郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

This Article is brought to you for free and open access by the Computer Science at ScholarWorks@UMass Amherst. It has been accepted for inclusion in Computer Science Department Faculty Publication Series by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact scholarworks@library.umass.edu.
人工智能是最活跃的研究领域之一,是学习方法的研究,通过这些方法,“嵌入式智能体”可以在复杂的动态环境中工作时提高性能。当智能体或决策者在正在进行的闭环交互中从该环境接收信息并对该环境采取行动时,便嵌入该环境中。嵌入式智能体必须在时间压力和不确定性下做出决策,并且必须在没有永远存在的知识渊博的老师的帮助下进行学习。对于生物学家而言,动物可能是不起眼的动物,而动物是原型的嵌入式智能体,这种强调与传统意义上的AI相比,明显偏离了实际事件流中所限定范围内的推断。与更广泛研究的监督学习不同,嵌入式智能体视图的人们对被称为强化学习(RL)的学习范式越来越感兴趣。通过从一组正确的输入/输出行为示例中学习的RL系统,RL系统会调整其行为,以最大化其随时间推移遇到的强化事件的频率和/或大小。
尽管现代RL的核心思想来自动物经典和工具性条件反射理论(尽管心理学家未使用“强化学习”这个特定术语),但AI和控制理论对概念的影响产生了一系列具有强大计算能力的学习架构。尽管这些架构中的一些与某些大脑区域的结构和功能之间存在相似之处,但是却很少有人提出将这些架构与神经系统相关联的方法(但请参见Houk 1992, Klopf 1982, Wickens 1990 and Werbos 1987),在本文中,我描述了称为执行者-评论者结构的RL系统,并提供了足够的细节,使其可以与基底神经节回路和多巴胺神经元相关。这种结构称为自适应评论者,其行为似乎与投射到大脑皮层和额叶皮层的多巴胺神经元的行为非常相似(Schultz, this workshop)。Houk, Adams and Barto(1994)在本卷中的一篇配套文章中提出了一个假设,即关于执行者-评论者结构如何通过基底神经节和相关的脑部结构来实现的假设。我对自适应评论者的解释很大程度上遵循Sutton(1984, 1988)的观点。
自适应评论者是一种设备,可以学习预测强化事件的方式,使其与另一个组件(执行者)有用地结合,后者可以调整行为以最大化强化事件的频率和/或大小。自适应评论者还形成了经典或巴甫洛夫式条件反射的时序差分模型的基础(Sutton and Barto 1987, 1990),该模型扩展了Rescorla-Wagner模型(Rescoral and Wagner 1975),以考虑到一些精密的时序结构条件反射。自适应评论者使用的学习规则归功于萨顿(Sutton),他正在将其发展为博士学位论文(Sutton 1984)的一部分,应用于Barto, Sutton and Anderson(1983)的杆平衡系统。Sutton(1988)进一步开发了这类学习算法,称它们为时序差分(TD)方法。
