郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

AAAI 2022
Abstract
本文提出了一种新的序列模型学习架构来解决部分可观察的马尔可夫决策问题。与传统的基于循环神经网络的方法在每个时间步骤压缩序列信息不同,所提出的架构在每个数据块中生成一个具有多个时间步骤的潜在变量,并将最相关的信息传递给下一个块以进行策略优化。所提出的分块序列模型是基于自注意力实现的,使得该模型能够在部分可观察设置中进行详细的序列学习。所提出的模型构建了一个额外的学习网络,通过使用自归一化重要性采样来有效地实现梯度估计,这不需要模型学习中复杂的逐块输入数据重建。数值结果表明,所提出的方法在各种部分可观察的环境中明显优于以前的方法。
1 Introduction
部分可观察环境中的强化学习(RL)通常被表述为部分可观察马尔可夫决策过程(POMDP)。RL解决POMDP是一个具有挑战性的问题,因为马尔可夫观察假设被打破。过去的信息应该在学习阶段被提取和利用,以补偿由于部分可观察性造成的信息损失。部分可观察的情况在现实世界的问题中普遍存在,例如当观察有噪声时控制任务、删除部分基础状态信息或需要估计长期信息(Han, Doya, and Tani 2020b; Meng, Gorbet, and Kulic 2021)。
尽管已经设计了许多RL算法,并且最先进的算法在完全可观察的环境中提供了出色的性能,但提出的解决POMDP的方法相对较少。以前的POMDP方法使用循环神经网络(RNN)以无模型的方式压缩过去的信息(Hausknecht and Stone 2015; Zhu, Li, and Poupart 2017; Goyal et al. 2021)或估计潜在的状态信息并将估计结果用作RL智能体的输入(Igl et al. 2018; Han, Doya, and Tani 2020b)。这些方法在时间上以逐步的顺序压缩观察结果,当观察的偏向性很高并且在时间间隔内提取上下文信息的效率较低时,这可能是低效的。
我们推测在给定时间间隔内特定时间步骤的观察包含更多关于决策的信息。我们提出了一种新的架构,通过将这种直觉形式化为数学框架来解决部分可观察的RL问题。我们的贡献如下:
