的两种方式,这里采取官方推荐的第二种
# save the model!!!!!!!
torch.save(my_model.state_dict(), f"./project_models/train_model_1_{epoch}.pth")
关闭日志并查看训练效果
writer.close() # 关闭日志
因为 没有进行 dropout,感觉训练的有一点过拟合了我去。。。
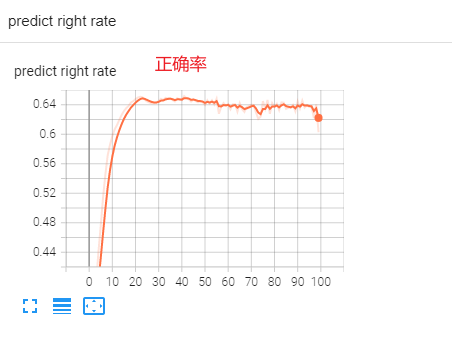


完整的代码
项目结构
main.py,主文件
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# load the data and set the constant values
dataset_path = "../data_cifar10"
dataset_train = torchvision.datasets.CIFAR10(root=dataset_path, train=True, transform=torchvision.transforms.ToTensor(),
download=True)
dataset_test = torchvision.datasets.CIFAR10(root=dataset_path, train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader_train = DataLoader(dataset=dataset_train, batch_size=64)
dataloader_test = DataLoader(dataset=dataset_test, batch_size=64)
dataset_train_len = len(dataset_train)
dataset_test_len = len(dataset_test)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(start_dim=1, end_dim=-1),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
return self.model(x)
# define the net and constant
my_model = MyModel()
learning_rate = 1e-2
my_optimize = torch.optim.SGD(my_model.parameters(), lr=learning_rate)
my_loss_fn = torch.nn.CrossEntropyLoss()
train_step = 0
test_step = 0
max_epoch = 100
writer = SummaryWriter("./logs")
# begin training and testing
for epoch in range(max_epoch):
print("-------The {} Epoch is Running!-------".format(epoch))
# train the data
my_model.train()
train_sum_loss = 0
for images, targets in dataloader_train:
outputs = my_model(images)
train_loss = my_loss_fn(outputs, targets)
train_sum_loss += train_loss.item()
if train_step % 100 == 0:
print(f"train {epoch}, step:{train_step}, train_loss{train_loss}")
my_optimize.zero_grad()
train_loss.backward()
my_optimize.step()
train_step += 1
print(f"train {epoch}, train_epoch_loss{train_sum_loss}")
writer.add_scalar("train epoch loss", train_sum_loss, epoch)
# test the data
my_model.eval()
with torch.no_grad():
test_sum_loss = 0
predict_right_cnt = 0
for images, targets in dataloader_test:
output = my_model(images)
test_loss = my_loss_fn(output, targets)
test_sum_loss += test_loss.item()
predict_right_cnt += (torch.argmax(output, dim=1) == targets).sum()
writer.add_scalar(f"predict right rate", predict_right_cnt / dataset_test_len, epoch)
print(f"test {epoch}, test_epoch_loss{test_sum_loss}")
writer.add_scalar("test epoch loss", test_sum_loss, epoch)
# save the model!!!!!!!
torch.save(my_model.state_dict(), f"./project_models/train_model_2_{epoch}.pth")
writer.close()
注意事项
- train 和 test 过程中,有着较大的区别,首先是 optim 是否 zero_grad(),loss是否进行backward(),optim 是否step()。
- train 和 test 过程中,还应该注意模式的设置, my_model.train() 和 my_model.eval() 是选择不同的模式
- test 过程中,为了减少硬件负担,提高运算速度,我们往往还会 加上
with torch.no_grad(),左右如下所示:

Author:luckylight(xyg)
Date:2021/11/13
Date:2021/11/13