郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

PHYSICAL REVIEW E, (2004): 041909-041909
Abstract
人工神经网络通常通过使用反向传播算法来计算目标函数相对于突触强度的梯度来训练。对于生物神经网络,由于神经元中内在和突触电导的复杂动力学,这种梯度计算将难以实现。在此,我们表明类似于在生物神经元中观察到的不规则脉冲可以用作计算梯度随机*似的学习规则的基础。学习规则是基于一类特殊的模型网络推导出来的,其中神经元发放具有泊松统计的脉冲序列。学习与突触动力学的形式兼容,例如短期促进和抑制。通过将不规则脉冲的波动与奖励信号相关联,学习规则在期望奖励上执行随机梯度上升。它应用于两个示例,学习XOR计算和使用抑制突触学习方向选择性。我们还在模拟中表明,学习规则适用于带噪的IF神经元网络。
I. INTRODUCTION
II. BASIC DEFINITIONS
我们考虑一个模型网络,其中每个神经元接收一个总突触电流Ii(t)并产生一个具有瞬时发放率的泊松脉冲序列:

其中 fi 是第 i 个神经元的电流-放电关系或f-I曲线。神经元 i 接收的总突触电流由对突触前神经元 j 的贡献之和给出:
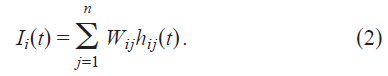
Wij是从神经元 j 到神经元 i 的突触强度。由于神经元 j 的脉冲,神经元 i 中的突触电流Wijhij(t)的行为时间过程为:
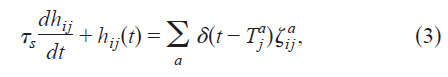
其中![]() 是神经元 j 的第 a 个脉冲的时间。
是神经元 j 的第 a 个脉冲的时间。![]() 是一个二元随机变量,用于模拟神经递质响应突触前脉冲的随机释放。
是一个二元随机变量,用于模拟神经递质响应突触前脉冲的随机释放。![]() 表示神经递质从神经元 j 到神经元 i 的释放事件,以响应神经元 j 的第 a 个脉冲,
表示神经递质从神经元 j 到神经元 i 的释放事件,以响应神经元 j 的第 a 个脉冲,![]() =0表示非释放事件。突触可以是动态的,在这种情况下,释放变量
=0表示非释放事件。突触可以是动态的,在这种情况下,释放变量![]() 取决于经历短期动态效应(如抑制或促进[11-13])的神经递质释放的历史。
取决于经历短期动态效应(如抑制或促进[11-13])的神经递质释放的历史。
在我们的突触传递模型中,突触后电流响应突触前释放事件而瞬间跳跃,否则随着时间常数τs呈指数衰减[图1(a)]。突触后电流的幅度由突触强度Wij决定。
公式(3)是一个简单的突触模型,但是用更复杂的动力学方程代替它没有障碍。一个更严重的限制是公式(1),它在统计上模拟脉冲生成,而不参考生物物理学。
严格来说,即将介绍的学习规则的有效性取决于泊松假设。然而,我们希望学习规则在脉冲*似泊松的条件下对更现实的基于电导的模型神经元网络有效。例如,通过将白噪声注入每个模型神经元,可以使这样的网络以低发放率*似泊松发放。或者,*似泊松脉冲可能来自具有*衡激发和抑制的网络中突触输入的内部产生的波动[14]。
III. LEARNING RULE
我们首先考虑学习规则的回合形式。假设学习过程分为不同的回合。网络在每回合开始时以固定的初始条件或从某个概率分布中随机抽取的条件重新初始化。对于每一个回合,网络的性能由奖励函数 R 评估,该函数取决于脉冲序列。
在每一个回合结束时,突触权重更新为:
![]()
其中η>0是学习率,R是奖励信号,eij是从神经元 j 到 i 的突触的资格迹。资格迹被定义为:

