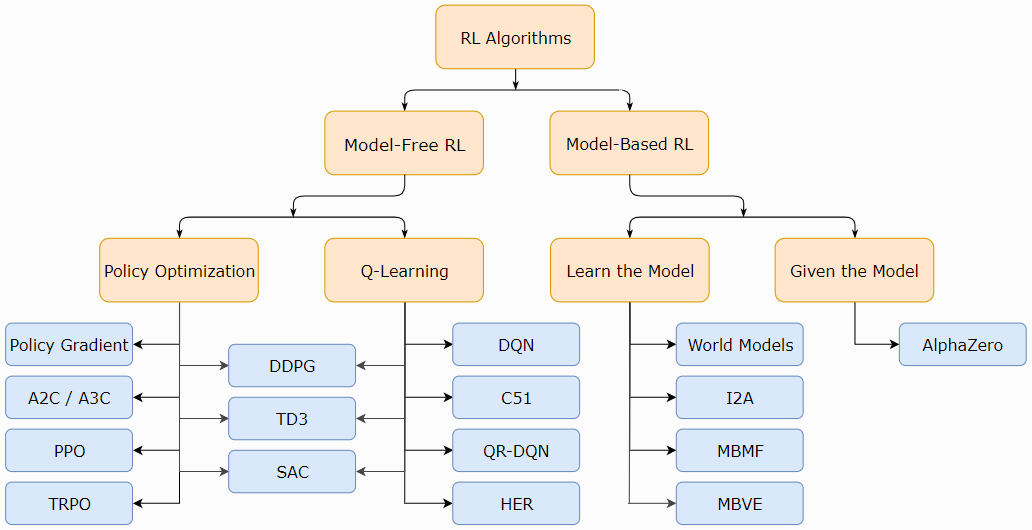
现代RL中一种非详尽但有用的算法分类法。
图片源自:OpenAI Spinning Up (https://spinningup.openai.com/en/latest/spinningup/rl_intro2.html#citations-below)
强化学习算法:
参考文献:Part 2: Kinds of RL Algorithms — Spinning Up documentation (openai.com)
强化学习模型实现RL-Adventure(DQN) - 穷酸秀才大艹包 - 博客园 (cnblogs.com)
基于策略梯度的强化学习论文调研 - 穷酸秀才大艹包 - 博客园 (cnblogs.com)
强化学习中的经验回放(The Experience Replay in Reinforcement Learning) - 穷酸秀才大艹包 - 博客园 (cnblogs.com)
元强化学习简介 - 穷酸秀才大艹包 - 博客园 (cnblogs.com)
Model-Free vs Model-Based RL
RL算法中最重要的分支点之一是智能体是否能够访问(或学习)环境模型的问题。我们所说的环境模型是指预测状态转换和奖励的函数。
拥有一个模型的主要好处是,它允许智能体通过提前思考、看到一系列可能的选择会发生什么,并明确地在其选项之间做出决定来进行规划。然后,智能体可以将预先规划的结果提取到一个学到的策略中。这种方法的一个特别著名的例子是AlphaZero。当这种方法起作用时,与没有模型的方法相比,它可以大大提高样本效率。
主要的缺点是,智能体通常无法使用环境的真实模型。如果一个智能体想要在这种情况下使用一个模型,它必须完全从经验中学习模型,这会带来一些挑战。最大的挑战是,模型中的偏差可以被智能体利用,从而导致智能体在学习模型方面表现良好,但在真实环境中表现得次优(或超级糟糕)。模型学习从根本上说是很难的,所以即使是愿意投入大量时间和计算的巨大努力也可能没有回报。
使用模型的算法称为基于模型(model-based)的方法,不使用模型的算法称为无模型(model-free)方法。虽然无模型方法放弃了使用模型在样本效率方面的潜在收益,但它们往往更易于实现和调整。截至目前,与基于模型的方法相比,无模型方法更受欢迎,并且得到了更广泛的开发和测试。
What to Learn
RL算法的另一个关键分支点是学习什么的问题。通常的候选名单包括:
- 策略,无论是随机的还是确定性的,
- 动作-价值函数(Q函数),
- 价值函数,
- 和/或环境模型。
What to Learn in Model-Free RL
本文主要考虑无模型RL,使用无模型RL表示和训练智能体有两种主要方法:
Policy Optimization. 这个族中的方法将策略显式表示为πθ(a|s)。它们通过在性能目标J(πθ)上的梯度上升直接优化参数θ,或通过最大化J(πθ)的局部近似间接优化参数θ。这种优化几乎总是在策略上执行的,这意味着每次更新只使用根据策略的最新版本进行操作时收集的数据。策略优化通常还包括为同策价值函数Vπ(s)学习近似器VΦ(s),该函数用于确定如何更新策略。
策略优化方法的几个示例如下:
Q-Learning. 这个族中的方法学习最优动作-价值函数Q*(s, a)的近似器Qθ(s, a)。通常,他们使用基于贝尔曼方程的目标函数。这种优化几乎总是根据策略执行的,这意味着每次更新都可以使用在训练期间的任何时间点收集的数据,而不管获取数据时智能体选择如何探索环境。通过Q*和π*之间的连接获得相应的策略:Q学习智能体采取的动作由下式给出:
![]()
Q学习方法的例子包括:
Trade-offs Between Policy Optimization and Q-Learning. 策略优化方法的主要优势在于它们是有原则的,也就是说,你可以直接为你想要的东西进行优化。这往往使它们稳定可靠。相比之下,Q学习方法只能通过训练Qθ以满足自洽方程,间接优化智能体性能。这种学习有很多失败模式,所以它往往不太稳定。[1] 但是,Q学习方法的优点是,它们在工作时的样本效率大大提高,因为与策略优化技术相比,它们可以更有效地重用数据。
