郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

AAAI Fall Symposia, (2015): 29-37
Abstract
深度RL已经为复杂的任务提供了精通的控制器。但是,这些控制器的内存有限,并且依赖于能够在每个决策点感知完整的游戏画面。为了解决这些缺点,本文研究了用循环LSTM替换卷积后的第一个全连接层,从而在DQN中增加循环的影响。最终的DRQN尽管每个时间步骤只能看到一个帧,但可以成功地随时间整合信息,并在标准Atari游戏和具有闪烁游戏画面的部分可观察的等效游戏中达到与DQN相当的性能。此外,在接受部分观测值训练并逐步评估更完整的观测值后,DRQN的性能随可观察性而改变。相反,当接受完整观察并经过部分观察评估时,DRQN的性能下降幅度要小于DQN。因此,在相同长度的历史记录下,循环可以替代在DQN的输入层中堆叠帧的历史记录,并且尽管循环在学习游戏时没有系统性的优势,但如果循环网络可以更好地适应评估时间内观测质量发生变化的情况。
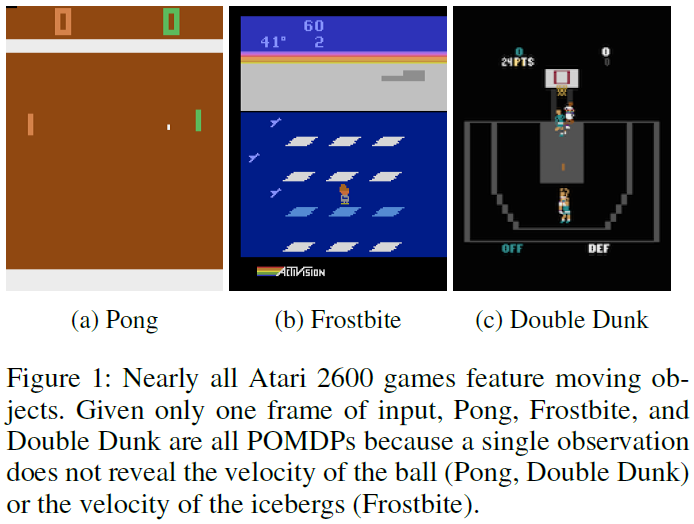
Introduction
事实证明,DQN能够在各种不同的Atari 2600游戏中学习人类级别的控制策略(Mnih et al., 2015)。就像它们的名字一样,DQN学会估计从当前游戏状态中选择每个可能动作的Q值(或长期折扣回报)。假设网络的Q值估计足够准确,则可以通过在每个时间步骤选择具有最大Q值的动作来玩游戏。这些策略网络学习了从原始屏幕像素到动作的映射策略,在许多Atari 2600游戏中均表现出了一流的性能。
但是,DQN从有限的过去状态或Atari 2600的游戏屏幕中学习映射的意义是有限的。在实践中,DQN的训练使用的是智能体已遇到的最后四个状态组成的输入。因此,DQN将无法掌握要求玩家记住比过去四个画面更远的事件的游戏。换句话说,任何需要记忆超过四帧的游戏对于DQN来说都是非马尔可夫的,因为未来的游戏状态(和奖励)不仅仅取决于DQN当前的输入。该游戏代替了马尔可夫决策过程(MDP),而成为部分可观察的马尔可夫决策过程(POMDP)。
现实世界中的任务通常具有不完整且带噪的状态信息,这是由于部分可观察性导致的(如POMDP中发现的)。如图1所示,仅给定一个游戏屏幕,许多Atari 2600游戏就是POMDP。一个例子是Pong游戏,其中当前屏幕仅显示拍和球的位置,而不显示球的速度。知道球的行进方向对于确定最优的拍位置至关重要。
我们观察到,如果给出不完整的状态观察结果,DQN的性能会下降,并假设可以利用RNN的进步来对DQN进行修改以更好地处理POMDP。因此,我们引入了DRQN,它是LSTM (Hochreiter and Schmidhuber 1997)和DQN的组合。至关重要的是,我们证明了DRQN能够处理部分可观察性,并且当评估期间观察质量发生变化时,循环可带来收益。
Deep Q-Learning
强化学习(Sutton and Barto 1998)关注与未知环境交互的智能体的学习控制策略。这种环境通常被形式化为马尔可夫决策过程(MDP),由四元组(S, A, P, R)完整描述。在每个时间步骤 t,与MDP交互的智能体观察状态st ∈ S,并选择一个动作at ∈ A,该动作确定奖励rt ~ R(st, at)和下一个状态st+1 ~ P(st, at)。
Q学习(Watkins and Dayan 1992)估计了从给定状态执行动作的价值。这样的价值估计被称为状态动作价值,或有时简称为Q值。通过将当前的Q值估计更新为观察到的奖励和结果状态s'的估计效用,可以迭代地学习Q值:
