郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ICLR 2020
ABSTRACT
本文介绍了Meta-Q-Learning (MQL),这是一种用于元强化学习(meta-RL)的新的异策算法。MQL基于三个简单的想法。首先,我们表明,如果可以访问表示过去轨迹的上下文变量,则Q学习将与最新的元RL算法相当。其次,在训练任务中最大化多任务目标的平均奖励是对RL策略进行元训练的有效方法。第三,元训练经验缓存中的过去数据可以被回收,以使策略适用于新任务。MQL借鉴了倾向估计中的想法,从而扩大了用于适应的可用数据量。在标准连续控制基准上进行的实验表明,MQL与元RL中的最新技术相比具有优势。
1 INTRODUCTION
强化学习(RL)算法在模拟数据上表现出良好的性能。然而,将这种性能赋予真实机器人面临两个主要挑战:(1) 机器人的复杂性和脆弱性阻碍了广泛的数据收集;(2) 机器人面临的真实环境可能不同于它被训练的模拟环境。这推动了元RL的研究,在大量不同环境(如模拟环境)中开发"元训练"算法,旨在用少量数据来适应新环境。
如今元RL的研究情况如何?图1显示了两种典型的元RL算法在4个标准连续控制基准测试中的性能。1我们将它们与下列简单基准进行了比较:一个异策RL算法(TD3, Fujimoto et al. (2018b)),并对其进行了训练,以使所有训练任务的平均奖励最大化,并对其进行了修改,以使用代表轨迹的"上下文变量"。此图中的所有算法都使用相同的评估协议。令人惊讶的是,这种简单的基于非元学习的方法与最新的元RL算法相比具有竞争优势。这是论文的第一个贡献:证明没有必要为了在现有的基准测试中表现良好而使用元训练策略。
第二个贡献是建立在上述结果基础上,提出一种称为"元Q学习"(MQL)的异策元RL算法。MQL使用简单的元训练过程:经过异策更新,最大化所有元训练任务的平均奖励以获得:
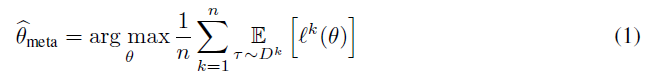
其中 是对从任务
获得的转换
进行评估的目标。例如,单步TD误差将设置为
。这个目标被称为多任务目标,是最简单的元训练形式。
为了使策略适应新任务,MQL从元训练回放缓存中采样与新任务中类似的转换。这会扩充可用于自适应的数据量,但由于较大的潜在偏差,很难做到这一点。使用倾向性估计文献中的技术来执行此适应,而MQL的异策更新对执行此适应至关重要。MQL的自适应阶段解决:
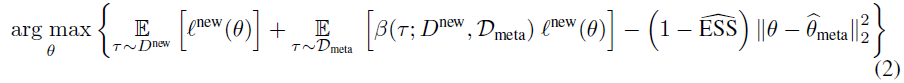
2 BACKGROUND
2.1 META-REINFORCEMENT LEARNING (META-RL)
2.2 LOGISTIC REGRESSION FOR ESTIMATING THE PROPENSITY SCORE
3 MQL
3.1 META-TRAINING
3.1.1 DESIGNING CONTEXT
3.2 ADAPTATION TO A NEW TASK
4 EXPERIMENTS
4.1 SETUP
4.2 RESULTS
4.3 ABLATION EXPERIMENTS
4.4 RELATED WORK
5 DISCUSSION
A PSEUDO-CODE
B OUT-OF-DISTRIBUTION TASKS
C MORE ABLATION STUDIES
D HYPER-PARAMETERS AND MORE DETAILS OF THE EMPIRICAL RESULTS