郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

源码分析:rlpyt(Deep Reinforcement Learning in PyTorch) - 穷酸秀才大艹包 - 博客园 (cnblogs.com)
Abstract
自从最近出现用于游戏的深度强化学习[1]和模拟机器人控制(例如[2])以来,大量新算法蓬勃发展。大多数是无模型算法,可分为三类:深度Q学习、策略梯度和Q值策略梯度。这些是沿着不同的研究方向发展的,因此很少有代码库(如果有的话)包含所有这三种类型。然而,这些算法与常见的深度强化学习机制有着共同的深度。我们很高兴分享rlpyt,它在一个共享的、优化的基础设施之上实现了所有三个算法系列,在一个存储库中。它使用Python中的许多常见深度RL算法的模块化实现,使用领先的深度学习库PyTorch [3]。rlpyt被设计为用于深度强化学习的中小型研究的高吞吐量代码库。本白皮书总结了其特性、实现的算法以及与先前工作的关系,并以详细的实现和使用说明作为结尾。rlpyt可在https://github.com/astooke/rlpyt获得。
1 Introduction
自2013年用于游戏的深度强化学习问世[1]和不久之后的模拟机器人控制(例如[2])以来,大量新算法蓬勃发展。大多数是无模型算法,可分为三类:深度Q学习、策略梯度和Q值策略梯度。这些是沿着不同的研究方向发展的,因此很少有代码库(如果有的话)包含所有这三种类型。事实上,许多原始实现仍未发布。因此,从业者通常必须从不同的起点进行开发,并可能为每个感兴趣的算法或基线比较学习新的代码库。RL研究人员经常重新实现算法——也许是一项有价值的个人练习,但会在整个社区中引起多余的努力,或者更糟糕的是,这是一种进入障碍的练习。然而,这些算法与常见的深度强化学习机制有着共同的深度。我们很高兴分享rlpyt,它在单个存储库中实现了所有三个基于共享、优化基础设施的算法系列。rlpyt包含在Python中使用领先的深度学习库PyTorch [3]的许多常见深度RL算法的模块化实现。在众多现有实现中,rlpyt是研究人员更全面的开源资源。rlpyt可在https://github.com/astooke/rlpyt获得。
rlpyt被设计为用于深度RL的中小型研究的高吞吐量代码库(例如,大规模的是DeepMind AlphaStar [4]或OpenAI Five [5])。本白皮书总结了其特性、实现的算法以及与先前工作的关系。提供了一小部分学习曲线来验证一些标准 RL 环境在离散和连续控制中的学习性能。值得注意的是,rlpyt从"分布式强化学习中的循环经验回放"(R2D2)[6]中重现了Atari领域的创纪录结果。该基准测试需要大约300亿帧游戏和100万次网络更新,而rlpyt在合理的时间内实现了这一目标,而无需使用分布式计算基础设施。与OpenAI Gym界面的兼容性提供了对许多现有学习环境的访问,并允许自由定制新的学习环境。本文还介绍了"namedarraytuple",一种用于处理数组集合的新数据结构,这可能是外界感兴趣的。最后,提供了更详细的实现和使用说明。
1.1 Key Features and Algorithms
主要功能和特性包括:
- 以串行模式运行实验(有助于调试,足以进行一些实验)。
- 并行运行实验,可选择并行采样和/或多GPU优化。
- 同步或异步采样和优化(通过回放缓存)。
- 在环境采样期间使用CPU或GPU进行训练和/或批量动作选择。
- 全面支持循环智能体。在训练期间在线或离线评估和记录智能体诊断。
- 包括启动实用程序,用于在本地计算机上堆叠/排队实验集。
- 易于修改和重复使用现有组件的模块化。兼容OpenAI Gym [7]环境接口。1
实现的算法包括以下内容(检查存储库以获取可能的添加):
- Policy Gradient: A2C [8], PPO [9].
- Deep Q-Learning: DQN [1] + variants: Double [10], Dueling [11], Categorical [12], Rainbow [13] (minus Noisy Nets), Recurrent (R2D2-like) [6], including vector-valued epsilon-greedy (Ape-X-like) [14] (coming soon: Implicit Quantile DQN [15]).