![]()
Atari游戏等许多具有挑战性的领域具有太多的独特状态,无法为每个S x A维持单独的估计。取而代之的是使用模型来近似Q值(Mnih et al. 2015)。在深度Q学习的情况下,该模型是一个由权重和偏差参数化(统称为θ)的神经网络。通过在给定状态输入的情况下执行前向传递后,通过查询网络的输出节点来在线估计Q值。这样的Q值表示为Q(s, a|θ)。现在不再更新单个Q值,而是对网络的参数进行更新,以最小化可微损失函数:
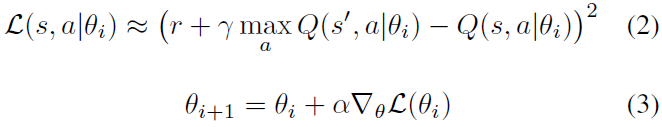
由于![]() ,神经网络模型自然地泛化到其训练过的状态和动作之外。但是,由于同一网络生成下一个状态目标Q值并更新当前的Q值,因此更新可能会对其他Q值估计产生不利影响,从而导致性能振荡甚至出现发散(Tsitsiklis and Roy 1997)。深度Q学习使用三种技术来恢复学习稳定性:首先,将经验et = (st, at, rt, st+1)记录在回放内存D中,然后在训练时进行均匀采样。其次,一个单独的目标网络
,神经网络模型自然地泛化到其训练过的状态和动作之外。但是,由于同一网络生成下一个状态目标Q值并更新当前的Q值,因此更新可能会对其他Q值估计产生不利影响,从而导致性能振荡甚至出现发散(Tsitsiklis and Roy 1997)。深度Q学习使用三种技术来恢复学习稳定性:首先,将经验et = (st, at, rt, st+1)记录在回放内存D中,然后在训练时进行均匀采样。其次,一个单独的目标网络![]() 向主网络提供陈旧更新目标。目标网络用于部分解耦网络生成自己的目标所产生的反馈。
向主网络提供陈旧更新目标。目标网络用于部分解耦网络生成自己的目标所产生的反馈。![]() 与主网络相同,不同之处在于其参数θ-每10000次迭代更新一次以匹配θ。最后,自适应学习率方法(例如RMSProp (Tieleman and Hinton 2012)或ADADELTA (Zeiler 2012))保持每个参数的学习率α,并根据该参数的梯度更新历史调整α。此步骤可弥补缺乏固定训练数据集的不足。D不断变化的性质可能要求某些参数在达到固定值后重新开始更改。
与主网络相同,不同之处在于其参数θ-每10000次迭代更新一次以匹配θ。最后,自适应学习率方法(例如RMSProp (Tieleman and Hinton 2012)或ADADELTA (Zeiler 2012))保持每个参数的学习率α,并根据该参数的梯度更新历史调整α。此步骤可弥补缺乏固定训练数据集的不足。D不断变化的性质可能要求某些参数在达到固定值后重新开始更改。
具体来说,在每次训练迭代 i 时,都会从回放内存D中均匀采样经验et = (st, at, rt, st+1)。按以下方式确定网络的损失:
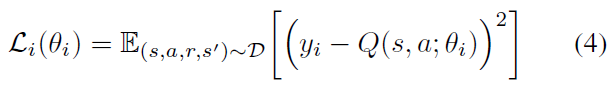
其中![]() 是目标网络
是目标网络![]() 给出的陈旧更新目标。以经验方式表明,以这种方式执行的更新是易处理且稳定的(Mnih et al. 2015)。
给出的陈旧更新目标。以经验方式表明,以这种方式执行的更新是易处理且稳定的(Mnih et al. 2015)。
Partial Observability
在现实环境中,很少能将系统的完整状态提供给智能体甚至确定下来。换句话说,在现实环境中很少拥有马尔可夫性。部分可观察的马尔可夫决策过程(POMDP)通过明确地确认智能体收到的感官仅仅是底层系统状态的部分观察,可以更好地捕获许多现实环境的动态。形式上,POMDP可以描述为6元组(S, A, P, R, Ω, O)。S, A, P, R同以前一样是状态,动作,转换和奖励,只是现在智能体不再具有真实的系统状态,而是收到观察值o ∈ Ω。该观察是根据概率分布o ~ O(s)从底层系统状态生成的。朴素的深度Q学习没有明确的机制来解密POMDP的基础状态,并且仅当观察结果反映了基础系统状态时才有效。在一般情况下,由于![]() ,因此从观察值估计Q值可能会很糟糕。
