郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

1st Conference on Robot Learning (CoRL 2017), Mountain View, United States.
Abstract
我们介绍了用于自动驾驶研究的开源模拟器CARLA。CARLA是从头开始开发的,用于支持城市自动驾驶系统的开发、训练和验证。除了开源代码和协议之外,CARLA还提供了为此目的而创建并可以自由使用的开放数字资产(城市布局、建筑物、车辆)。仿真平台支持传感器套件和环境条件的灵活规范。我们使用CARLA研究了三种自动驾驶方法的性能:经典的模块化流水线、通过模仿学习训练的端到端模型和通过强化学习训练的端到端模型。这些方法在难度增加的受控场景中进行评估,并通过CARLA提供的指标检查其性能,说明该平台在自动驾驶研究中的实用性。
Keywords: Autonomous driving, sensorimotor control, simulation
1 Introduction
三维环境中的感觉运动控制仍然是机器学习和机器人技术的主要挑战。自主地面车辆的开发是这个问题的长期研究实例[22, 26]。它最困难的形式是在人口稠密的城市环境中导航[21]。由于交通路口复杂的多智能体动态,这种设置特别具有挑战性;跟踪和响应可能在任何给定时间出现的数十或数百个其他参与者的动作的必要性;规定的交通规则,需要识别路标、路灯和道路标记,并区分多种其他车辆;罕见事件的长尾——道路建设、孩子跑到路上、前方发生事故、流氓司机逆行;以及迅速协调相互冲突的目标的必要性,例如当心不在焉的行人偏离前方道路但另一辆车从后面快速接近并且如果刹车过猛可能会追尾时应用适当的减速。
基础设施成本以及物理世界中训练和测试系统的后勤困难阻碍了城市自动驾驶的研究。即使是一辆机器人汽车的检测和操作也需要大量的资金和人力。单一车辆远远不足以收集必要的数据,这些数据涵盖了训练和验证都必须处理的大量极端情况。这对于经典的模块化流水线[21, 8]来说是正确的,对于数据饥渴的深度学习技术更是如此。大多数研究小组都无法在现实世界中对用于城市驾驶的感觉运动控制模型进行训练和验证。
另一种方法是在模拟中训练和验证驾驶策略。模拟可以使自动城市驾驶的研究民主化。系统验证也是必要的,因为有些场景太危险而无法在现实世界中上演(例如,一个孩子跑到汽车前面的路上)。自早期自动驾驶研究[22]以来,仿真一直用于训练驾驶模型。最近,赛车模拟器已被用于评估自动驾驶的新方法[28, 3]。自定义模拟设置通常用于训练和基准测试机器人视觉系统 [2, 9, 10, 11, 20, 25, 27, 29]。商业游戏已被用于获取高保真数据,用于训练和基准测试视觉感知系统[23, 24]。
虽然在自动驾驶研究中临时使用仿真很普遍,但现有的仿真平台是有限的。TORCS [28]等开源赛车模拟器没有呈现城市驾驶的复杂性:它们缺乏行人、十字路口、交叉路口、交通规则和其他区分城市驾驶与赛道赛车的复杂性。而高保真模拟城市环境的商业游戏,例如Grand Theft Auto V [23, 24],不支持详细的驾驶策略基准测试:它们对环境的定制和控制很少,脚本和场景规范有限,严重受限的传感器套件规范,对违反交通规则没有详细的反馈,以及由于其闭源商业性质和开发过程中根本不同的目标而导致的其他限制。
在本文中,我们介绍了CARLA(汽车学习行动)——一种用于城市驾驶的开放式模拟器。CARLA是从头开始开发的,用于支持自动驾驶模型的训练、原型设计和验证,包括感知和控制。CARLA是一个开放平台。独一无二的是,CARLA提供的城市环境内容也是免费的。内容是由专门为此目的聘请的数字艺术家团队从头开始创建的。包括城市布局、大量车型、建筑、行人、路牌等。该仿真平台支持传感器套件的灵活设置,并提供可用于训练驾驶策略的信号,例如GPS坐标、速度、加速度以及有关碰撞和其他违规行为的详细数据。可以指定广泛的环境条件,包括天气和一天中的时间。图1说明了许多此类环境条件。