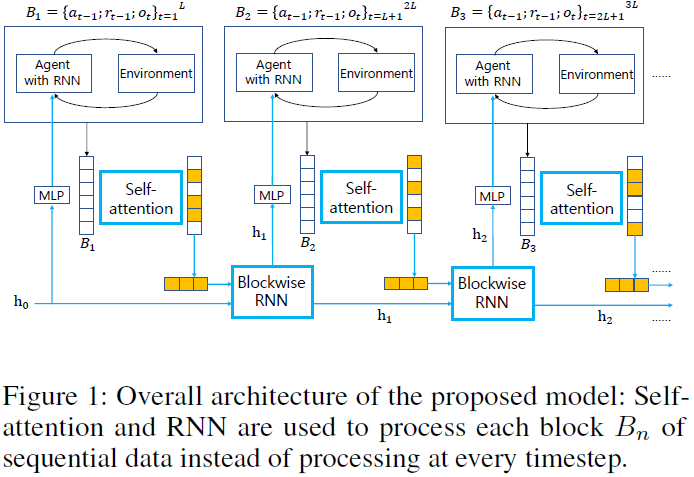
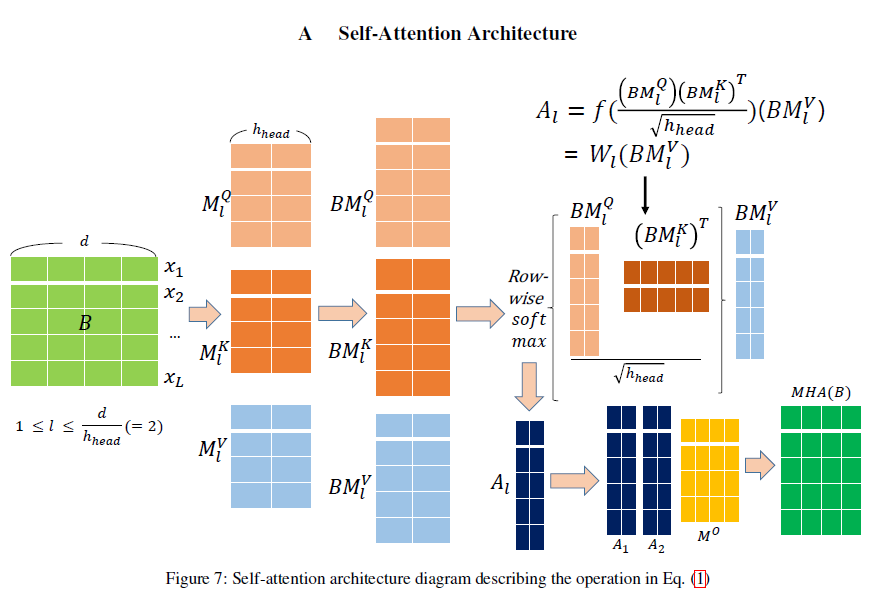
- 如图1所示,我们提出了一种基于序列输入块的新学习架构,而不是通过联合使用自注意(Vaswani et al. 2017)和RNN来估计每个时间步骤的潜在变量并利用每个结构体的优势。
- 为了学习所提出的架构,我们提出了一种基于使用自归一化重要性采样的直接梯度估计的分块序列模型学习(Bornschein and Bengio 2015; Le et al. 2019),与通常处理POMDP的变分方法相比,它不需要输入数据重建(Chung et al. 2015; Han, Doya, and Tani 2020b)。
- 使用提出的模型的提出的块表示并将学习的块变量提供给RL智能体,我们在几个POMDP环境中显著提高了现有方法的性能。
2 Related Work
在部分可观察的RL中,应该适当地利用过去的信息来补偿部分观察中的信息损失。RNN及其变体(Hochreiter and Schmidhuber 1997; Cho et al. 2014)已被用于处理过去的信息。最简单的方法是,由样本序列驱动的RNN的输出直接输入到RL智能体中,作为捕获过去信息的输入,无需进一步处理,正如之前的工作所考虑的那样(Hausknecht and Stone 2015; Zhu, Li, and Poupart 2017)。这些端到端方法的主要缺点是它需要大量数据来训练RNN,并且在某些复杂环境中效果不佳(Igl et al. 2018; Han, Doya, and Tani 2020b)。
Goyal et al. (2021)提出了RNN的一种变体,其中隐藏变量被分成多个等长的段。首先,使用注意力选择固定数量的片段(Vaswani et al. 2017)。然后,仅使用独立的RNN更新选定的片段,然后进行自注意,其余片段不变。我们的方法与这种方法有很大不同,因为我们在一段时间内使用注意力,而Goyal et al. (2021)的结构通过在同一时间步骤上使用对片段的注意力逐步更新。