,因此从观察值估计Q值可能会很糟糕。
我们的实验表明,向深度Q学习添加循环可以使Q网络更好地估计底层系统状态,从而缩小Q(o, a|θ)和Q(s, a|θ)之间的差距。换句话说,循环深度Q网络可以更好地从观测序列中近似实际Q值,从而在部分可观察的环境中产生更好的策略。
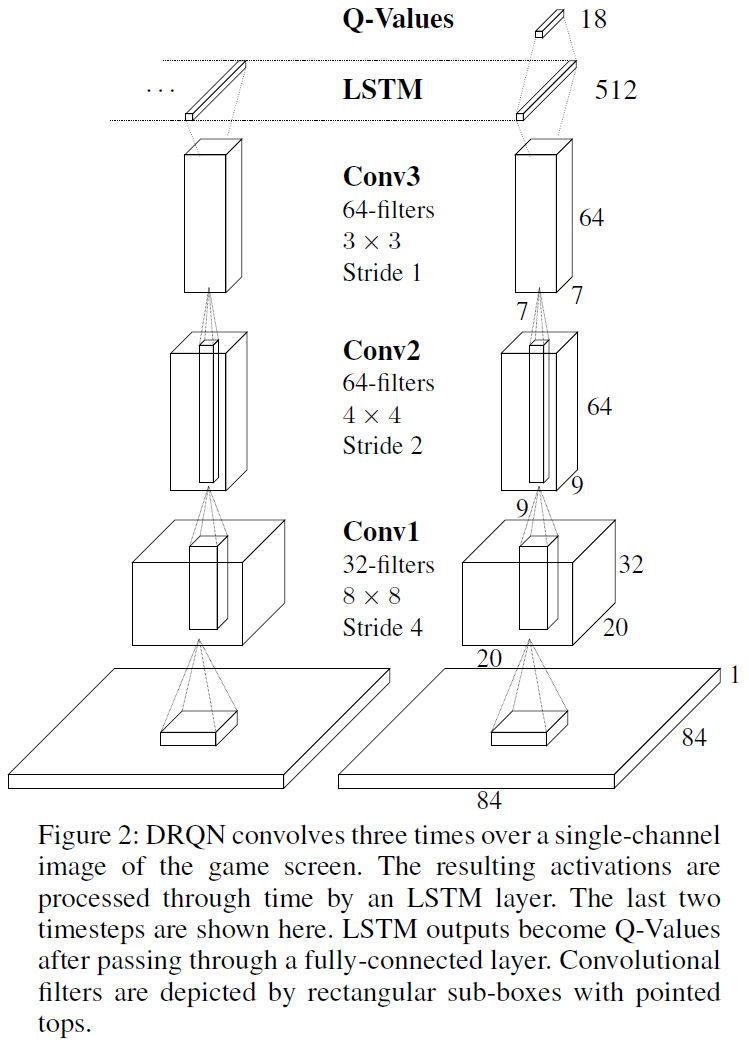
DRQN Architecture
如图2所示,DRQN的结构用LSTM (Hochreiter abd Schmidhuber 1997)代替了DQN的第一个全连接层。对于输入,循环网络将使用单个84 x 84的预处理图像,而不是DQN所需的最后四个图像。第一个隐含层在输入图像上用32个8 x 8滤波器进行卷积(步幅为4),并应用非线性整流器。第二个隐含层使用64个4 x 4滤波器进行卷积(步幅为2),接着还是非线性整流器。第三个隐含层使用64个3 x 3滤波器进行卷积(步幅为1),然后是整流器。卷积输出被馈送到全连接的LSTM层。最后,全连接的线性层为每个可能的动作输出一个Q值。在尝试了几种变体之后,我们决定采用这种架构。有关详细信息,请参见附录A。
Stable Recurrent Updates
更新循环卷积网络需要每次反向传播都包含游戏画面和目标价值的许多时间步骤。此外,LSTM的初始隐含状态可以为零,也可以从其先前的值继续进行。我们考虑两种类型的更新:
Bootstrapped Sequential Updates: 从回放内存中随机选择回合,并且更新从回合的开头开始,一直向前进行直到回合结束。每个时间步骤的目标都是从目标Q网络![]() 生成的。RNN的隐含状态会在回合中延续。
生成的。RNN的隐含状态会在回合中延续。
Bootstrapped Random Updates: 从回放内存中随机选择回合,并且更新从回合中的随机点开始,并且仅针对展开迭代时间步骤(例如,反向调用)进行。每个时间步骤的目标都是从目标Q网络![]() 生成的。RNN的初始状态在更新开始时为零。
生成的。RNN的初始状态在更新开始时为零。
顺序更新的优点是从回合开始就将LSTM的隐含状态保持向前。但是,通过顺序采样整个回合的经验,它们违反了DQN的随机采样策略。
随机更新更好地遵循了随机采样经验的策略,但是因此在每次更新开始时,LSTM的隐含状态必须为零。将隐含状态清零会使LSTM难以学习跨越比时间反向传播达到的时间步骤数更长的时间范围的函数。
实验表明,这两种类型的更新都是可行的,并且可以在一系列游戏中产生相似性能的收敛策略。因此,为了限制复杂度,本文中的所有结果均使用随机更新策略。我们希望所有呈现的结果都能泛化到顺序更新的情况。
在解决了深度循环Q网络的结构和更新之后,我们现在展示其在具有部分可观察性的域上的性能。
Atari Games: MDP or POMDP?
Atari 2600游戏的状态由控制台RAM的128个字节完全描述。但是,人类和智能体只能观察控制台生成的游戏屏幕。对于许多游戏,单个游戏屏幕不足以确定系统状态。DQN通过扩展状态表征以涵盖最后四个游戏屏幕来推断Atari游戏的完整状态。许多以前是POMDP的游戏现在变成了MDP。在(Mnih et al. 2015)调查的49个游戏中,作者无法确定在输入的最后四个帧中部分可观察的游戏。1为了在不减少DQN给出的输入帧数量的情况下将Atari游戏引入部分可观察性,我们将对流行游戏Pong进行特殊修改。