我们使用CARLA来研究三种自动驾驶方法的性能。第一个是经典的模块化流水线,包括基于视觉的感知模块、基于规则的规划器和机动控制器。第二个是深度网络,将感官输入映射到驾驶命令,通过模仿学习进行端到端训练。第三个也是深度网络,通过强化学习进行端到端训练。我们使用CARLA来展示难度越来越大的受控目标导向导航场景。我们操纵必须穿越的路线的复杂性、交通的存在和环境条件。实验结果阐明了三种方法的性能特征。

2 Simulation Engine
CARLA专为渲染和物理模拟的灵活性和真实性而构建。它被实现为Unreal Engine 4 (UE4)[7]上的一个开源层,支持社区未来的扩展。该引擎提供最先进的渲染质量、逼真的物理、基本的NPC逻辑和可互操作插件的生态系统。引擎本身可免费用于非商业用途。
CARLA模拟了一个动态世界,并在世界和与世界交互的智能体之间提供了一个简单的接口。为支持此功能,CARLA被设计为服务器-客户端系统,其中服务器运行模拟并渲染场景。客户端API是用Python实现的,负责通过套接字在自治智能体和服务器之间进行交互。客户端向服务器发送命令和元命令,并接收传感器读数作为回报。命令控制车辆,包括转向、加速和制动。元命令控制服务器的行为,用于重置模拟、更改环境属性和修改传感器套件。环境属性包括天气条件、照明以及汽车和行人的密度。当服务器重置时,智能体会在客户端指定的新位置重新初始化。
Environment. 环境由建筑物、植被、交通标志和基础设施等静态对象以及车辆和行人等动态对象的3D模型组成。所有模型都经过精心设计,以协调视觉质量和渲染速度:我们使用低权重的几何模型和纹理,但通过精心制作材料和利用可变细节级别来保持视觉真实感。所有3D模型都有一个共同的比例,它们的大小反映了真实对象的大小。在撰写本文时,我们的资产库包括40个不同的建筑物、16个动画车辆模型和50个动画行人模型。
我们通过以下步骤使用这些资产来构建城市环境:(a) 铺设道路和人行道;(b) 手动放置房屋、植被、地形和交通基础设施;(c) 指定动态对象可以出现(生成)的位置。这样我们设计了两个城镇:城镇1的可行驶道路总长为2.9公里,用于训练,城镇2的可行驶道路总长度为1.4公里,用于测试。这两个城镇显示在补编中。
CARLA开发中的挑战之一是非玩家角色的行为配置,这对于现实主义很重要。我们将非玩家车辆基于标准UE4车辆模型(PhysXVehicles)。运动学参数针对真实性进行了调整。我们还实施了一个管理非玩家车辆行为的基本控制器:保持车道、遵守交通信号灯、限速和交叉路口的决策。车辆和行人可以相互检测和避开。未来可以集成更先进的非玩家车辆控制器[1]。
行人根据特定城镇的导航地图在街道上导航,该地图传达了基于位置的成本。该费用旨在鼓励行人沿着人行道和标记的马路交叉口行走,但允许他们在任何时候过马路。行人按照这张地图在城里走来走去,互相避开,尽量避开车辆。如果汽车与行人发生碰撞,则从模拟中删除行人,并在短暂的时间间隔后在不同的位置生成新的行人。
为了增加视觉多样性,当非玩家角色被添加到模拟中时,我们随机化了它们的外观。每个行人都穿着从预先指定的衣柜中抽取的随机服装,并且可以选择配备以下一种或多种物品:智能手机、购物袋、吉他盒、手提箱、滚动袋或雨伞。每辆车都根据特定模型的一组材料随机涂漆。