Interpolating Between Policy Optimization and Q-Learning. 巧合的是,策略优化和Q学习并非不兼容(在某些情况下,事实证明,它们是等效的),而且存在一系列介于这两个极端之间的算法。基于这一范围的算法能够仔细权衡双方的优缺点。例子包括:
- DDPG,一种同时学习确定性策略和Q函数的算法,通过使用它们来改进另一个,
- TD3:虽然DDPG有时可以获得很好的性能,但它在超参数和其他类型的调整方面往往很脆弱。DDPG的一种常见故障模式是,学习的Q函数开始大幅高估Q值,然后导致策略中断,因为它利用了Q函数中的错误。双延迟DDPG(TD3)是一种通过引入三个关键技巧来解决此问题的算法,使性能大大优于基准DDPG:
- 技巧一:裁剪双重Q学习(Clipped Double-Q Learning)。TD3学习两个Q函数而不是一个(因此是"twin"),并使用两个Q值中较小的一个来形成Bellman误差损失函数中的目标。
-
- 技巧二:"延迟"策略更新("Delayed" Policy Updates)。TD3更新策略(和目标网络)的频率低于Q函数。本文建议每两次Q函数更新后进行一次策略更新。
- 技巧三:目标策略平滑(Target Policy Smoothing)。TD3向目标动作添加了噪声,使策略更难通过随着动作的变化平滑Q来利用Q函数错误。
- SAC,一种变体,它使用随机策略、熵正则化和其他一些技巧来稳定学习,并在标准基准上获得高于DDPG的分数。
[1] 有关Q学习方法失败的方式和原因的更多信息,请参见 1)Tsitsiklis and van Roy的这篇经典论文,2)Szepesvari的评论(见第4.3.2节),以及3)Sutton and Barto的第11章,尤其是第11.3节(关于函数近似、自举(bootstrapping)和异策数据的"致命三元组",共同导致价值学习算法的不稳定性)。
What to Learn in Model-Based RL
与无模型RL不同,基于模型的RL有不少易于定义的方法集群:有许多正交的使用模型的方法。我们将举几个例子,但列表远非详尽无遗。在每种情况下,模型可以是给定的,也可以是学到的。
Background: Pure Planning. 最基本的方法从不明确表示策略,而是使用模型预测控制(MPC)等纯规划技术来选择动作。在MPC中,每次智能体观察环境时,它都会计算一个相对于模型最优的规划,其中该规划描述了在当前之后的某个固定时间窗口中接管的所有动作。(规划算法可以通过使用学到的价值函数来考虑超出范围的未来奖励。) 智能体然后执行规划的第一个动作,并立即丢弃其余的动作。每次准备与环境交互时,它都会计算一个新规划,以避免使用规划范围短于预期的规划中的动作。
- MBMF工作在深度RL的一些标准基准测试任务上探索了具有学习环境模型的MPC。
Expert Iteration. 纯规划的直接后续涉及使用和学习策略的显式表征,πθ(a|s)。智能体在模型中使用规划算法(如蒙特卡洛树搜索),通过从其当前策略中采样为规划生成候选动作。规划算法产生的动作比单独的策略会产生的更好,因此它是相对于策略的"专家"。随后更新该策略以产生更像规划算法输出的动作。
- ExIt算法使用这种方法来训练深度神经网络玩Hex。
- AlphaZero是这种方法的另一个例子。
Data Augmentation for Model-Free Methods. 使用无模型RL算法来训练策略或Q函数,但要么 1) 在更新智能体时用虚构的经验来增强真实体验,要么 2) 只使用虚构的经验来更新智能体。
- 请参见MBVE,了解使用虚构体验增强真实体验的示例。
- 有关使用纯虚构经验训练智能体的示例,请参见World Models,他们称之为"梦中训练"。
Embedding Planning Loops into Policies. 另一种方法将规划过程作为子程序直接嵌入到策略中——这样完整的规划就成为策略的辅助信息——同时使用任何标准的无模型算法训练策略的输出。关键概念是,在这个框架中,策略可以学会选择如何以及何时使用这些规划。这使得模型偏差不再是一个问题,因为如果模型在某些状态不利于规划,策略可以简单地学会忽略它。
- 有关具有这种想象力的智能体的示例,请参见I2A。