其他方法通过学习逐步隐变量的序列模型来估计状态信息或信念状态。然后将推断出的潜在变量用作RL智能体的输入。Igl et al. (2018)提出通过在变分学习中应用粒子滤波器(Maddison et al. 2017; Le et al. 2018; Naesseth et al. 2018)来估计信念状态。Han, Doya和Tani (2020b)提出了一个Soft Actor-Critic (Haarnoja et al. 2018)基于方法(VRM),专注于解决部分可观察的连续动作控制任务。VRM添加动作序列作为附加输入,并使用回放缓冲区中的样本来最大化变分下限(Chung et al. 2015)。然后,生成潜在变量作为RL智能体的输入。然而,为了解决稳定性问题,VRM将 (i) 预训练和冻结的变量dfreeze和 (ii) 从不同模型中学习到的变量dkeep连接起来,因为仅使用dkeep作为RL智能体的输入不会提高性能。相比之下,我们的方法只使用一个块模型进行学习,效率更高。
虽然以前的方法在部分可观察的环境中提高了性能,但它们大多使用RNN。当观察偏向性很高时,RNN架构会遇到两个问题:(i) 遗忘问题和 (ii) 逐步压缩所有过去样本的效率低下,包括噪声等不必要的信息。我们的工作通过将最相关的信息传递到下一个块来逐块学习我们的模型来解决这些问题。
3 Background



然而,与RNN不同的是,在自注意中,每个数据块的处理都没有考虑前面的块,因此每个转换后的块数据都是断开的。因此,过去的信息不用于处理当前块。相比之下,RNN通过逐步累积来使用过去的信息,但是当数据序列变长时,RNN会出现遗忘问题。
4 Proposed Method
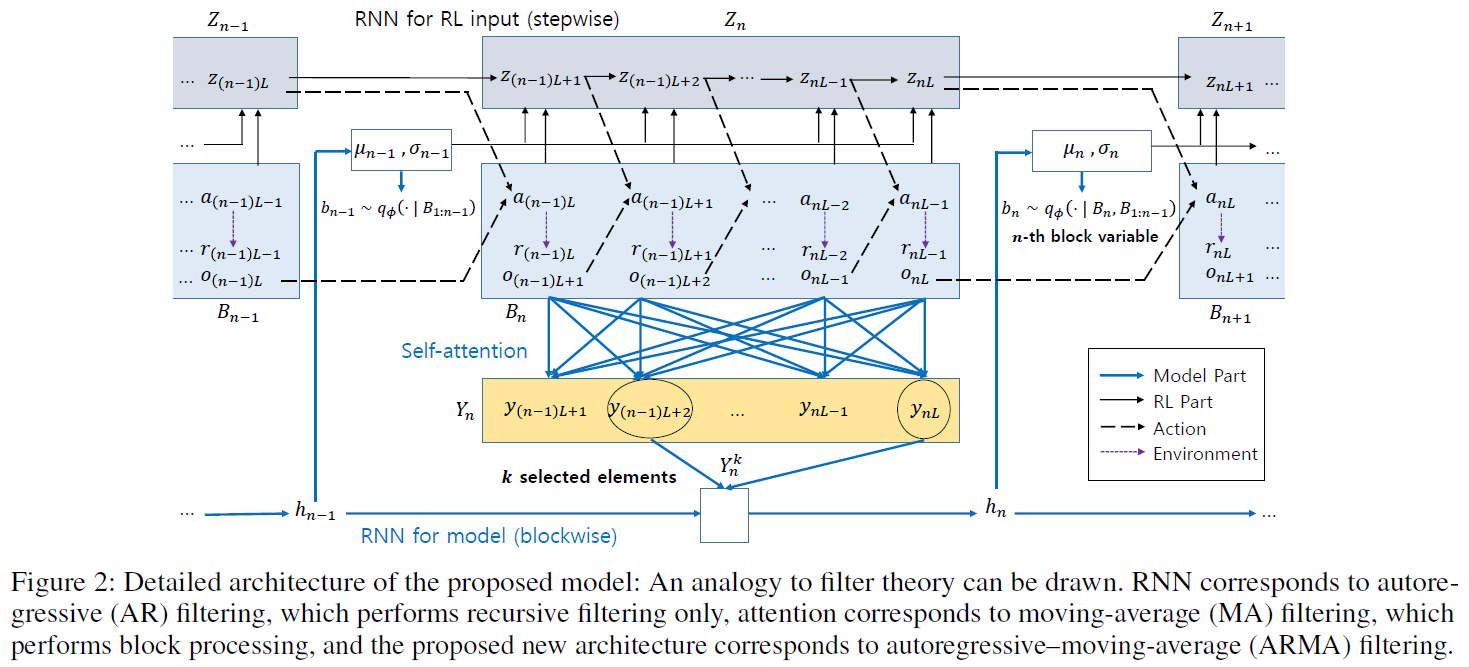
我们提出了一种新的POMDP架构,通过联合使用自注意和RNN并利用每种结构的优势对块潜在变量进行建模。所提出的架构包括 (i) 用于RL输入的逐步RNN和 (ii) 块模型。如果只使用逐步RNN,则对应朴素RNN方法。如图所示。如图1和2所示,块模型由自注意和块状RNN组成。在自注意压缩块信息之后,块状RNN将信息传递给下一个块。
我们在4.1节描述了块模型结构,包括块模型如何用于轨迹生成以及块信息是如何压缩的。第4.2节解释了如何有效地学习块模型以帮助RL更新。
4.1 Proposed Architecture