- Q-Function Policy Gradient: DDPG [16], TD3 [17], SAC [18, 19], (coming soon: Distributional DDPG [20]).
回放缓存支持DQN和Q函数策略梯度算法,并包括以下选项:n步回放;序列回放(用于循环);周期性存储循环状态(以节省内存);优先回放(和树)[21];基于帧的缓存,以节省内存,例如通过仅存储唯一的Atari帧。
2 Parallel Computing Infrastructure for Faster Experimentation
无模型强化学习的两个阶段——采样环境交互和训练智能体——可以不同地并行化。rlpyt解决了这两个问题,如此处所述。在所有安排中,系统共享内存是训练数据和模型参数的进程间通信的基础,从而最大限度地减少数据传输时间和内存占用。
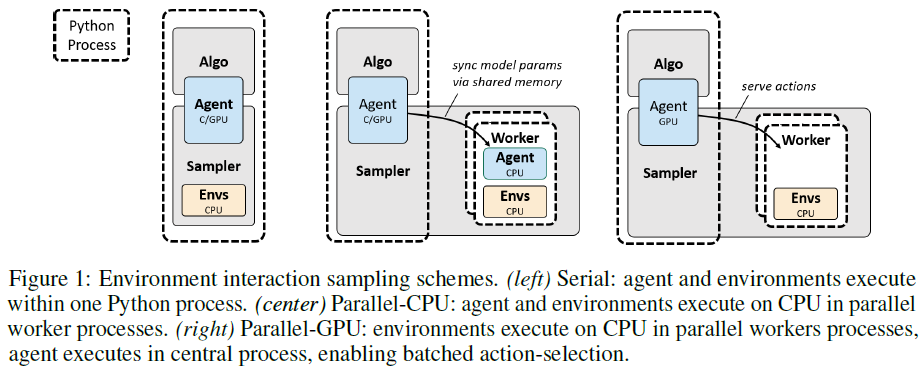
2.1 Sampling
对于采样,rlpyt提供以下配置,如图1所示。
Serial. 采样发生在主进程中,可以运行一个或多个环境实例。内置智能体使用相同的模型进行采样和优化,因此如果在GPU上进行优化,采样期间的动作选择也使用GPU,在所有环境中进行批处理。(如果使用GPU优化每批次运行多个时间步骤,则使用单独的CPU模型进行动作选择可能会更快。)
Parallel-CPU. 采样器启动工作进程以运行环境并执行操作选择。如果在GPU上进行优化,模型参数将被复制到共享内存中,用于工作者中的CPU动作选择。工作者之间的同步仅在每个采样批次中发生。
Parallel-GPU. 采样器启动工作进程以运行环境,并将观察结果传回主进程以进行动作选择,如果在GPU上进行优化,它将使用GPU。所有环境的观察结果都被批处理在一起,以便对智能体进行一次调用。逐步通信通过另一个共享内存缓存发生,轻量级信号量在每个模拟批处理步骤中强制跨工作者同步。