我们还实现了各种大气条件和照明制度。它们在太阳的位置和颜色、天空漫射的强度和颜色以及环境遮挡、大气雾、多云和降水方面有所不同。目前,模拟器支持两种光照条件——中午和日落——以及九种天气条件,不同的云量、降水量和街道上的水坑。这导致总共18种光照-天气组合。(在下文中,为了简洁起见,我们将这些称为天气。) 其中四个如图1所示。
Sensors. CARLA允许灵活配置智能体的传感器套件。在撰写本文时,传感器仅限于RGB相机和提供真实深度和语义分割的伪传感器。这些如图2所示。摄像机的数量及其类型和位置可以由客户指定。相机参数包括3D位置、相对于汽车坐标系的3D方向、视野和景深。我们的语义分割伪传感器提供12个语义类:道路、车道标记、交通标志、人行道、栅栏、杆、墙、建筑物、植被、车辆、行人等。
除了传感器和伪传感器读数外,CARLA还提供一系列与智能体状态和交通规则遵守情况相关的测量值。智能体状态的测量包括车辆相对于世界坐标系(类似于GPS和指南针)的位置和方向、速度、加速度矢量和碰撞累积影响。有关交通规则的测量包括车辆撞击错误车道或人行道的足迹百分比,以及交通灯的状态和车辆当前位置的速度限制。最后,CARLA提供对环境中所有动态对象的精确位置和边界框的访问。这些信号在训练和评估驾驶策略方面发挥着重要作用。

3 Autonomous Driving
CARLA支持自动驾驶系统的开发、训练和详细性能分析。我们使用CARLA评估了三种自动驾驶方法。 第一个是模块化流水线,它依赖于视觉感知、规划和控制的专用子系统。这种架构符合大多数现有的自动驾驶系统[21, 8]。第二种方法基于通过模仿学习进行端到端训练的深度网络[4]。这种方法代表了一项长期的调查,最近引起了新的兴趣[22, 16, 4]。第三种方法基于通过强化学习进行端到端训练的深度网络[19]。
我们首先介绍所有方法通用的符号,然后依次描述每个方法。考虑一个在离散时间步骤上与环境交互的智能体。在每个时间步骤,智能体得到一个观察ot并且必须产生一个动作at。动作是一个三维向量,表示转向、油门和刹车。观察ot是一组感官输入。这可以包括高维感官观察,例如彩色图像和深度图,以及低维测量,例如速度和GPS读数。
除了瞬时观察之外,所有方法还利用高级拓扑规划器提供的计划。该计划器将智能体的当前位置和目标的位置作为输入,并使用A*算法提供智能体需要遵循以达到目标的高级计划。该计划建议智能体在十字路口左转、右转或保持直行。该计划不提供轨迹,也不包含几何信息。因此,在现实世界中引导人类驾驶员和自动驾驶车辆的普通GPS导航应用程序给出了一种较弱的计划形式。我们不使用度量地图。
3.1 Modular pipeline
我们的第一种方法是模块化流水线,它将驱动任务分解为以下子系统:(i) 感知,(ii) 规划和 (iii) 连续控制。由于没有提供度量图作为输入,因此视觉感知成为一项关键任务。局部规划完全依赖于感知模块估计的场景布局。
感知堆栈使用语义分割来估计车道、道路限制、动态物体和其他危险。此外,分类模型用于确定与交叉口的接近程度。本地规划器使用基于规则的状态机来实现针对城市环境调整的简单预定义策略。持续控制由PID控制器执行,该控制器驱动转向、油门和制动器。我们现在更详细地描述这些模块。
Perception. 我们在这里描述的感知堆栈是建立在基于RefineNet [17]的语义分割网络之上的。该网络经过训练,可将图像中的每个像素分类为以下语义类别之一:C = {道路,人行道,车道标记,动态对象,杂项静态}。该网络使用CARLA在训练环境中生成的2500个标记图像进行训练。网络提供的概率分布用于根据道路面积和车道标记估计自我车道。网络输出还用于计算旨在包含行人、车辆和其他危险的障碍物掩膜。
此外,我们使用基于AlexNet [15]的二元场景分类器(交叉口/无交叉口)来估计处于交叉口的可能性。该网络在两个类别之间平衡的500张图像上进行训练。