1某些Atari游戏无疑是POMDP,例如Blackjack,在其中隐藏了发牌人的牌。不幸的是,ALE仿真器不支持Blackjack。


Flickering Pong POMDP
我们介绍了Flickering Pong POMDP——对经典游戏Pong的一种改进,这样,在每个时间步骤上,屏幕都被完全显示或完全被遮挡,概率为p = 0.5。以这种方式遮挡帧可能会导致对Pong成为POMDP所需的观察结果的不完整记忆。
为了在Flickering Pong比赛中取得成功,有必要在整合帧间信息以估计相关变量,例如球的位置和速度以及球拍的位置。由于期望中有一半的帧被遮挡,因此成功的玩家必须对几种可能的连续遮挡输入保持鲁棒性。
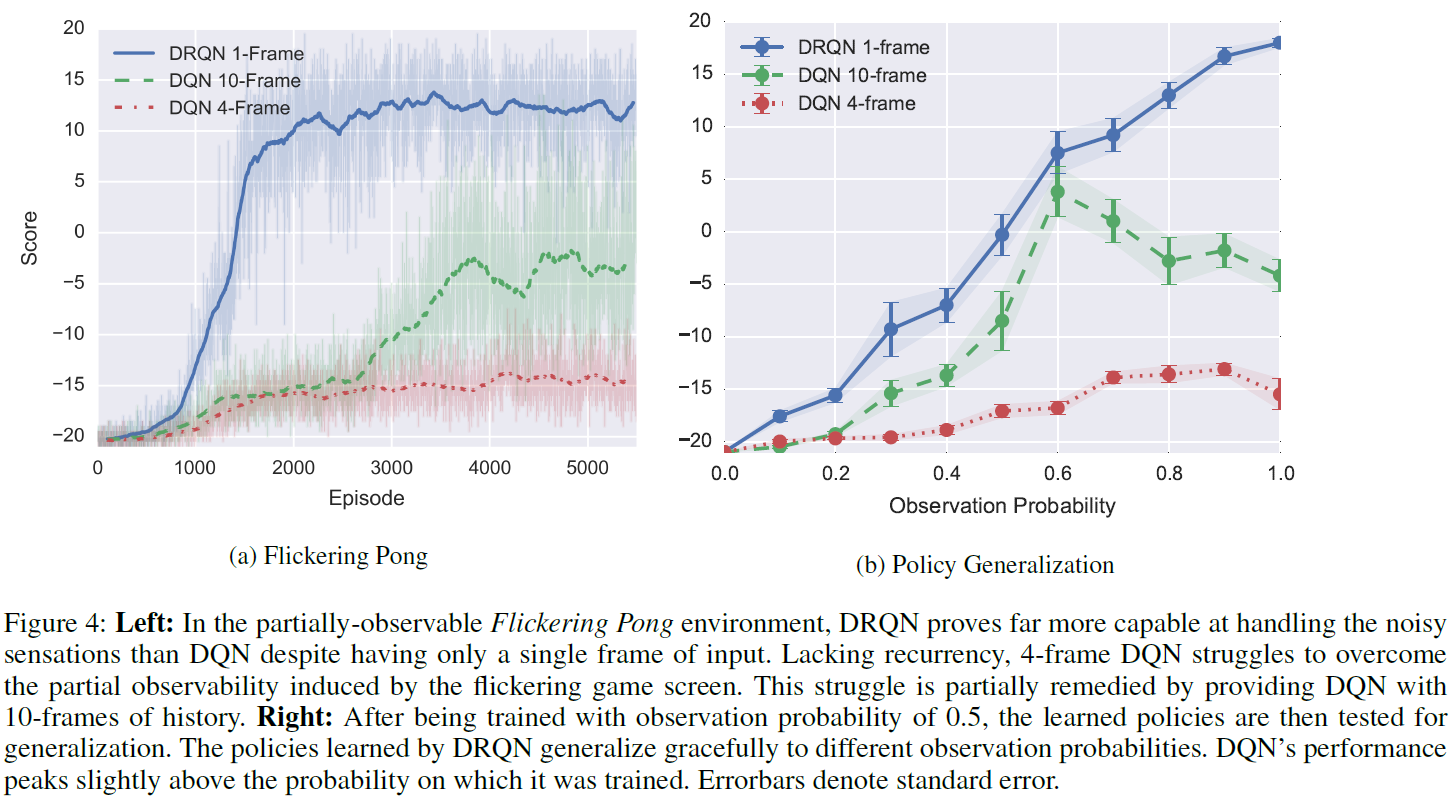
我们训练3种类型的网络来玩Flickering Pong:循环1帧DRQN,标准4帧DQN和增强的10帧DQN。如图4a所示,向DQN提供更多帧可提高性能。尽管如此,即使拥有10帧历史记录,DQN仍难以获得正分数。
游戏屏幕历史记录所提供的最重要的机会可能是卷积检测物体速度的能力。图3以可视化方式显示了游戏屏幕,从而最大程度地激活了不同的卷积滤波器,并确认了10帧DQN的滤波器确实能够检测到物体的速度,尽管它的可靠性可能不及普通的未遮挡Pong。2
值得注意的是,即使每个时间步骤仅给出一个输入帧,DRQN仍能很好地完成此任务。DRQN的卷积层无法检测到任何类型的速度。取而代之的是,较高级别的循环层必须同时补偿闪烁的游戏画面和缺少卷积速度检测。即便如此,DRQN经常得分超过10分(最高21分)。图3d确认LSTM层中的各个单元能够通过时间整合带噪的单帧信息,以检测高水平的Pong事件,例如玩家错过了球,在拍上反射的球或从墙壁反射的球。
在最近十个时间步骤中,使用反向传播对DRQN进行了训练。因此,非循环10帧DQN和循环1帧DRQN都可以访问相同的游戏屏幕历史记录。3DRQN更好地利用了有限的历史记录来获得更高的分数。
因此,在处理部分可观察性时,可以选择使用具有长观察历史的非循环深度网络,还是使用在每个时间步骤经过单个观察值训练的循环网络。Flickering Pong提供了一个示例,其中即使被授予访问与非循环网络相同数量的过去观察值的能力,循环深度网络的性能也会更好。在十个游戏中进一步比较了DRQN和DQN的性能(表2),其中两种算法都没有观察到系统性优势。
2 (Guo et al. 2014)还证实了卷积滤波器学会了对游戏目标中看到的运动模式做出响应。
3 然而,(Karpathy, Johnson, and Li, 2015)表明,LSTM可以在训练时以有限的时间步骤集学习函数,然后在测试时将其泛化为更长的序列。
Generalization Performance
为了分析Flickering Pong玩家的泛化性能,我们评估了DRQN,10帧DQN和4帧DQN的最优策略,同时改变了遮挡屏幕的可能性。请注意,这些策略都在p = 0.5的Flickering Pong上进行了训练,现在针对不同的p值进行了评估。图4b显示,随着观察帧的可能性增加,DRQN性能继续提高。相比之下,10帧DQN的性能在训练后的观察概率附近达到峰值,甚至在观察到更多帧时也会下降。因此,DRQN学习了一种允许性能随观察质量而扩展的策略。这样的属性对于观察质量随时间变化的领域非常有价值。
Can DRQN Mimic an Unobscured Pong player?