Alternating-GPU. 类似于并行GPU采样,但有两组工作者;一组逐步运行环境,而另一组等待动作选择。当动作选择时间略短于批处理环境模拟时间时,可以提供加速。
1 有关所需修改,请参阅实施细节。
2.2 Optimization
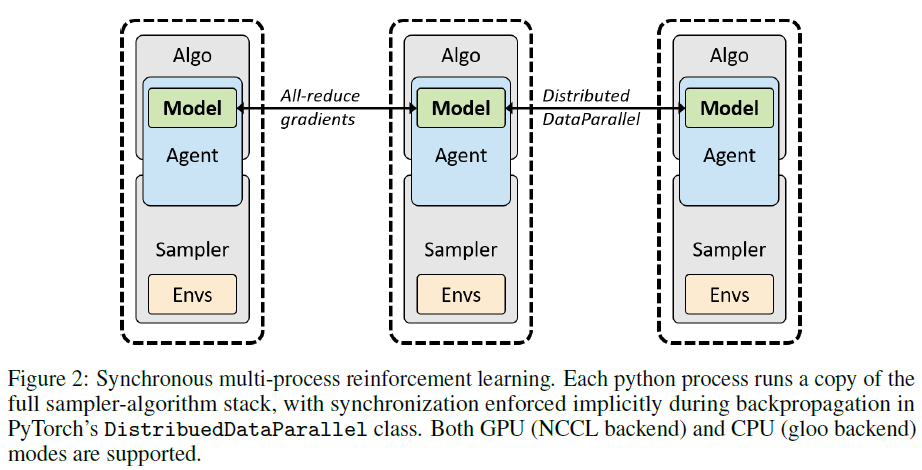
同步多GPU优化使用PyTorch的DistributedDataParallel来包装模型。一个单独的python进程驱动每个GPU。正如PyTorch所提供的那样,NCCL用于全部减少每个梯度,这可以与反向传播同时发生在块中,以便在大型模型上更好地扩展。这同样适用于多CPU优化,使用DistributedDataParallelCPU和"gloo"后端(可能比多CPU核的MKL线程更快)。安排如图2所示。整个采样训练堆栈在每个过程中被复制,并且它们之间不共享训练数据。可以使用任何串行或并行采样器。
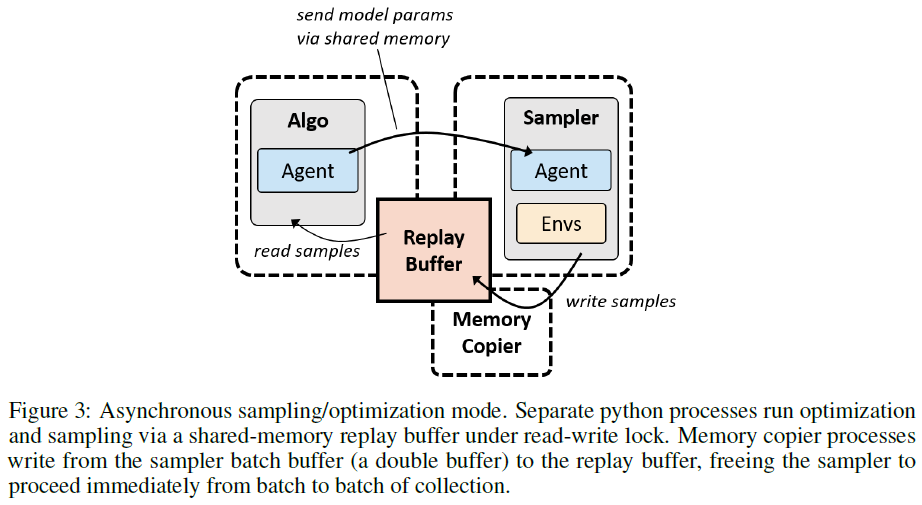
2.3 Asynchronous Sampling-Optimization
在到目前为止描述的配置中,采样器和优化器在同一个Python进程中按顺序运行。然而,在某些情况下,异步运行优化和采样通过允许两者连续运行来实现更好的硬件利用率。在异步模式下,单独的Python进程运行训练和采样,并由构建在共享内存上的回放缓存捆绑在一起。采样通过对数据批次使用双缓存不间断地运行,另一个Python进程在读写锁下将其复制到主缓存中。如图3所示。优化器和采样器可以独立并行化,可能每个都使用不同数量的GPU,以实现最佳的整体利用率和速度。
过程之间保持一定程度的控制。可以指定所需的最大回放率(消耗率除以训练数据的生成率),优化器将被限制为不超过该值。如果优化器提供了新参数,则采样器批量大小(时间步骤)决定了actor模型更新的速率。所有actor都使用相同的参数。