4.2 Efficient Block Model Learning




5 Experiments
在本节中,我们提供了一些数值结果来评估所提出的POMDP块模型学习方案。为了在各种部分可观察的环境中测试算法,我们考虑了以下四种部分可观察的环境:
- 每个状态都添加了随机噪声:Mountain Hike (Igl et al. 2018)
- 每个状态的某些部分缺失:Pendulum - 随机缺失版本(Brockman et al. 2016; Meng, Gorbet, and Kulic 2021)
- 需要记住悠久的历史:序列目标达成任务(Han, Doya, and Tani 2020a)
- 导航智能体无法在迷宫中观察整个地图:Minigrid (Chevalier-Boisvert, Willems, and Pal 2018)
请注意,所提出的方法(由Proposed表示)可以与任何通用RL算法相结合。对于前三个连续动作控制任务,我们使用Soft Actor-Critic (SAC)算法(Haarnoja et al. 2018)作为背景RL算法,它是一种异策RL算法。然后,我们将所提出方法的性能与 (i) SAC与原始观察输入(SAC)进行比较,(ii) SAC由LSTM (Hochreiter and Schmidhuber 1997)的输出辅助,这是RNN的一种变体,由观察序列驱动(LSTM), (iii) VRM,这是一种基于SAC的方法,用于部分可观察的连续动作控制任务(Han, Doya, and Tani 2020b),以及 (iv) RIM作为LSTM的替代品。三个性能比较图中的 y 轴代表最近100个回合在五个随机种子上的平均回报的平均值。
由于Minigrid环境具有离散的动作空间,我们不能使用SAC和VRM,而是使用PPO (Schulman et al. 2017)作为背景算法。然后将所提出的算法与PPO、PPO与LSTM以及PPO与RIM在五个种子上进行比较。(实现的细节在附录D中描述。)
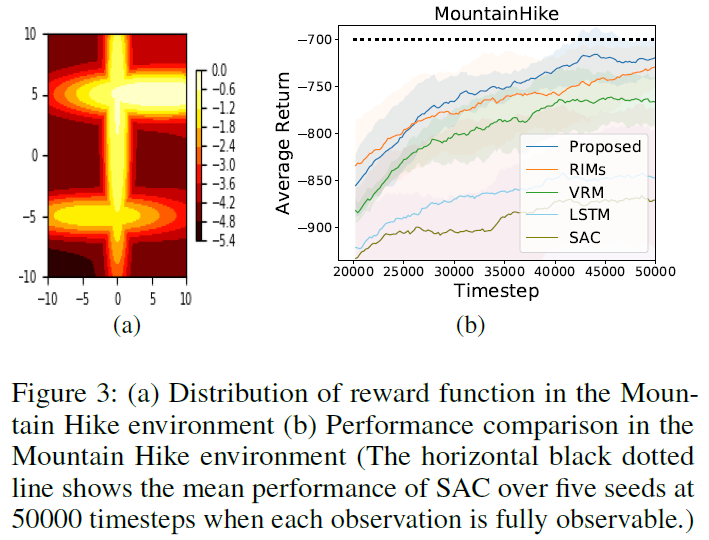
5.1 Mountain Hike