为了更好地理解让DRQN在Flickering Pong环境中正常运行的机制,我们分析了在p = 0.5和p = 1.0的相同Pong轨迹下,经过闪烁训练的DRQN之间的差异,假设如果flickering-Pong智能体可以推断出被遮挡的屏幕中潜在的游戏状态,则其激活应反映未遮挡的智能体(p = 1.0)的激活。我们使用归一化的欧氏距离作为度量来量化两个激活向量u, v之间的差异:
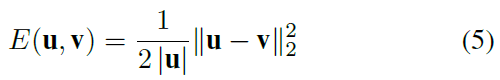
让我们将DRQN的LSTM层在Flickering Pong游戏时间步骤 t 的激活向量表示为![]() 。当禁用闪烁并显示完整状态时,我们将激活表示为
。当禁用闪烁并显示完整状态时,我们将激活表示为![]() 。我们允许Flickering Pong玩家玩10场比赛,并记录LSTM层的值
。我们允许Flickering Pong玩家玩10场比赛,并记录LSTM层的值![]() 。接下来,我们在相同的10个游戏轨迹上评估相同的网络,但所有帧都显示为
。接下来,我们在相同的10个游戏轨迹上评估相同的网络,但所有帧都显示为![]() 。如果即使在不观察屏幕的情况下,LSTM仍能够推断游戏状态,则可以预期在屏幕被遮挡的所有 t 中,
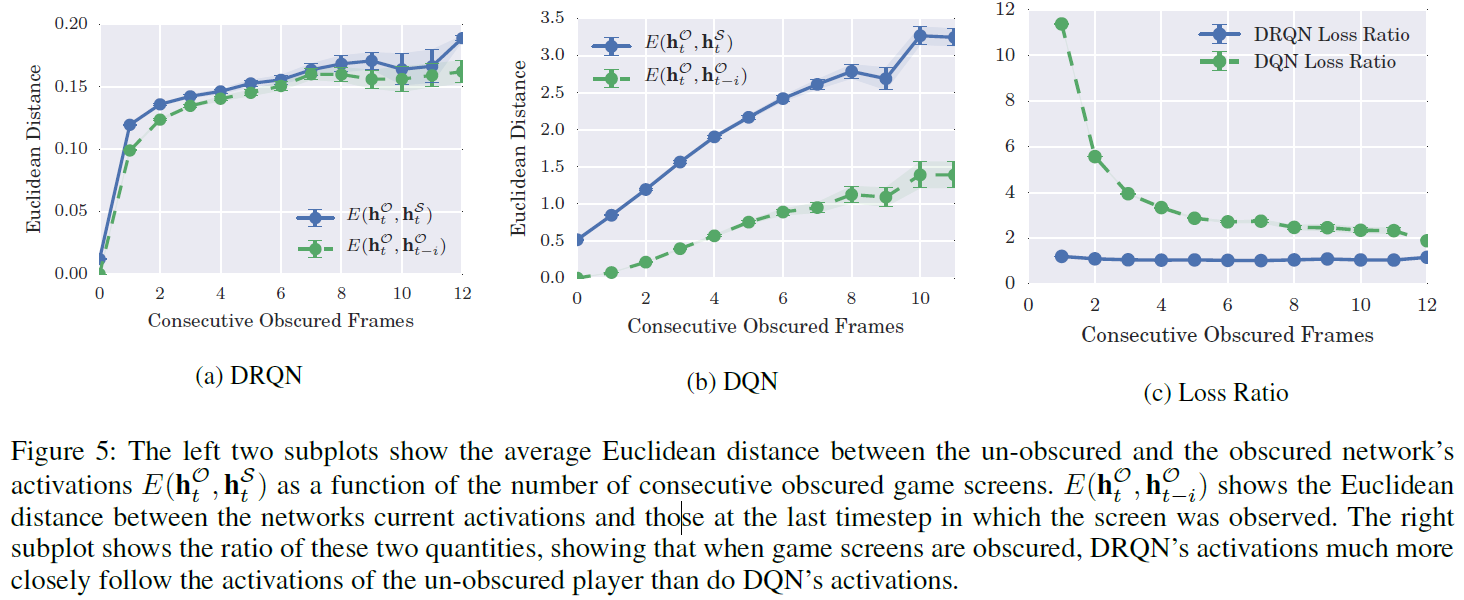
。如果即使在不观察屏幕的情况下,LSTM仍能够推断游戏状态,则可以预期在屏幕被遮挡的所有 t 中,![]() 之间的平均欧氏距离都较低。图5a-5b将该数量绘制为DRQN和10帧DQN连续遮挡帧数的函数。4与DQN相比,DRQN在玩Flickering Pong游戏和未遮挡的Pong游戏时其激活之间的平均距离小得多。此外,即使存在噪声,DRQN的激活也会平稳变化。
之间的平均欧氏距离都较低。图5a-5b将该数量绘制为DRQN和10帧DQN连续遮挡帧数的函数。4与DQN相比,DRQN在玩Flickering Pong游戏和未遮挡的Pong游戏时其激活之间的平均距离小得多。此外,即使存在噪声,DRQN的激活也会平稳变化。
但是,仅比较欧氏距离并不能说明全部问题,因为10帧DQN可能比DRQN具有更大的预期帧间激活变化。为了对此进行控制,图5a-5b还绘制了自最后观察到的帧![]() 以来激活的总体变化。该度量可以大致了解激活的整个时间步长变化。
以来激活的总体变化。该度量可以大致了解激活的整个时间步长变化。
最后,当屏幕被遮挡时,可以预期网络的激活将发生变化。令人感兴趣的是,它们是否在与未遮挡的网络激活相同的方向上变化。令Ai表示轨迹中最后 i 帧已被遮挡的所有时间步骤的集合。然后,我们检查的平均ratio为遮挡激活和未遮挡激活之间的距离除以当前时间步骤和最近一个时间步骤观察到游戏屏幕之间遮挡激活的距离:
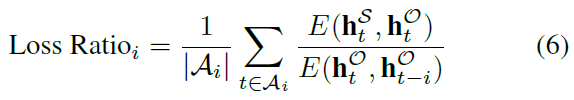
较低的Loss Ratio值表示被遮挡的网络激活不仅发生变化,而且在与未遮挡的网络相同的方向上发生变化(例如,被遮挡的玩家可以在不看屏幕的情况下推断游戏状态的程度)。如图5c所示,在连续遮挡帧的所有值上,DRQN的loss ratio比DQN低,这表明它更好地模仿了未遮挡的网络激活。由于Flickering Pong每次屏幕被遮挡时都会真正丢弃信息,因此可以合理地预期被遮挡的玩家和未遮挡的玩家的激活之间会有一定距离。的确,DRQN的屏幕遮挡激活与未遮挡激活以及最后观察到的屏幕激活大致相等,这意味着在遇到屏幕遮挡后,DRQN无法完全推断隐含游戏状态。但是,它也没有完全保留其过去的激活。
4 由于10帧DQN没有LSTM层,因此在第一个卷积层后全连接层的激活上计算欧氏距离。该层与DRQN的LSTM层一样,具有512个单位。
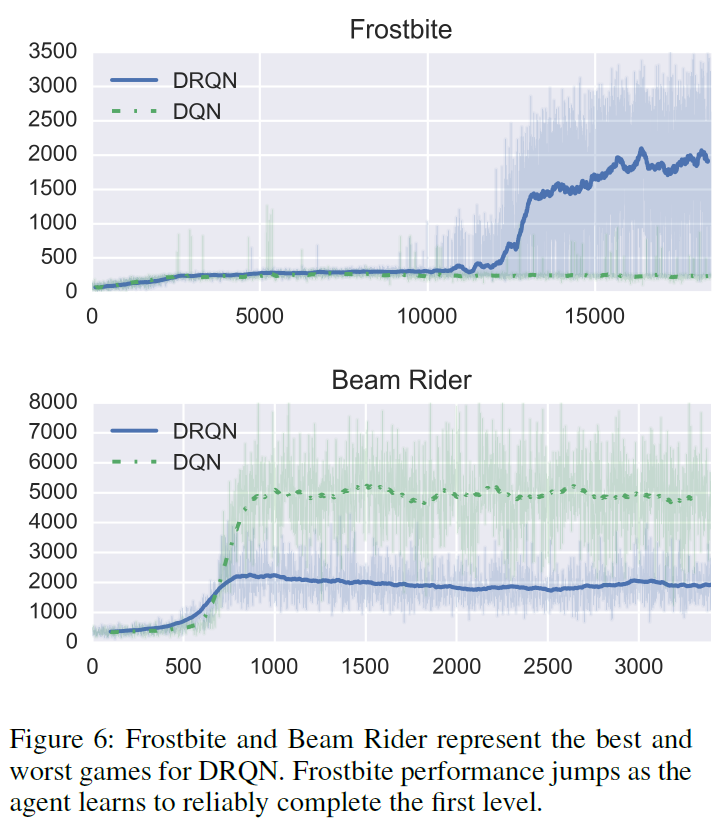
Evaluation on Standard Atari Games
我们选择了以下9种Atari游戏进行评估:Asteroids和Double Dunk具有自然闪烁的精灵,使其成为潜在的循环学习候选。Beam Rider,Centipede和Chopper Command是射击。Frostbite是类似于Frogger的平台游戏。Ice Hockey和Double Dunk是体育比赛,需要定位球员,传球和发射冰球/球,并要求球员具备进攻和防守的能力。Bowling需要在特定时间采取动作才能引导球。Ms Pacman身上有闪烁的幽灵和强力药丸。
给定最后四个输入帧,所有这些游戏都是MDP,而不是POMDP。因此,没有理由期望DRQN胜过DQN。实际上,表1中的结果表明,DRQN的平均表现与DQN大致相当。具体来说,我们对DQN的重现与原始版本的表现类似,在九个游戏中有五个表现优于原始版本,但在Centipede和Chopper Command中得分不到原始得分的一半。DRQN在Frostbite和Double Dunk的游戏中的表现胜过DQN,但在Beam Rider游戏中表现却差很多(图6)。Frostbite游戏(图1b)要求玩家跳越所有四排移动的冰山并返回屏幕顶部。经过几次冰山之后,已经收集了足够的冰以在屏幕的右上方建造冰屋。随后,玩家可以进入冰屋以前进到下一个级别。如图6所示,在12000个回合之后,DRQN发现了一个策略,该策略可以使其可靠地越过第一级Frostbite。有关实验的详细信息,请参见附录C。
5 使用Benjamini-Hochberg程序由独立t-检验确定的得分的统计显著性,显著性水平P = .05。