这一系列的研究工作始于对Klopf(1972, 1982)的广义强化思想的探索,该思想强调了在神经元学习模型中顺序性的重要性。但是,较早的先驱是Samuel(1959)在他的跳棋学习程序中使用的技术。当前关于自适应评论者的研究集中在其与用于解决控制问题的称为动态编程的优化技术的关系。这种联系是根据Werbos(1977, 1987)和Watkins(1989)的研究得出的。Barto, Sutton and Watkins(1990)以及Barto, Bradtke and Singh(1994)详细介绍了这种观点。Tesauro(1992)的西洋双陆棋游戏程序很好地证明了执行者-评论者结构的能力,该程序使用了执行者-评论者结构来学习如何玩世界级的西洋双陆棋。
Reinforcement Learning
遵循Thorndike的“效率定律”(Thorndike 1911)的基本思想,最简单的RL算法基于常识性思想,即,如果在某个动作之后跟随着令人满意的事务状态,或者事务状态的改进,那么采取动作的趋势就会增强,即强化。尽管这通常被称为“试错”学习,但我更喜欢将其称为基于“生成并测试”过程的学习:生成替代方案,并通过测试对它们进行评估,然后将行为导向更好的替代方案,我之所以喜欢,是因为容易将试错学习与监督学习相混淆。
例如,使用众所周知的误差反向传播监督学习方法训练的ANN(例如Rumelhart, Hinton and Williams 1986)产生输出,接收误差矢量,并调整网络的权重以减小误差幅度。这是一种试错学习法,但与Thorndike所考虑的学习方法有所不同。监督学习中的误差向量源自正确性标准:监督学习的“目标”响应。相反,RL强调依赖于响应的反馈,该反馈通过不一定能访问正确性标准的过程来评估学习者的性能。评估反馈告诉学习者其行为是否有所改进,并且有可能改进了多少,或者它提供了行为“优良”的度量,或者只是指示成功或失败。评估反馈并不能直接告诉学习者应该做的事情,尽管有时它是误差向量的大小,但它不包括指导学习者如何改变其行为的定向信息,监督学习的误差向量也没有。尽管评估反馈通常被称为强化反馈,但它不一定涉及愉悦或痛苦。
RL系统不是试图匹配正确性标准,而是试图最大化评估反馈所指示的行为的优劣。1为此,系统必须探究环境的某种形式以获得有关如何更改其行为的信息。它必须积极尝试替代方案,比较得出评估结果,并使用某种选择机制来引导行为转向更好的替代品。我在其他地方更详细地讨论了强化学习和监督学习之间的区别(Barto 1991, 1992)。
要实际构建RL系统,必须更加精确地了解学习目标。评价反馈评价什么?如果学习系统的生命只包括一系列离散试验,每个试验都包含一个离散动作,然后对该动作(只有该动作)进行评估,那么情况就很简单了。但是,动作可能会延迟以及立即产生后果,并且评估反馈通常会评估系统过去所有行为的后果。RL系统如何处理复杂的动作缠结及其在整个时间中发生的后果?这被称为时序责任分配问题。自适应评论者的概念是解决此问题的一种方法:评论者学会根据未来强化的预测提供有用的即时评估反馈。按照这种方法,RL不仅是根据给定的评估反馈来改进行为的过程,它还包括学习以提高评估反馈。
1与稳态相比,Klopf(1972, 1982)的异态理论强调了寻求匹配和寻求最大化之差的意义。
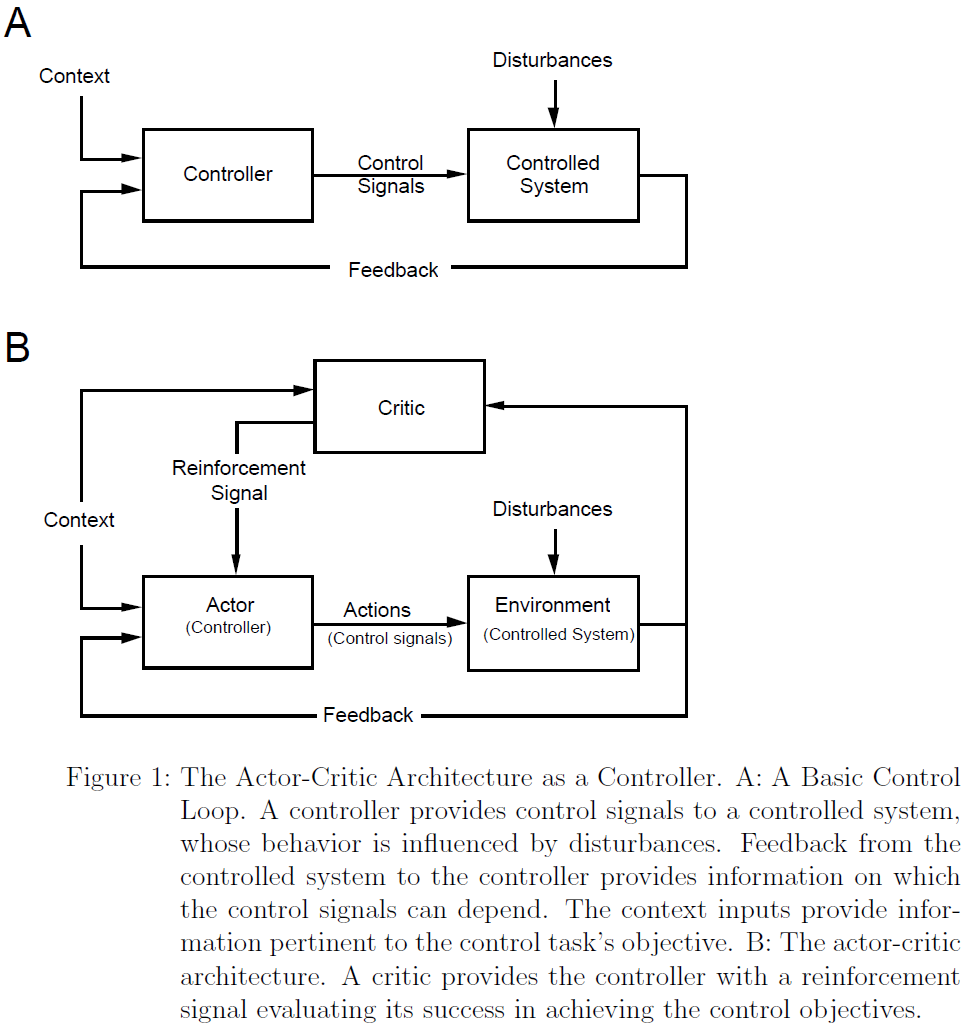
The Actor-Critic Architecture
通常在控制理论的框架内来观察执行者-评论者结构。图1A是经典控制系统框图的变形。控制器将控制信号提供给受控系统。受控系统的行为受到干扰的影响,并且从受控系统到控制器的反馈提供了控制信号所依赖的信息。标签为“上下文”的控制器输入可提供有关控制任务目标的信息。你可能会认为上下文信号指定了“动机状态”,暗示了某些控制目标。