Mountain Hike中智能体的目标是通过沿着高回报区域的路径移动来最大化累积回报,如图3(a)所示。每个状态都是智能体的一个位置,但是接收到的观察结果是添加了高斯噪声。(详见附录E。) 在图3(b)中,可以看出所提出的方法优于Mountain Hike环境中的基线。水平黑色虚线显示了五个种子在50000步时的平均SAC性能,没有噪声。因此,所提出方法的性能在完全可观察的环境中几乎接近SAC的性能。
我们在训练结束时应用了Welch的 t 检验来统计检查所提出的方法相对于基线的增益。该测试对于比较不同的RL算法(Colas, Sigaud, and Oudeyer 2019)是稳健的。每个 p 值是所提出的算法不优于比较基线的概率。然后,所提出的算法以100(1-p)%的置信度优于比较基线。所提出的方法分别以73%和98%的置信度优于RIM和VRM。
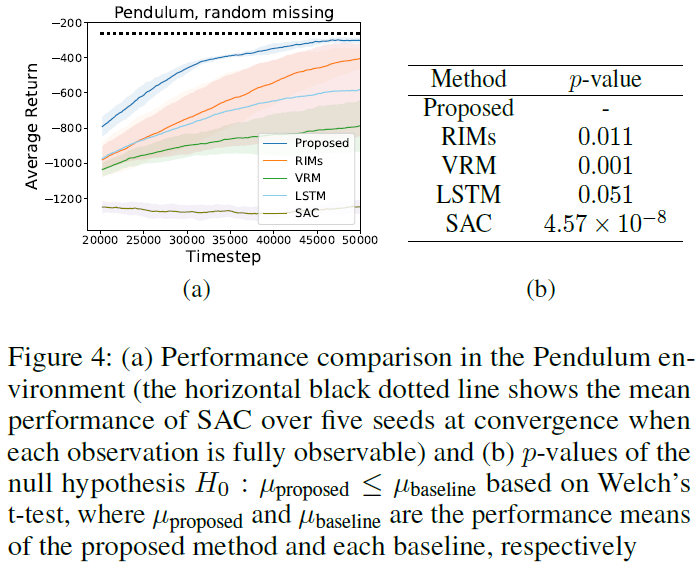
5.2 Pendulum - Random Missing Version
我们对钟摆控制问题进行了实验(Brockman et al., 2016),在该问题中,钟摆在每一集中都学会了向上摆动并保持直立。与原始的完全可观察版本不同,当智能体接收到观察时,每个状态的每个维度都以概率pmiss = 0.1转换为零(Meng, Gorbet, and Kulic 2021)。这种随机缺失设置会导致部分可观察性,并使简单的控制问题具有挑战性。
从图4(a)中可以看出,所提出的方法优于基线。水平黑色虚线显示当pmiss = 0.0时收敛时的平均SAC性能。如图4(a)所示,所提出的方法的性能几乎接近完全可观察环境中的SAC性能。图4(b)表明,所提出的方法分别以95%和99%的置信度优于LSTM和RIM。请注意,在图4(a)中,所提出方法的性能方差(为12.8)明显小于VRM和LSTM(分别为147.6和264.4)。这意味着所提出的方法比基线更稳定地学习。
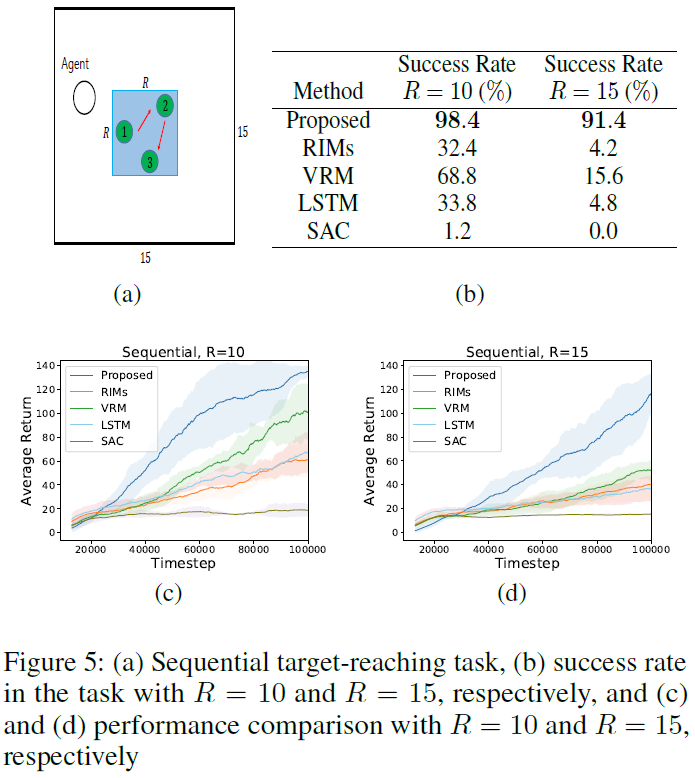
5.3 Sequential Target-reaching Task
为了验证所提出的模型可以有效地学习长期信息,我们在序列目标到达任务中进行了实验(Han, Doya, and Tani 2020a)。序列目标到达任务如图5(a)所示。智能体必须按1 → 2 → 3的顺序访问三个目标如图5(a)所示。访问第一个目标仅产生![]() ,访问第一个和第二个目标产生
