Django框架之第八篇(模型层补充)--数据库的查询与优化:only/defer,select_related与prefetch_related,事务
在设置外键字段时需要注意:
当你使用django2.x版本的时候,在建立外键关系的时候,需要你手动添加几个关键点参数
models.cascade #设置级联删除 db_constraints
数据库查询与优化
only和defer
orm内所有的语句操作,都是惰性操作:只会在你真正需要数据的时候才会走数据库,如果你单单只写orm语句不会走数据库。这样设计的好处是减轻数据库的压力
res = models.Book.objects.values('title') #普通查询方式 获取到的结果是列表套字典
res1 = models.Book.objects.only('title') #结果是一个普通对象,可以直接点属性获取到属性值
print(res)
print(res1)

only和普通查询的不同就是能直接获取到对象,除了可以获取到上面的title属性值,还可以直接获取到该对象其他的属性值。但是也有缺点
res1 = models.Book.objects.only('title')
for r in res1:
print(r.title) #只走一次数据库查询
print(r.price) #每取一次数据就走一次数据库
r.title

r.price

only总结:当你获取一个不是only括号内指定的字段的时候,不会报错,而是会频繁的走数据库查询
deger 与only是相反的
res1 = models.Book.objects.defer('title')
for r in res1:
print(r.print) #不是括号内的字段只走一次查询

defer总结:defer会将不是括号内的所有的字段信息全部查询出来封装到对象中,一旦你点击了括号内的字段,那么会频繁的走数据库查询
select_related与prefetch_related
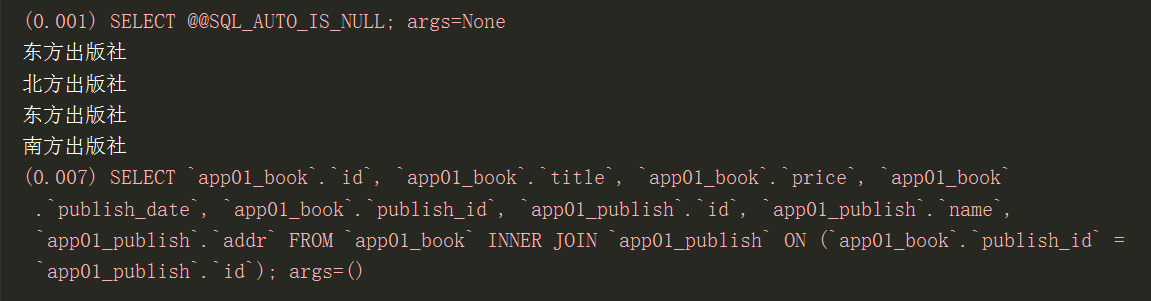
select_related帮你直接连表操作,查询数据库,括号内只能放外键字段
es1 = models.Book.objects.select_related('publish') #连接book表和publish表
for r in res1:
print(r.publish.name)
总结:select_related:会将括号内的外键字段所关联的那张表直接全部拿过来(也可以一次性拿多张表过来)跟当前表拼接操作,从而降低你跨表查询,数据库的压力。
注意:select_related括号内只能放外键字段(一对一和一对多)
res = models.Book.objects.all().select_related('外键字段1__外键字段2__外键字段3__外键字段4')
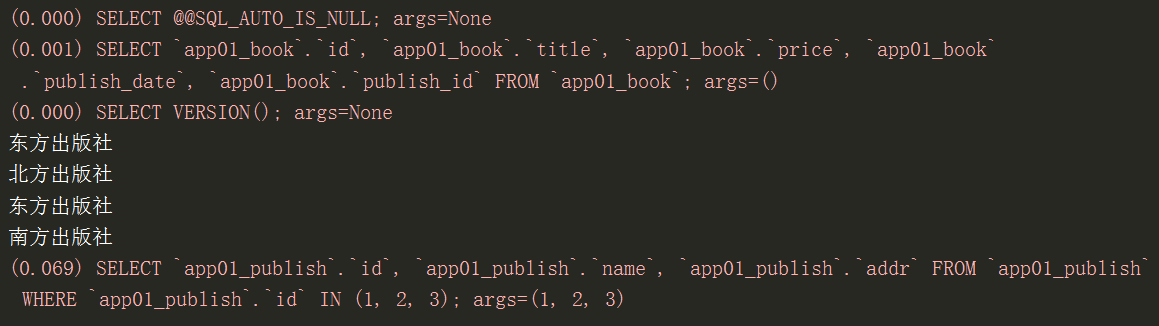
prefetch_related不主动连表
res2 = models.Book.objects.prefetch_related('publish')
for r in res2:
print(r.publish.name)
不主动连表操作(但是内部给你的感觉像是连表操作了)而是将book表中的publish全部拿出来,再取publish表中将id对应的所有的数据取出,括号内有几个外键字段,就会走几次数据库查询操作。
事务
ACID
原子性、一致性、隔离性、持久性
from django.db import transaction
with transaction.atomic():
"""数据库操作
在该代码块中书写的操作 同属于一个事务
"""
models.Book.objects.create()
models.Publish.objects.create()
# 添加书籍和出版社 就是同一个事务 要么一起成功要么一起失败
print('出了 代码块 事务就结束')