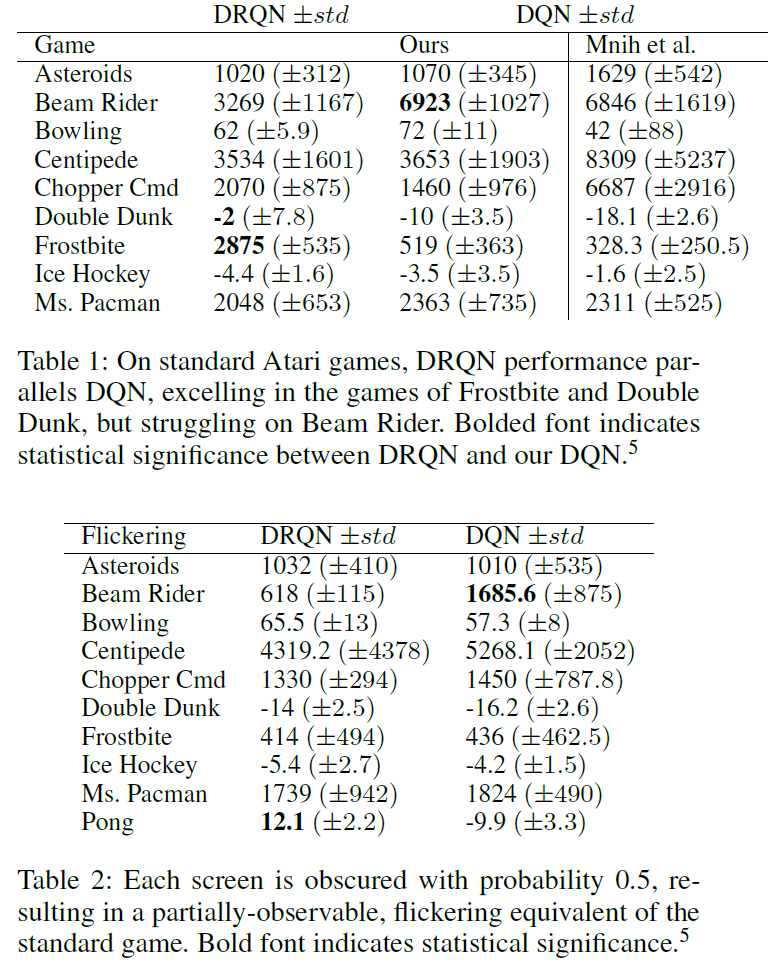
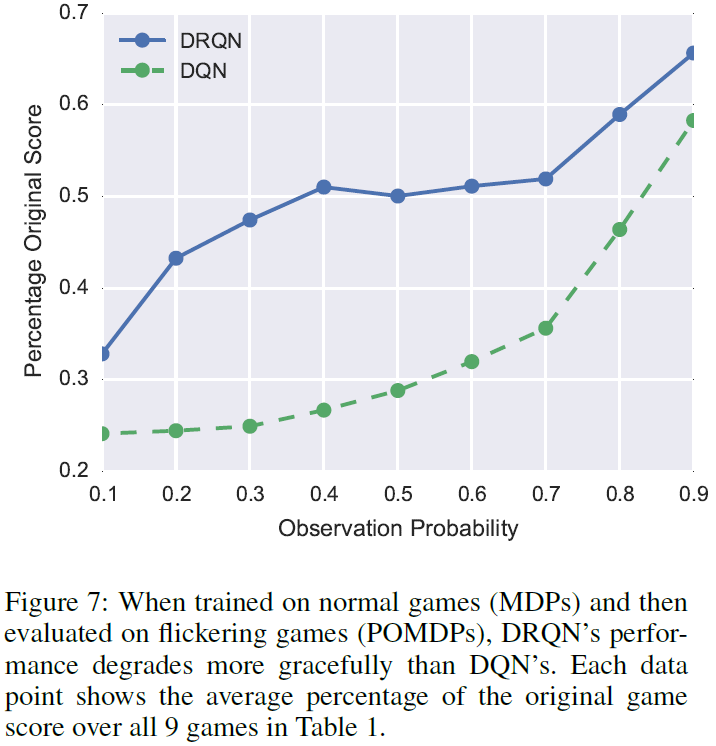
MDP to POMDP Generalization
图4b显示,当在POMDP上训练然后在MDP上进行评估时,DRQN性能会提高。可以说,更有趣的问题是相反的问题:可以在标准MDP上训练循环网络,然后在评估时将其泛化到POMDP吗?为了解决此问题,我们在表1中所有9个游戏的闪烁等效上评估了DRQN和DQN的最高得分策略。图7显示,尽管这两种算法由于缺少信息而导致性能显著下降,但在所有级别的闪烁中,DRQN都比DQN捕获更多的先前性能。我们得出的结论是,循环控制器对丢失的信息具有一定程度的鲁棒性,即使用完整的状态信息进行训练也具有一定的鲁棒性。
Related Work
先前已经证明,使用策略梯度方法训练LSTM网络可以解决POMDP (Wierstra et al. 2007)。与策略梯度相反,我们的工作使用时序差分更新来自举动作-价值函数。此外,通过联合训练卷积层和LSTM层,我们可以直接从像素中学习,并且不需要手工设计的特征。
LSTM已被用作优势函数近似,并且显示出比可比较的(非LSTM)RNN更好地解决了部分可观察的corridor和cartpole任务(Bakker 2001)。尽管原理上相似,但corridor和cartpole任务的特征是只有几个特征的微小状态空间。
与我们的工作并行(Narasimhan, Kulkarni, and Barzilay 2015),将LSTM与深度RL独立进行了结合,以证明循环有助于更好地玩基于文本的幻想游戏。这种方法是相似的,但领域有所不同:尽管幻想生成的文本看起来很复杂,但是底层的MDP却具有底层状态空间相对较低维的流形。两种游戏中比较复杂的只有56个基础状态。相反,Atari游戏具有更丰富的状态空间,典型的游戏具有数百万个不同的状态。但是,文字游戏的动作空间更大,分支因子为222,而Atari的分支因子为18。
Discussion and Conclusion
现实世界中的任务通常由于部分可观察性而具有不完整且带噪的状态信息。我们将DQN修改为通过将LSTM与DQN相结合来处理POMDP的带噪观测特征。尽管在每个步骤中仅看到单个帧,但生成的DRQN仍能够跨帧集成信息以检测相关信息,例如屏幕上物体的速度。此外,在Pong的游戏中,DRQN比标准的DQN更好,可以处理由闪烁的游戏屏幕引起的部分可观察性。
进一步的分析表明,DRQN在接受部分观测值训练后,可以将其策略泛化到完整观测值的情况。在Flickering Pong域中,性能随域的可观察性而缩放,当观察每个游戏屏幕时,性能均达到接近完美的水平。此结果表明,循环网络学习的策略既足够鲁棒以应对丢失的游戏屏幕,又具有足够的可伸缩性以随着更多数据可用而提高性能。泛化也发生在相反的方向:在标准Atari游戏中接受训练并针对闪烁的游戏进行评估时,DRQN的性能在所有局部信息水平上都比DQN更好。