图1B将图1A的框图扩展到了执行者-评论者结构。添加了另一个反馈循环,用于向控制器(现在称为智能体)提供评估反馈。评论者通过观察执行者的行为对受控系统(现在称为环境)的行为产生的后果来产生评估反馈或强化反馈。评论者还需要知道任务的动机背景,因为根据执行者应该尝试执行的操作来对其进行不同的评估。评论者是对过程的抽象,该过程向负责调节执行者行为的学习机制提供评估反馈。在大多数人工RL系统中,评论者在任何时候的输出都是对执行者的前一个动作评分的数字:数字越大,动作越好。
执行者-评论者结构是一种抽象的学习系统,必须小心将其与动物及其神经系统联系起来。 它可以帮助我们思考动物强化学习,但是如果从字面上看也太过误解。特别是,将执行者与动物以及环境与动物的环境相区别是一种欺骗。最好将执行者-评论者结构视为动物的任何强化学习组件或子系统的模型。可能有很多这样的子系统,只有其中一些直接控制动物的明显运动行为。
图2阐述了执行者-评论者结构,强调了这一点。可以将图中的阴影框视为动物。执行者与整个动物并不相同,其行为不一定是运动命令。此外,评论者(也许是其中的许多评论者)在动物里面。我已将图1的环境框分为内部和外部环境,以强调评论者根据执行者的内部和外部后果来评估其行为。内部环境可以包含其他行为准则结构,其中某些确实会产生明显的外部行为。Houk, Adams and Barto(1994)在提出执行者-评论者结构与基底神经节之间的关系时,提出了相关执行者的动作是影响额叶皮层的信号。额叶皮层和小脑都是该执行者内部环境的组成部分。
图3更详细地显示了评论者。它由一个固定且自适应的评论者组成。我们认为固定评论者是在每个时刻 t 给评论者所收到的感觉输入(内部和外部)分配一个数值的主要强化价值rt; rt总结了该输入的主要强化效果的强度,即通过进化过程而不是通过经验学习获得的强化效果。尽管在动物中,这种强化效应取决于动机状态,但我们通过假设固定的动机状态来简化事物(因此,图3并未显示评论者的上下文输入)。自适应评论者通过自适应过程将不同的强化价值分配给感觉输入。评论者在 t 时刻的输出是发送给执行者的有效强化信号。我们将其标记为![]() 。
。
Imminence Weighting
执行者-评论者结构的基本目标是学习动作以产生感官输入,为此,主要强化价值将最大化。但是由于行为会随着时间的流逝而持续,随着时间的推移会产生感觉输入,因此学习系统必须最大化其输入的整个时间过程的某种度量。该措施必须考虑到以下事实:动作可能对强化产生长期和短期的影响,有时最好放弃短期奖励,以便以后获得更多奖励。大部分RL研究人员都采用了基于最优控制理论的措施。尽管数学简单是它的主要优点,但这种方法在动物学习中具有一定的合理性,如经典条件的TD模型所证明的那样(Sutton and Barto 1987, 1990)。根据该措施,学习的目标是在每个时刻采取动作,以使所有将来的主要强化价值的加权总和最大化。立即主要强化的权重比稍微延迟的主要强化更大是合理的,后者权重应比长时延强化更大。Sutton and Barto(1990)称这种迫近度加权,并建议自适应评论者试图预测未来主要强化的迫近度加权总和。
图4(来自Sutton and Barto, 1990)说明了针对图A中所示的一次强化的特定时间过程的迫近加权的概念。人们可以将其视为一系列无条件刺激(因此其标记为US / λ,其中λ是我们不在此讨论的归一化因子)。图4B展示出了特定的迫近权重函数,其指定了相对于特定时间 t,赋予主要强化的权重如何随延迟而下降。图4C展示出了如何通过在时间 t 处施加的迫近加权函数来变换主要强化信号,以减小延迟的主要强化的权重。自适应评论者试图在时间 t 预测的数量是该曲线下的面积。为了获得其他时间的正确预测,该加权函数沿时间轴滑动至其基准在相关时间开始,根据新位置对主要强化信号进行加权,并计算出新面积。图4D和4E显示了另一个时间t'的示例。通过每次重复此过程,可以得到图4F所示的正确预测序列。如果自适应评论者正确地预测了图4A的主要强化信号的未来主要强化的迫近加权总和,则其预测应类似于图4F。