其中![]() 是神经元 i 的脉冲序列,T 是一个回合的长度。函数
是神经元 i 的脉冲序列,T 是一个回合的长度。函数![]() 是一个正因子,假设fi单调递增。
是一个正因子,假设fi单调递增。
在下一节中,显示了公式(4)右侧的期望值与期望奖励相对于Wij的梯度成正比。这意味着学习规则对期望奖励执行随机梯度上升。学习规则可以应用于前馈或循环网络。
资格迹,公式(5),取决于突触前和突触后的活动。突触前活动通过突触激活hij(t)做出贡献,该激活在神经元 j 的每个脉冲成功传输后升高。突触后神经元通过si(t)-fi(t)做出贡献,按正因子Φi缩放。
在这个学习规则中,突触变化取决于全局奖励信号和神经脉冲波动之间的相关性。学习规则可以直观理解如下。当神经元中大于期望的活动导致更大的奖励时,应该增加该神经元的总输入。因此,我们增加了该神经元的兴奋性突触权重并降低了抑制性突触权重。相反,如果大于期望的活动导致奖励减少,我们会降低兴奋性突触权重并增加该神经元的抑制性突触权重。
学习规则公式(4)中的资格迹取决于突触后活动远离其*均活动的波动,其期望值为零(下一节中的证明)。因此,如果奖励函数是恒定的,或者与资格迹不相关,则*均突触强度不会发生变化。因此,在公式(4)的学习规则中,只要R0与脉冲序列的泊松随机性不相关,我们就可以用R−R0代替R。使用R0不会改变突触强度的期望值,但精心选择的R0可能有助于减少每次更新的方差。
IV. DERIVATION OF THE LEARNING RULE
V. ONLINE LEARNING
VI. APPLICATION OF THE LEARNING RULE
A. Learning XOR computation
B. Learning direction selectivity using dynamic synapses
VII. NETWORKS OF INTEGRATE-AND-FIRE NEURONS
VIII. DISCUSSION
我们提出了一种突触更新规则,用于在脉冲神经网络中学习。我们表明学习规则*均在期望奖励函数上执行梯度上升。该算法本身并不明确计算梯度信息,而是使用全局奖励信号与神经活动波动之间的相关性来估计梯度。
学习规则取决于突触前和突触后神经元的脉冲。最*的实验已经证明了依赖于突触前和突触后脉冲的时间顺序的突触可塑性类型。在皮质和海马突触中,突触前脉冲和随后的突触后脉冲的重复配对会诱导长期增强,而当顺序颠倒时会导致长期抑制[21,22]。为了诱导任一类型的可塑性,突触前和突触后脉冲之间的时间差必须在很短的时间窗口内。
严格地将我们的学习规则与此类实验联系起来是不可能的,因为体外脉冲与泊松相去甚远。为了正确建立联系,有必要将学习规则扩展到比泊松模型在生物物理上更现实的脉冲模型,这是目前工作范围之外的任务。但是,可以提出以下启发式论证。资格迹是通过滤波![]() 确定的,因此其符号由主导差异的项sihij或fihij控制。神经元 j 中的一个单独的突触前脉冲在hij中建立了一个指数衰减的迹。如果紧随其后的是突触后脉冲,那么sihij将支配 fihij。如果它紧接在一个突触后脉冲之前,则sihij=0,但fihij可能不为零(这是否正确取决于学习规则如何扩展到非泊松情况)。因此,资格迹可能会改变符号,这取决于突触前和突触后脉冲的时间顺序。
确定的,因此其符号由主导差异的项sihij或fihij控制。神经元 j 中的一个单独的突触前脉冲在hij中建立了一个指数衰减的迹。如果紧随其后的是突触后脉冲,那么sihij将支配 fihij。如果它紧接在一个突触后脉冲之前,则sihij=0,但fihij可能不为零(这是否正确取决于学习规则如何扩展到非泊松情况)。因此,资格迹可能会改变符号,这取决于突触前和突触后脉冲的时间顺序。
关于脉冲时序依赖可塑性的实验并未试图控制任何奖励信号。如果存在任何奖励电路,尚不清楚它是否会在体外起作用。如果我们假设奖励信号在体外被冻结在某个正值,那么上述关于资格迹符号的论点暗示了Bi和Poo以及Markram等人[21,22]观察到的脉冲时序依赖可塑性的形式。另一方面,如果奖励信号被冻结在某个负值,则学习规则将导致相反时间顺序的增强,正如Bell等人[23]所观察到的那样。根据这种解释,由突触前和突触后脉冲诱导的可塑性时间窗口由突触后电流的时间常数决定。
在本文中,我们从一个简单的泊松脉冲模型推导出算法。我们推测,基于局部神经活动波动和全局奖励信号之间的相关性更新突触强度的想法可能适用于生物物理神经元网络。然而,为了让算法正常工作,每个神经元都应该有一个估计其*均活动的机制,即学习规则。如果突触后神经元的输入变化缓慢,则神经元可以根据先前的脉冲估计其*均活动,例如通过低通滤波。但是,如果输入快速变化,这种机制将无法工作。解决此问题的一种可能方法是将噪声注入神经元,并修改学习规则以依赖于注入噪声和全局奖励信号之间的相关性。这样,每个神经元只需要检测注入噪声的统计信息,而与它自己的活动无关。如果注入的噪声接*于*稳,则通过突触后神经元估计其方差变得相对容易。解决该问题的另一种可能方法是使用时间方差而不是神经活动的统计方差。例如,我们可以根据神经活动的时间方差和奖励函数的时间方差之间的相关性来修改算法以更新突触强度。
学习更新是对期望奖励函数梯度的噪声估计。该估计的信噪比趋于随着网络规模的增加而恶化,因为奖励与任何单个神经元脉冲波动的相关性变得更弱。因此,与其他类型的强化学习[2,3,15]类似,学习规则在大型网络中收敛缓慢。然而,这里提出的学习规则应该比将奖励与突触功效波动相关联的算法更快[2,3]。加速强化学习的一种方法是将大型学习问题分解为较小的子问题,每个子问题由一个由单独的奖励信号训练的模块学习[24]。如何构建这样一个层次结构的组织是一个需要解决的具有挑战性的问题。
学习规则严重依赖于奖励信号的调节。研究此类奖励信号的存在并操纵它们以改变突触可塑性的过程是未来实验研究的一个有趣主题。