2.4 Which Configuration is Best?
在创建或修改智能体、模型、算法和环境时,串行模式将是最容易调试的。一旦顺利运行,就可以直接探索用于并行采样、多GPU优化和异步采样的更复杂的基础架构,因为它们构建在基本相同的接口上。当然,与标准RL工作流程的偏差(即runner)可能需要更加小心地进行并行化——再次建议从串行情况开始。最佳配置可能取决于问题、可用的计算硬件和要运行的实验数量。目前,rlpyt仅实现单节点并行,但它的组件可以构成分布式框架的构建块。
3 Learning Performance
本节介绍了根据已发布值验证实现性能的学习曲线。显示了标准Atari游戏[22]和Mujoco [23]连续控制环境的子集。这既不是全面的基准测试,也不是扩展指南,而仅仅是对每个算法和基础设施组件的练习。有关Atari缩放指南,请参阅例如[24],对于Mujoco,[20]是一个可能的起点。
3.1 Mujoco: Continuous Control from State
在此,我们展示了应用于OpenAI Gym中选择的Mujoco2任务的状态持续控制的强化学习算法。对于每种算法,我们在所有环境中使用相同的已发布超参数并运行串行实现。3
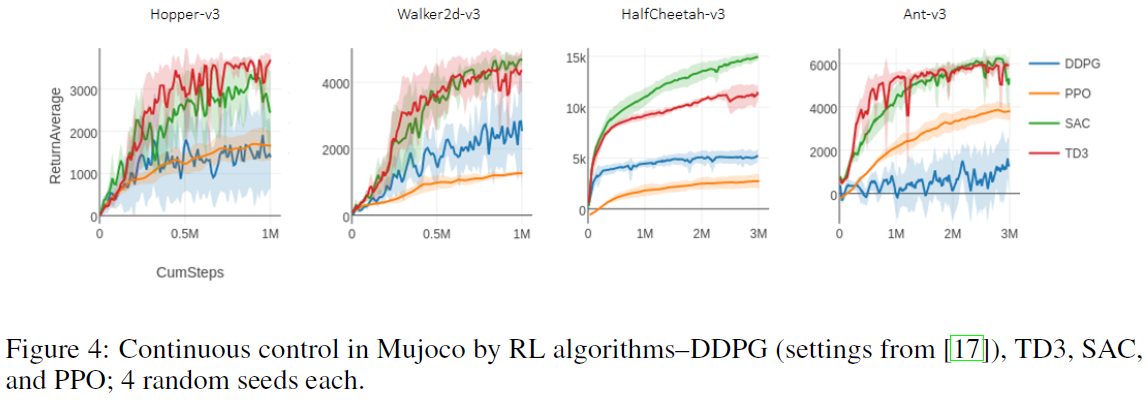
2 mujoco200.
3 本文的前一版本显示SAC和TD3的得分较低,通过在轨迹由于时间限制而结束时引导(bootstrapping)价值函数,与原始SAC实现一样,此处的得分有所提高。通过切换到具有熵调整和无状态值函数的更新版本,SAC的分数进一步提高。
3.2 Atari: Discrete Control from Vision
在此,我们包括使用策略梯度(图5)和DQN算法(图6)通过视觉学习的一小部分Atari游戏的学习曲线。
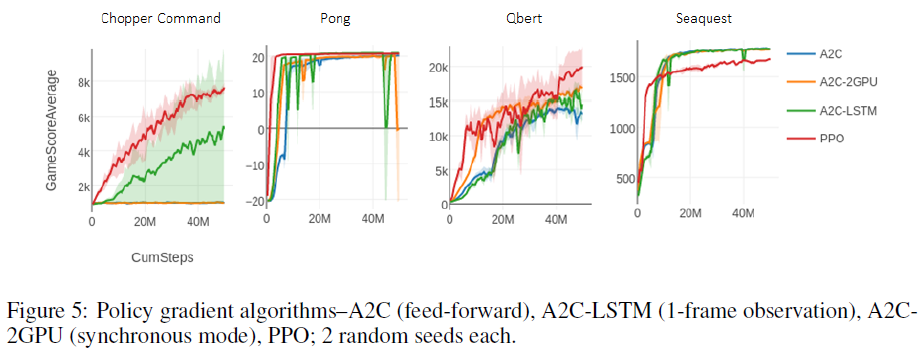
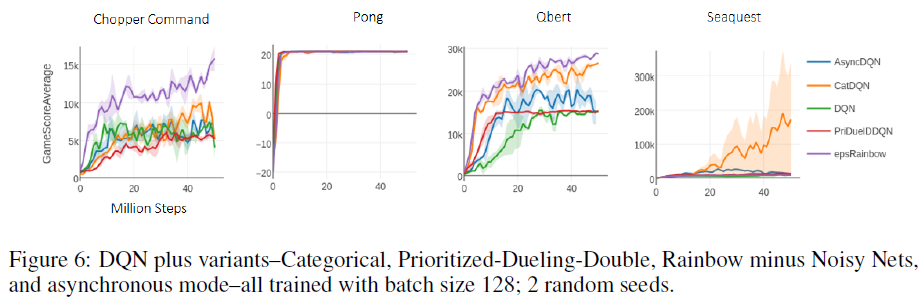