我们的实验表明,Pong代表了所检查游戏中的异常值。在一组十个闪烁的MDP中,我们发现采用循环时没有系统的改进。类似地,在非闪烁的Atari游戏中,循环和非循环玩家之间几乎没有显著差异。该观察结果使我们得出结论,尽管循环是处理多状态观察结果的可行方法,但与将观察结果堆叠到卷积网络的输入层相比,它没有任何系统性的好处。未来的一个有趣途径是确定Pong和Frostbite域的相关特征,这些特征可以通过循环网络获得更好的性能。
Appendix A: Alternative Architectures
在Beam Rider的游戏中评估了几种替代架构。我们探讨了用LSTM层替换第一个非卷积全连接层(LSTM替换IP1)或在第一个和第二个全连接层之间添加LSTM层(IP1之上的LSTM)的可能性。结果强烈表明LSTM应该代替IP1。我们假设这允许LSTM直接访问卷积特征。此外,在LSTM层之后添加整流器层会持续降低性能。

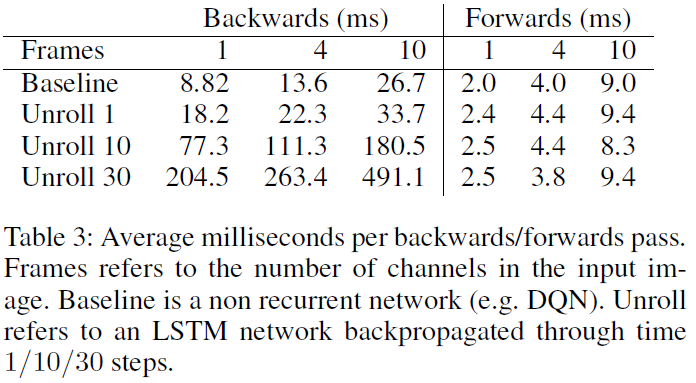
Appendix B: Computational Efficiency
RNN的计算效率是一个重要的问题。我们进行了1000次前向和后向遍历,并报告了每次遍历所需的平均时间(以毫秒为单位),从而进行了实验。实验使用了单个使用CuDNN的Nvidia GTX Titan Black和完全优化的Caffe版本。结果表明,在输入层中堆叠的帧数和展开的迭代数中,计算均亚线性缩放。即便如此,在大量堆叠帧上训练并展开许多迭代的模型通常在计算上很棘手。例如,一个具有10个堆叠帧的展开30次迭代的模型将需要超过56天才能达到1000万次迭代。
Appendix C: Experimental Details
通过玩10个回合并取平均分数,每50000次迭代对策略进行评估。对网络进行了1000万次迭代训练,并使用了大小为40万的回放内存。此外,所有网络都使用ADADELTA (Zeiler 2012)优化器,学习率为0.1,动量为0.95。LSTM的梯度被裁剪为10,以确保学习的稳定性。所有其他设置与(Mnih et al. 2015)中给出的设置相同。
所有网络均使用Arcade学习环境ALE (Bellemare et al. 2013)进行训练。使用了以下ALE选项:颜色平均,最小动作集和死亡检测。
DRQN在Caffe中实现(Jia et al. 2014)。来源可从https://github.com/mhauskn/dqn/tree/recurrent获得。