,访问第一个和第二个目标产生![]() ,并按1 → 2 → 3的顺序访问所有三个目标产生
,并按1 → 2 → 3的顺序访问所有三个目标产生![]() ,其中
,其中![]() 。否则,智能体收到零奖励。当R(0 < R ≤ 15)增加时,三个目标之间的距离变大,任务变得更具挑战性。智能体必须记住并正确使用过去的信息才能获得全部奖励。
。否则,智能体收到零奖励。当R(0 < R ≤ 15)增加时,三个目标之间的距离变大,任务变得更具挑战性。智能体必须记住并正确使用过去的信息才能获得全部奖励。
从图5(c)和5(d)可以看出,所提出的方法明显优于基线。请注意,通过将R = 10增加到R = 15,随着任务变得更加困难,所提出的方法和基线之间的性能差距会变大。Welch 的 t 检验表明,当R = 10时,所提出的方法以98%的置信水平优于VRM。当R = 15时,与VRM相比的 p 值为2.84 × 10-4。
成功率是除平均回报之外的另一种衡量标准,它消除了在序列目标达到任务中通过奖励函数选择的高估。在训练了块模型和RL智能体之后,我们加载了训练好的模型,为每个模型评估了100个回合,并检查了模型以正确的顺序成功达到所有三个目标的次数。在图5(b)中,可以看出所提出的方法大大优于其他基线。
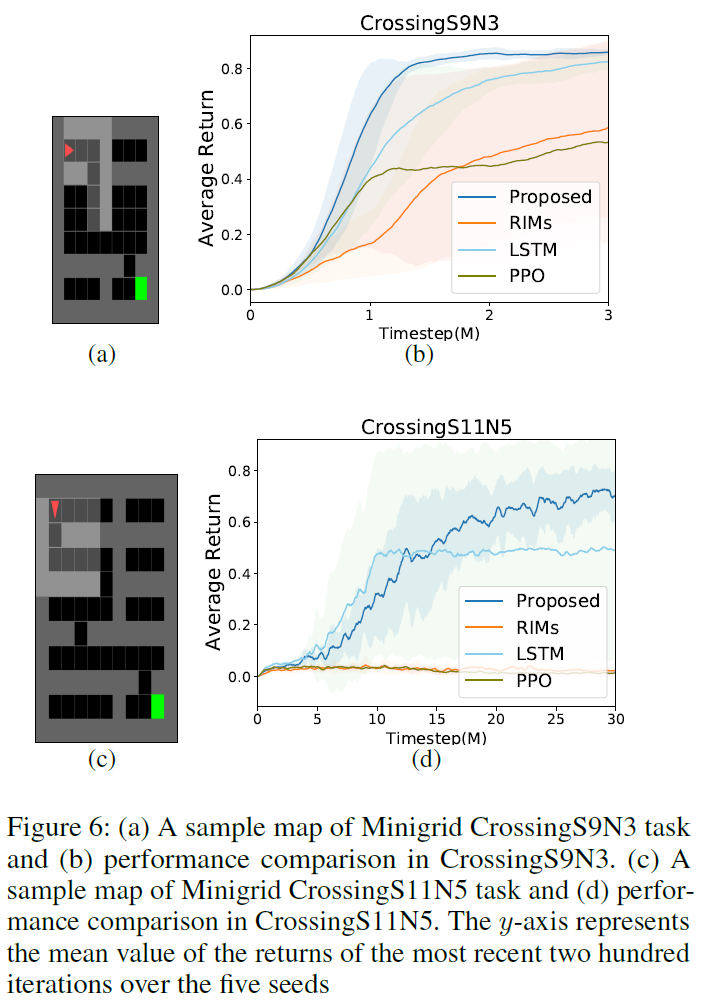
5.4 Minigrid
我们考虑了具有稀疏奖励的部分可观察迷宫导航环境,如图6(a)和6(c)所示(Chevalier-Boisvert, Willems, and Pal 2018)。智能体(红色三角形)仅在到达绿色方块时才收到非零奖励![]() ,其中Nmax是最大回合长度,tstep(≤Nmax)是成功前的总时间步长。否则,智能体将获得零奖励。每一个回合都会生成一个大小相同但形状不同的新地图,并且智能体会再次开始导航。智能体必须学会通过部分观察和稀疏奖励来穿越狭窄的路径。(有关详细信息,请参阅附录E。)