R2D1 我们强调rlpyt复现了R2D2 [6]的最先进性能,这在以前只能使用分布式计算才能实现。该基准包括从回放缓存训练的循环智能体,用于大约100亿个样本(400亿帧)。R2D1 (非分布式R2D2)使用rlpyt的几个更高级的基础架构组件来实现这一点,即带有交替采样器的多GPU异步采样模式。在图7中,我们复现了几条超越任何先前算法的学习曲线。性能与公布值的一些细微差异很可能是由于新样本的优先级不同,这对某些游戏的影响比其他游戏更大4,以及回放率略低。5 鉴于低回放率,初始优先级在一些游戏中非常重要。
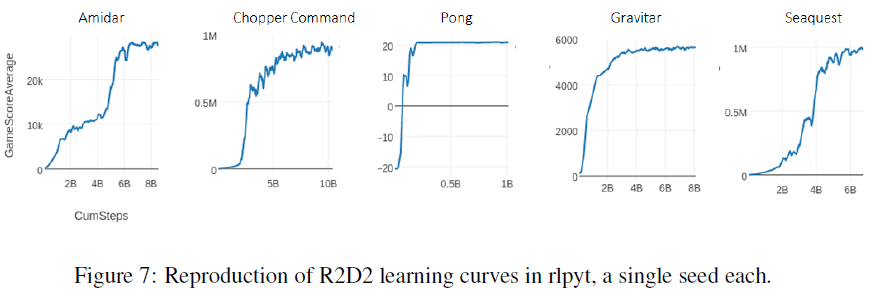
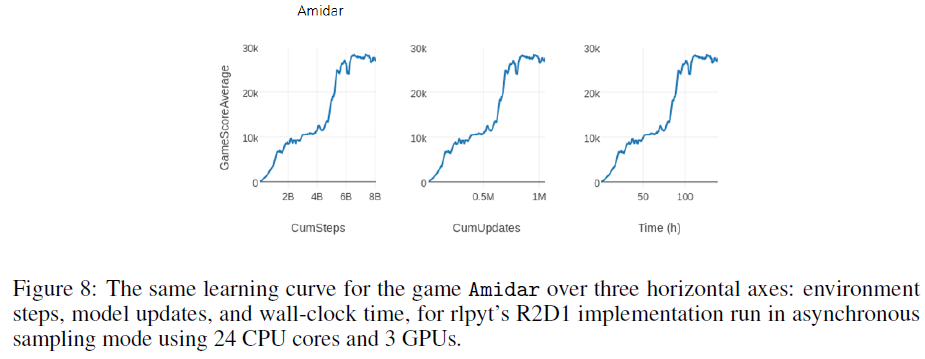
R2D2的原始分布式实现引用了大约每秒66000步(SPS),使用256个CPU进行采样和1个GPU进行训练。在单个工作站中仅使用24个CPU6和3个Titan-Xp GPU(一个GPU用于训练,两个用于交替采样器中的动作服务)时,rlpyt实现了超过16000 SPS。这可能足以在不访问分布式基础架构的情况下进行实验。未来研究的一种可能性是使用多GPU优化来提高回放率(此处设置为1)以加快学习速度。图8显示了三种不同度量的相同学习曲线:环境步骤(即1步 = 4帧)、模型更新和时间。此次运行在不到138小时内达到了80亿步和100万次更新。
4 大多数曲线使用1步TD误差来对新样本进行优先级排序,并且无意中交换了两个回放优先级系数。此外,由于收集以40个时间步骤批次运行,但训练使用80步序列,因此我们仅使用一半的训练段来计算新的优先级。当我们更正使用5步TD初始优先级和使用第二个半批次时,Gravitar尤其敏感并得到了改进,但这次运行仍然稳定在低于6000的低分。解决此问题的工作仍在继续。
5 我们使用1的回放率,包括热身样本,而原始作者的回放率接近0.8,仅计算训练样本;根据他们的计算,我们运行在0.67。
6 2x Intel Xeon Gold 6126, circa 2017.