Local planner. 本地规划器通过生成一组航路点来协调低级导航:近期目标状态,代表汽车在不久的将来所需的位置和方向。规划器的目标是合成使汽车保持在道路上并防止碰撞的航路点。本地规划器基于具有以下状态的状态机:(i) 保持道路,(ii) 左转,(iii) 右转,(iv) 交叉路口前进,和 (v) 危险停车。基于感知模块提供的估计和全局规划器提供的拓扑信息执行状态之间的转换。更多细节可以在补充中找到。以航路点形式的本地计划连同车辆的当前姿态和速度一起传送给控制器。
Continuous controller. 我们使用比例积分微分(PID)控制器[6],因为它的简单性、灵活性和对慢响应时间的相对鲁棒性。每个控制器接收当前姿势、速度和航点列表,并分别启动转向、油门和刹车。我们的目标巡航速度为20公里/小时。控制器参数在训练城镇进行了调整。
3.2 Imitation learning
我们的第二种方法是条件模仿学习,这是一种模仿学习形式,除了感知输入之外还使用高级命令[4]。该方法利用了训练城镇中人类驾驶员记录的驾驶轨迹数据集。数据集![]() 由元组组成,每个元组包含一个观察oi、一个命令 ci 和一个动作 ai。这些命令由驾驶员在数据收集期间提供,并表明他们的意图,类似于转向信号。我们使用一组四个命令:保持车道(默认),在下一个路口直行,在下一个路口左转,在下一个路口右转。观察结果是来自前置摄像头的图像。为了提高学习策略的鲁棒性,我们在数据收集过程中注入了噪声。该数据集用于给定观察 o 和控制命令 c,训练深度网络以预测专家的动作 a。Codevilla et al. [4]提供了更多详细信息。
由元组组成,每个元组包含一个观察oi、一个命令 ci 和一个动作 ai。这些命令由驾驶员在数据收集期间提供,并表明他们的意图,类似于转向信号。我们使用一组四个命令:保持车道(默认),在下一个路口直行,在下一个路口左转,在下一个路口右转。观察结果是来自前置摄像头的图像。为了提高学习策略的鲁棒性,我们在数据收集过程中注入了噪声。该数据集用于给定观察 o 和控制命令 c,训练深度网络以预测专家的动作 a。Codevilla et al. [4]提供了更多详细信息。
我们收集了大约14小时的驾驶数据进行训练。该网络使用Adam优化器[14]进行了训练。为了提高泛化能力,我们进行了数据增强和dropout。补充资料中提供了更多详细信息。
3.3 Reinforcement learning
我们的第三种方法是深度强化学习,它基于环境提供的奖励信号训练深度网络,没有人类驾驶痕迹。我们使用异步优势actor-critic (A3C)算法[19]。该算法已被证明在模拟三维环境中的赛车[19]和三维迷宫导航[19, 13, 5]等任务中表现良好。该方法的异步特性允许并行运行多个模拟线程,考虑到深度强化学习的高样本复杂性,这一点很重要。
我们在目标导向导航上训练A3C。在每个训练集中,车辆必须在拓扑规划器的高级命令的指导下达到一个目标。当车辆到达目标时,当车辆与障碍物碰撞时,或者当时间预算用完时,回合终止。奖励是五个项的加权和:正加权的速度和向目标行驶的距离,负加权的碰撞损害,与人行道重叠,以及与对面车道重叠。补充资料中提供了更多详细信息。
4 Experiments
我们评估了这三种方法——模块化流水线(MP)、模仿学习(IL)和强化学习(RL)——在六种天气条件下,在两个可用城镇的每一个中,对四个越来越困难的驾驶任务进行评估。请注意,对于这三种方法中的每一种,我们在所有四个任务上都使用相同的智能体,并且不会针对每个场景单独进行微调。这些任务被设置为目标导向的导航:一个智能体在城镇的某个地方被初始化,并且必须到达一个目的地点。在这些实验中,智能体可以忽略速度限制和交通信号灯。我们按照难度递增的顺序组织任务如下:
- 直线:目的地在起点的正前方,环境中没有动态物体。到目标的平均行驶距离在城镇1为200米,在城镇2为100米。
- 一圈:目的地距离起点一圈; 没有动态对象。到目标的平均行驶距离在城镇1为400 m,在城镇2为170 m。
- 导航:目标点相对于起点的位置没有限制,没有动态对象。到目标的平均行驶距离在城镇1为770米,在城镇2为360米。
- 带有动态障碍物的导航:与上一个任务相同,但使用动态对象(汽车和行人)。
实验在两个城镇进行。城镇1用于训练,城镇2用于测试。我们为实验考虑了六种天气条件,分为两组。Training Weather Set用于训练,包括晴天、晴日落、白天下雨和雨后白天。Test Weather Set从未在训练期间使用过,包括白天多云和日落时的小雨。
对于任务、城镇和天气集的每种组合,将在25个回合中进行测试。在每一个回合中,目标是到达给定的目标位置。如果智能体在时间预算内达到目标,则认为回合成功。时间预算设置为以10 km/h的速度沿最佳路径到达目标所需的时间。违规行为,例如在人行道上驾驶或碰撞,不会导致回合终止,但会被记录和报告。
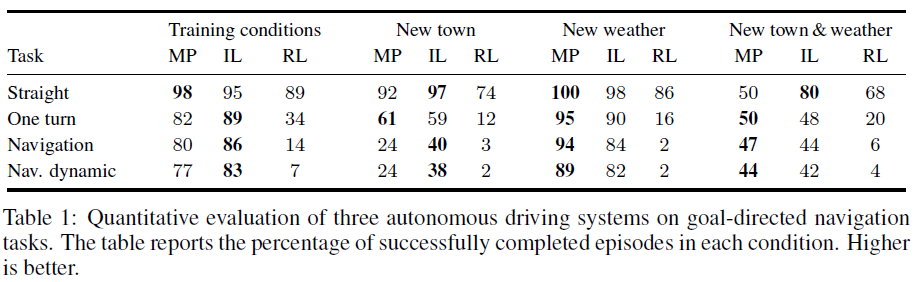
5 Results
表1报告了四种不同条件下成功完成回合的百分比。首先是训练条件:城镇1,Training Weather Set。请注意,开始和目标位置与训练期间使用的位置不同:只有一般环境和周围条件相同。其他三个实验条件测试更积极的概括:到以前看不见的城镇2和以前从未遇到过的来自Test Weather Set的天气。
表1中的结果表明了几个一般性结论。总体而言,即使在最简单的直线驾驶任务上,所有方法的性能也并不完美,对于更困难的任务,成功率进一步下降。推广到新天气比推广到新城镇更容易。模块化流水线和受过模仿学习训练的智能体在大多数任务和条件下表现相当。相对于其他两种方法,强化学习表现不佳。我们现在更详细地讨论这四个关键发现。
Performance on the four tasks. 令人惊讶的是,即使是在训练条件下在空荡荡的街道上直行的最简单任务,也没有一种方法能完美地执行。我们认为,造成这种情况的根本原因是智能体遇到的感官输入的可变性。训练条件包括四种不同的天气条件。训练期间驱动的确切轨迹在测试期间不会重复。因此,要完美地完成这项任务需要强大的泛化能力,这对现有的深度学习方法来说是一个挑战。
在更高级的任务上,所有方法的性能都会下降。在人口稠密的城市环境中最困难的导航任务中,两种最佳方法——模块化流水线和模仿学习——在所有条件下的成功率都低于90%,在测试城镇中的成功率低于45%。这些结果清楚地表明,即使在训练条件下,性能也远未达到饱和,对新环境的泛化提出了严峻的挑战。
Generalization. 我们研究了两种类型的概括:对以前看不见的天气条件和以前看不见的环境。有趣的是,这两者的结果截然不同。对于模块化流水线和模仿学习,"新天气"条件下的表现非常接近训练条件下的表现,有时甚至更好。然而,推广到新城镇对所有三种方法都提出了挑战。在两个最具挑战性的导航任务中,当切换到测试城镇时,所有方法的性能至少下降2倍。这种现象可以通过以下事实来解释:模型已经在多种天气条件下进行了训练,但在一个城镇中进行。不同天气的训练支持泛化到以前看不见的天气,但不适用于使用不同纹理和3D模型的新城镇。通过在不同环境中进行训练可能会改善该问题。总的来说,我们的结果强调了泛化对于基于学习的感觉运动控制方法的重要性。
Modular pipeline vs end-to-end learning. 分析模块化流水线和模仿学习方法的相对性能是有益的。这些系统代表了设计智能体的两种通用方法,CARLA可以在它们之间进行直接控制比较。