,其中Nmax是最大回合长度,tstep(≤Nmax)是成功前的总时间步长。否则,智能体将获得零奖励。每一个回合都会生成一个大小相同但形状不同的新地图,并且智能体会再次开始导航。智能体必须学会通过部分观察和稀疏奖励来穿越狭窄的路径。(有关详细信息,请参阅附录E。)
从图6(b)和6(d)可以看出,即使地图大小增加并且难度变得更高,所提出的方法也优于所考虑的基线。根据Welch的 t 检验,所提出的方法优于PPO with RIMs (RIMs)、PPO with LSTM (LSTM)和PPO分别为93%, 98%和94% (6(b))。图6(d)中LSTM的 p 值为0.159。
6 Ablation Study
回想一下,所提出的块模型由块状RNN和自我注意组成。在第6.1节中,我们研究了对块状RNN和自注意力的性能改进的贡献。在第6.2节中,我们将提出的压缩方法替换为其他方法,同时使用相同的自注意力。(有关超参数 L 和 k 的影响,请参见附录F。)
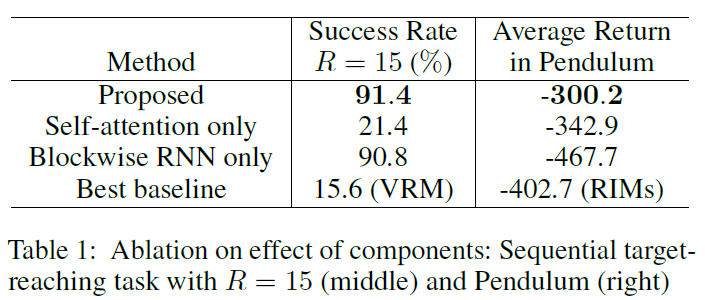
6.1 Effect of Components
我们包括仅使用自注意力而不使用块状RNN的方法(表示为"仅自注意力")。![]()
![]() ,来自 k 个选定元素的串联的单个向量,被馈送到RL智能体而不是μn和σn。自注意力与RL智能体进行端到端的训练。
,来自 k 个选定元素的串联的单个向量,被馈送到RL智能体而不是μn和σn。自注意力与RL智能体进行端到端的训练。
我们还通过用前馈神经网络(FNN)替换自注意力来添加仅使用没有自注意力的块状RNN的方法("仅块状RNN")。替换的FNN将块中的每个d维输入xt ∈ Bn映射到SFNN维向量。代替![]() ,(L · SFNN)维变换块用于块状RNN输入。为了公平比较,我们设置SFNN使得L · SFNN等于
,(L · SFNN)维变换块用于块状RNN输入。为了公平比较,我们设置SFNN使得L · SFNN等于![]() (= k · d)的维度。
(= k · d)的维度。
在表1中,我们观察到块状RNN在序列目标到达任务和Pendulum的性能改进中起着至关重要的作用。在Pendulum中,自注意力的效果对于性能提升至关重要。
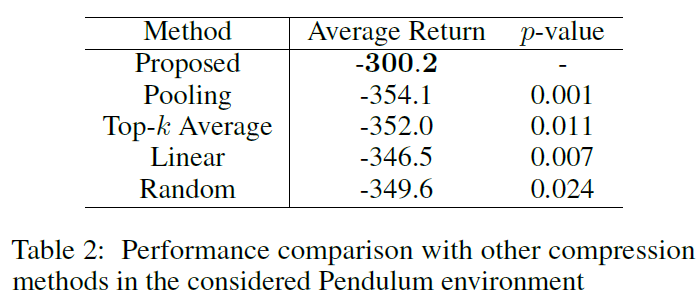