4 New Data Structure: namedarraytuple
rlpyt引入了新的对象类"namedarraytuples",以便更轻松地组织numpy数组或torch张量的集合。namedarraytuples本质上是一个命名元组,它将索引或切片读/写暴露到结构中。考虑写入一个(可能是嵌套的)数组字典,这些字典共享一些用于寻址的公共维度:

此代码替换为以下代码:
![]()
重要的是,无论dest和src是单独的numpy数组还是任意结构的数组集合,语法都是相同的。dest和src的结构必须匹配,或者src可以是单个值以应用于所有字段,并且None是要忽略的字段的特殊占位符值。rlpyt广泛使用这种数据结构——训练数据的不同元素以相同的前导维度组织,使其易于与所需的时间或批处理维度进行交互。
这也旨在支持具有多模式观察或行动的环境。环境可以将它们按原样存储到用于观察的命名数组元组中,而不是将相机图像和关节角度扁平化和合并到一个观察向量中。在模型的前向方法中,observation.joint和observation.image可以被馈送到所需的层,而无需更改中间基础设施代码。有关更多详细信息,请参阅rlpyt/utils/collections.py中namedarraytuples的代码和文档。
在设置或修改智能体、算法和环境期间,使用namedtuples和namedarraytuples可能会产生一些编程开销。例如,对于序列化7,它们必须在模块级别定义,这可以通过使用全局变量动态完成(请参阅Gym包装器)。这些显式定义的接口的一个好处是它们减少了由于本地内存遗漏或替换共享内存缓存元素而出错的机会。
7 样本数据序列化的唯一内置使用是在生成缓存分配的初始示例时选择放入子进程。模型前向执行会触发MKL OpenMP线程初始化,这可能会影响之后的子进程。例如,如果在1个CPU核上,并行CPU采样器智能体应该使用1个MKL线程进行初始化,而优化器可能使用多个核和线程。顺便说一句,大多数rlpyt子进程设置了torch.num_threads(1)以避免挂在MKL上,这可能不是fork-safe的。
8 https://spinningup.openai.com/en/latest/index.html
9 https://github.com/openai/spinningup
10 https://github.com/astooke/accel_rl
11 https://github.com/rll/rllab
5 Related Work
对于深度RL的新手来说,其他资源可能更适合熟悉算法,例如OpenAI Spinning Up [25]。8,9 rlpyt是accel_rl代码库的修订和扩展,10 它探索了使用Theano在Atari域中扩展RL [26],结果见[24]。有关包括RL在内的深度学习扩展的进一步研究,请参阅[27]。rlpyt和accel_rl最初受到rllab [28]的启发(例如,记录器几乎是直接副本)11。
其他已发表的研究代码库包括OpenAI Baselines [29]和Dopamine [30],它们都在Tensorflow [31]中实现,并且都没有优化到rlpyt的程度,也不包含所有三个算法系列。Rllib [32]建立在Ray [33]之上,专注于分布式计算,可能会使小型实验复杂化。Facebook Horizon [34]提供了算法的一个子集,并专注于大规模生产的应用程序。总之,rlpyt为并行性提供了更多算法的模块化实现和模块化基础架构,使其成为支持广泛研究用途的独特工具集。