令人惊讶的是,在大多数测试条件下,两种系统的性能非常接近:两种方法的性能差异通常不到10%。 这个一般规则有两个值得注意的例外。一是模块化流水线在"新天气"条件下比在训练条件下表现更好。这是由于训练和测试天气的特定选择:感知系统恰好在测试天气上表现更好。两种方法之间的另一个区别是MP在"新城镇"条件下的导航和"新城镇和天气"条件下的直行方面表现不佳。这是因为在新环境的复杂天气条件下,感知堆栈会系统地失效。如果感知堆栈无法可靠地找到可行驶的路径,则基于规则的规划器和经典控制器无法以一致的方式导航到目的地。因此,性能是双峰的:如果感知堆栈有效,则整个系统运行良好;否则它会完全失败。从这个意义上说,MP比端到端方法更脆弱。
Imitation learning vs reinforcement learning. 我们现在对比两个端到端训练系统的性能:模仿学习和强化学习。在所有任务中,经过强化学习训练的智能体的表现都明显低于经过模仿学习训练的智能体。尽管RL是使用大量数据进行训练的:驾驶12天,而模仿学习使用14小时。尽管在Atari游戏[18, 19]和迷宫导航[19, 5]等任务上取得了不错的成绩,为什么RL表现不佳?一个原因是已知RL很脆弱[12],并且通常执行广泛的特定于任务的超参数搜索,例如Mnih et al. [19]报告的每个环境50次试验。当使用逼真的模拟器时,这种广泛的超参数搜索变得不可行。我们根据文献证据和迷宫导航探索性实验选择超参数。另一种解释是,城市驾驶比以前使用RL解决的大多数任务更困难。例如,与迷宫导航相比,在驾驶场景中,智能体必须在杂乱的动态环境中处理车辆动力学和更复杂的视觉感知。最后,强化学习的泛化能力差可能是因为与模仿学习相比,强化学习是在没有数据增强或正则化(如dropout)的情况下进行训练的。
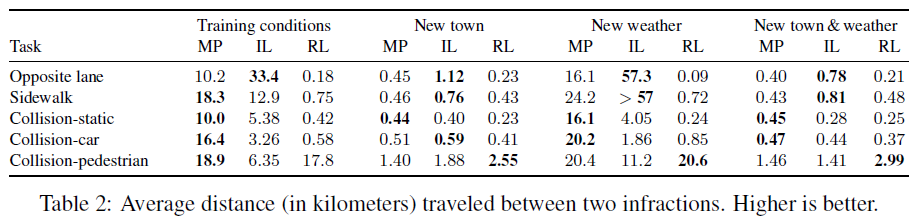
Infraction analysis. CARLA支持对驾驶策略的细粒度分析。我们现在检查三个系统在最困难任务上的行为:在动态对象存在的情况下导航。我们通过以下五种违规行为之间的平均距离来描述这些方法:在对面车道上行驶、在人行道上行驶、与其他车辆相撞、与行人相撞以及撞击静态物体。补充资料中提供了详细信息。
表2报告了两次违规之间的平均距离(以公里为单位)。所有方法在训练城镇中的表现都更好。在所有条件下,IL偏离对面车道的频率最低,而RL在该指标中是最差的。在转向人行道时观察到类似的模式。令人惊讶的是,RL与行人发生碰撞的频率最低,这可以用这种碰撞产生的大量负奖励来解释。然而,强化学习智能体在避免与汽车和静态物体的碰撞方面并不成功,而模块化流水线通常根据这一措施表现最好。
这些结果突出了端到端方法对罕见事件的敏感性:在训练期间很少发生为了避开行人而刹车或转弯的情况。虽然CARLA可用于在训练期间增加此类事件的频率以支持端到端方法,但学习算法和模型架构的更深层次的进步可能对于显著提高鲁棒性[3]是必要的。
6 Conclusion
我们展示了CARLA,一个用于自动驾驶的开放式模拟器。除了开源代码和协议之外,CARLA还提供了专门为此目的创建的数字资产,可以自由重复使用。我们利用CARLA的模拟引擎和内容来测试三种自动驾驶方法:经典的模块化流水线、通过模仿学习进行端到端训练的深度网络以及通过强化学习训练的深度网络。我们挑战这些系统在其他车辆和行人存在的情况下导航城市环境。CARLA为我们提供了开发和训练系统的工具,然后在受控场景中对其进行评估。模拟器提供的反馈可以进行详细的分析,突出特定的故障模式和未来工作的机会。我们希望CARLA能够让广大社区积极参与自动驾驶研究。模拟器和随附的资产将在http://carla.org上开源发布。
Supplementary Material