解释如何预测未来主要强化的迫近加权总和的最简单方法是采用学习过程的离散时间模型。因此,假设 t 仅取整数0, 1, 2, ...,并将从任何时间步骤 t 到t + 1的时间间隔都视为一小段实数时间。再次为简单起见,我做出了另一个假设,即至少需要一个时间步骤才能采取动作来影响主要强化。这是环境和评论者的基本延迟。因此,在时间 t 采取的动作,即时主要强化为rt+1,而对于即时有效的强化,我指的是![]() 。当然,这种最小延迟对于神经系统中的不同执行者-评论者系统可能是不同的。
。当然,这种最小延迟对于神经系统中的不同执行者-评论者系统可能是不同的。
使用迫近权重的离散时间版本,执行者的目标是学习在每个时间步骤 t 上执行动作,以使时间步骤t +1和所有未来时间的主要强化价值的加权总和最大化。权重随主要强化价值的减小而减小:
![]()
使用α1 > α2 > α3 > ...。通常,这些权重是根据折扣因子γ定义的,其中0 < γ < 1,如下所示:
![]()
其中i = 1, 2, ...。则等式1的迫近加权和为:
![]()
折扣因子决定了未来的一次强化应该对当前动作产生多大的影响。当γ = 0时,迫近加权总和就是直接的一次强化rt+1(因为00 = 1)。在这种情况下,所需的动作仅使即时主要强化最大化。随着γ趋向于1,未来的主要强化变得更加重要。在这里,我们认为γ被固定为接近1,因此动作的长期后果很重要,自适应评论者在学习中起着至关重要的作用。
如果仅通过即时主要强化来强化动作,则学习将仅取决于动作的短期后果。这种学习目标被称为战术目标(Werbos 1987),忽略了动作的长期后果。由于通常完全缺乏即时主要强化(在没有主要强化的情况下,通过使rt = 0形式化),因此纯粹的战术学习系统无法学习如何操纵其环境来实现未来的主要强化。甚至更糟的是,仅采取动作立即获得主要强化可能会干扰甚至阻止将来获得更好的主要强化。另一方面,战略目标(Werbos, 1987)考虑了长期和短期后果。
如何处理不同时间的后果之间的权衡取决于一个人如何定义战略目标,而通过折扣因子的迫近权重是一个定义。通过折扣,延迟一个时间步骤的任何数量的主要强化价值都等于相同数量的未延迟主要强化的分数(γ)。随着γ趋向于1,延迟带来的差异越来越小,学习的目标也变得更具战略意义。
自适应评论者的想法是应该学习如何提供有效的强化信号,以便当执行者根据最大化即时有效强化的战术目标学习时,实际上是在根据最大化长期的行为度量的战略目标进行学习。在这里,长期措施是未来主要强化的迫近加权总和。为了做到这一点,自适应评论者必须预测未来主要强化的迫近加权总和,这些预测对于形成有效强化至关重要,如下所述。由于有效强化结合了这些预测,因此执行者仅需针对有效强化信号执行战术学习:它经过调整,因此时刻 t 的动作始终通过即时有效的强化得到强化。
An Input's Value
Learning to Predict
The Adaptive Critic Learning Rule
Effective Reinforcement
The Actor Learning Rule
Neural Implementation
The Case of Terminal Primary Reinforcement
Conclusion