6 Implementation and Usage Details
要开始使用,建议按照存储库中提供的示例脚本并阅读其中的说明。以下是没有代码的概念概述。
6.1 Code Structure.
下面的树和描述总结了类和接口的结构。

Runner - 连接采样器、智能体和算法;管理训练循环和诊断记录。
Sampler - 管理智能体与环境的交互以收集训练数据;可以初始化并行工作者。
Collector - 逐步运行环境(并且可能操作智能体)并记录样本。
Environment - 要学习的任务。与之前的实现一样,在每一步输出:(observation, reward, done, env_info)。
Observation/Action Space - 从环境到智能体的接口规范。
TrajectoryInfo - 基于每个轨迹记录的诊断。
Agent - 在采样器中选择对环境的控制动作;由算法训练;模型接口;在采样期间保持模型循环状态。与之前的实现一样,在每个步骤中都会输出(action, agent_info)。
Model - PyTorch神经网络模块接受(observation, prev_action, prev_reward)和可能的initial_rnn_state参数。
Distribution - 随机智能体的样本操作;定义了损失函数的相关公式。
Algorithm - 使用收集的样本来训练智能体,例如定义损失函数并执行梯度下降。
Optimizer - 模型参数的训练更新规则(例如Adam)。
OptimizationInfo - 基于每个训练批次记录的诊断。
Logger - 在所有流程和类别中都可用,用于记录打印的报表和/或表格值。
6.2 No Asynchronous Optimization
最近的大规模RL项目,例如OpenAI Five [5]和DeepMind AlphaStar [4],已经成功地使用了同步多设备优化(这意味着每个梯度都在具有相同参数值的设备之间全部减少)。[24]中的先前经验发现,使用CPU参数存储在Atari上可以很好地扩展异步多GPU A3C和PPO,但这种技术不能很好地扩展到具有更多训练更新的大型网络,例如在DQN中。因此,rlpyt目前不包括[8, 35]中的异步优化方案。
6.3 Recurrent Agents
所有智能体都会收到(observation, previous_action, previous_reward)输入(参见例如[8]),尽管标准前馈智能体可能只使用观察。循环状态被组织成它自己的命名数组元组,并且可以自定义。
Sampling. 智能体在环境采样期间处理循环状态。此功能根据CuDNN [36]接口以优化的方式提供,与该状态的结构无关。自定义智能体的单独mixin类包含在常规采样和交替采样中。循环状态记录在agent_info下。
Training. 训练数据按照[Time, Batch]的主要维度进行组织,与PyTorch/CuDNN的递归实现相匹配。对于CuDNN,初始循环状态必须重新组织为[Num_Layers, Batch, Hidden_Size]维度并使其连续,如包含的循环智能体类所示。
6.4 Data Organization Inferred in Model Forward Method
相同的模型可用于不同的前导维度:单个输入(无前导维度)、批次[Batch, ..]或时间批次[Time, Batch, ..]。例如,在模型的正向方法中,前导维度是根据观察的已知维度推断的。输入相应地为前馈或循环层重新塑形,最后输出根据输入恢复其前导维度。这样,相同的模型可用于采样期间的动作选择、训练以及提取单个示例以构建缓存。请参阅任何包含的模型以获取此模式的模板,任何自定义模型都应遵循该模板。
6.5 OpenAI Gym Interface
使用预分配缓存需要对Gym环境接口进行一次修改:env_info字典必须在每一步提供相同的键/字段。包含一个Gym风格的包装器,它将env_info转换为一个命名元组,以便于写入样本缓存。提供了一个额外的包装器组件,作为确保所有密钥出现在每一步的一种方式。还为Gym空间提供了一个包装器,以将它们转换为相应的rlpyt空间(特别是多模态Gym Dictionary空间成为rlpyt Composite空间。)
6.6 Launching Utilities
包括启动实用程序,用于在给定的本地硬件资源上构建变体和堆叠/排队实验。例如,在一台8个GPU、40个CPU的机器上,可能需要运行一些变体(例如,30个不同的设置/种子),每个变体使用2个GPU;启动器将在非重叠资源上启动4个实验(每个实验有2个GPU和10个CPU),当这些实验完成后,它将在它们的位置启动下一个实验,直到全部完成。结果被记录到与生成的变体匹配的文件结构中(参见示例脚本)。其他脚本模式可能更适合广泛并行启动到云中。
7 Conclusion
我们希望rlpyt可以促进现有深度RL技术的采用,并作为研究新技术的起点。例如,元学习、基于模型和多智能体RL等更高级的主题并没有在rlpyt中明确解决,但适用的代码组件可能仍然有助于加速它们的开发。随着该领域的成熟,我们预计算法的提供会随着时间的推移而增长。