S.1 Simulator Technical Details
S.1.1 Client and Server Information Exchange
CARLA被设计为一个客户端-服务器系统。服务器运行并呈现CARLA世界。客户端通过控制智能体车辆和模拟的某些属性,为用户提供与模拟器交互的界面。
Commands. 智能体车辆由通过客户端发送的5种类型的命令控制:
- 转向:方向盘角度由-1和1之间的实数表示,其中-1和1分别对应全左和全右。
- 油门:油门踏板上的压力,以0到1之间的实数表示。
- 刹车:刹车踏板上的压力,以0到1之间的实数表示。
- 手刹:一个布尔值,指示手刹是否被激活。
- 倒档:一个布尔值,指示是否启用倒档。
Meta-commands. 客户端还可以使用以下元命令控制服务器的环境和行为:
- 车辆数量:将在城市中生成的整数数量的非玩家车辆。
- 行人数量:将在城市中生成的整数个行人。
- 天气Id:要使用的天气/照明预设的索引。目前支持以下:Clear Midday, Clear Sunset, Cloudy Midday, Cloudy Sunset, Soft Rain Midday, Soft Rain Sunset, Medium Rain Midday, Cloudy After Rain Midday, Cloudy After Rain Sunset, Medium Rain Sunset, Hard Rain Midday, Hard Rain Sunset, After Rain Noon, After Rain Sunset。
- 种子车辆/行人:控制非玩家车辆和行人如何生成的种子。通过设置相同的种子,可以具有相同的车辆/行人行为。
- Set of Cameras:一组具有特定参数的相机,例如位置、方向、视野、分辨率和相机类型。可用的相机类型包括光学RGB相机和提供真实深度和语义分割的伪相机。
Measurements and sensor readings. 客户端从服务器接收以下关于世界和玩家状态的信息:
- 玩家位置:玩家相对于世界坐标系的3D位置。
- 玩家速度:玩家的线速度,以km/h为单位。
- 碰撞:与三种不同类型的物体碰撞的累积影响:汽车、行人或静态物体。
- 对面车道交叉口:与对面车道重叠的玩家汽车足迹的当前部分。
- 人行道交叉口:与人行道重叠的玩家汽车足迹的当前部分。
- 时间:当前游戏时间。
- 玩家加速度:一个3D矢量,具有智能体相对于世界坐标系的加速度。
- 玩家方向:与智能体汽车方向相对应的单位长度向量。
- 传感器读数:来自一组相机传感器的当前读数。
- 非客户端控制的智能体信息:环境中存在的所有行人和汽车的位置、方向和边界框。
- 交通灯信息:所有交通灯的位置和状态。
- 限速标志信息:所有限速标志的位置和读数。
S.1.2 Environment
CARLA提供了两个城镇:城镇1和城镇2。图S.1显示了这些城镇的地图和代表性视图。为CARLA制作了大量的资产,包括汽车和行人。图S.2展示了这种多样性。


S.2 Driving Systems Technical Details
在本节中,我们为我们测试过的自动驾驶系统提供了额外的技术细节。
S.2.1 Modular Pipeline
S.2.2 Imitation Learning
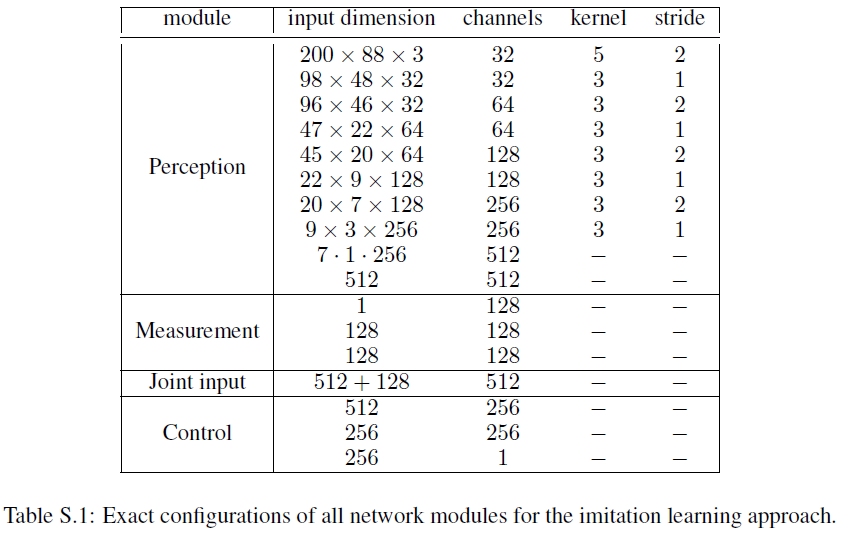