为了检查所提出的从Yn中选择![]() 的压缩方法的有效性,我们在Pendulum环境中与其他压缩方法进行了性能比较。在所提出的方法中,不是使用
的压缩方法的有效性,我们在Pendulum环境中与其他压缩方法进行了性能比较。在所提出的方法中,不是使用![]() 作为块状RNN的输入,而是使用 (i)
作为块状RNN的输入,而是使用 (i) ![]() (池化),(ii) 对中的 k 个选定元素进行平均Yn由归一化对应贡献加权(Top-k平均值),(iii) [Mcompy(n-1)L+1; · · · ; McompynL]具有可训练矩阵
(池化),(ii) 对中的 k 个选定元素进行平均Yn由归一化对应贡献加权(Top-k平均值),(iii) [Mcompy(n-1)L+1; · · · ; McompynL]具有可训练矩阵![]() (线性),或 (iv) 在Yn(随机)中随机选择的 k 个元素。
(线性),或 (iv) 在Yn(随机)中随机选择的 k 个元素。
比较结果如表2所示。在Pendulum中,自注意力具有有效的压缩能力,因为所有考虑使用自注意力的压缩方法都优于第6.1节中的"Blockwise RNN only"方法(平均为-467.7)。在所考虑的具有自注意力的压缩方法中,所提出的方法引起的相关信息丢失最少。
7 Conclusion
在本文中,我们提出了一种新的用于POMDP的分块顺序模型学习。所提出的模型使用自注意力对每个数据块压缩输入样本序列,并使用RNN将压缩信息传递给下一个块。来自块模型的压缩信息与相应的数据块一起输入到RL智能体中,以提高POMDP中的RL性能。所提出的架构是基于使用自归一化重要性采样的直接梯度估计来学习的,从而提高了学习效率。通过利用自注意力和RNN的优势,所提出的方法在考虑的部分可观察环境中优于以前的POMDP方法。




D Details in Implementation
E Details in Environments
E.1 Mountain Hike
E.2 Minigrid
F Effect of Hyperparameters
G Related Work on Sequential Representation Modeling
H Limitation and Future Work
I Social Impact