Architecture. 表S.1详细介绍了模仿学习方法[4]中使用的网络配置。该网络由四个模块组成:一个专注于处理图像输入的感知模块,一个处理速度输入的测量模块,一个融合感知和测量信息的联合输入模块,以及一个从关节输入表示产生电机命令的控制模块。控制模块由4个相同的分支组成:用于预测转向角、制动和油门的命令条件模块——四个命令一一对应。基于输入命令选择四个命令条件模块之一。感知模块由卷积网络实现,以200×88的图像为输入,输出512维的向量。所有其他模块均由全连接网络实现。测量模块将测量向量作为输入,并输出一个128维向量。
Training details. 我们用Adam [14]训练了所有网络。我们使用了120个样本的小批量。我们平衡了小批量,对每个命令使用相同数量的样本。我们的起始学习率为 0.0002,每50000次小批量迭代乘以0.5。我们总共训练了294000次迭代。动量参数设置为β1 = 0.7和β2 = 0.85。我们没有使用权重衰减,但在隐藏的全连接层之后执行了50%的dropout,在卷积层上执行了20%的dropout。为了进一步减少过拟合,我们通过添加高斯模糊、加性高斯噪声、像素dropout、加性和乘性亮度变化、对比度变化和饱和度变化来执行广泛的数据增强。在将原始800×600图像输入网络之前,我们在顶部裁剪了171个像素,在底部裁剪了45个像素,然后将生成的800×384图像的大小调整为200×88的分辨率。
Training data. 专家训练数据是从两个来源收集的:自动智能体和人类驾驶员数据。自动智能体可以访问特权信息,例如动态对象的位置、自我车道、交通信号灯的状态。80%的演示由自动智能体提供,20%由人类驾驶员提供。
为了提高学习策略的鲁棒性,我们在训练数据收集过程中将噪声注入到专家的转向中。也就是说,我们在随机时间点对驾驶员提供的转向角添加了扰动。扰动是一个三角脉冲:它线性增加,达到最大值,然后线性下降。这模拟了从所需轨迹的逐渐漂移,类似于训练有素的控制器可能发生的情况。三角脉冲由其起始时间t0、持续时间τ ∈ R+、符号σ ∈ {-1, +1}和强度γ ∈ R+参数化:
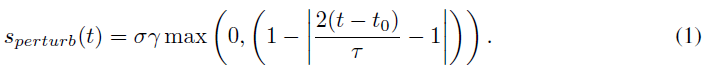
驾驶的每一秒,我们都会以概率pperturb开始扰动。我们在实验中使用了pperturb = 0.1。每个扰动的符号随机采样,持续时间从0.5到2秒均匀采样,强度固定为0.15。
S.2.3 Reinforcement Learning
我们的A3C智能体基于Mnih et al. [18]提出的网络架构。网络的输入包括智能体观察到的两张最近的图像,大小调整为84×84像素,以及一个测量向量。测量向量包括汽车的当前速度、到目标的距离、碰撞造成的损坏以及拓扑规划器提供的当前高级命令,采用one-hot编码。输入由两个独立的模块处理:卷积模块的图像,全连接网络的测量。两个模块的输出被连接起来并进一步联合处理。我们用10个并行的actor线程训练了A3C,总共有1000万个环境步骤。继Jaderberg et al. [13]之后,我们使用了20步rollout,初始学习率为0.0007,熵正则化为0.01。在训练过程中,学习率线性下降到零。
奖励是五个项的加权总和:向目标行驶的距离 d (以km为单位)、速度 v (以 km/h为单位)、碰撞损坏 c、与人行道的交叉点 s (介于0和1之间)以及与对面车道的交叉点 o (在0和1之间)。
![]()
S.3 Experimental Setup
S.3.1 Types of Infractions
我们通过以下五种违规行为之间的平均距离来描述这些方法:
- 对面车道:超过30%的汽车足迹位于错误的车道上。
- 人行道:超过30%的汽车足迹在人行道上。
- 与静态物体碰撞:汽车与静态物体接触,例如电线杆或建筑物。
- 与汽车碰撞:汽车与另一辆车发生接触。
- 与行人碰撞:汽车与行人发生碰撞。
每次违规的持续时间限制为2秒,因此如果汽车在人行道上停留10秒,这将被视为5次违规,而不是1次。