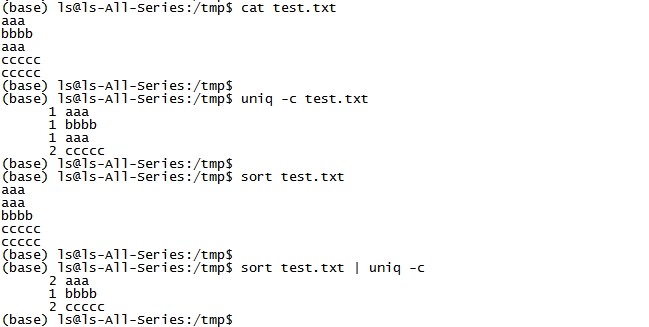
一、strings
strings--读出文件中的所有字符串。文件可以是二进制文件,也可以是文本文件;但一般是二进制文件,因为文本文件本来就都是字符串。
二、sed--文本编缉
助记:sed除了s命令外,其他命令基本都是“地址+命令+新增文本”的模式;如果地址由正则寻找得出,则正则前后用“/”包起来。
| 类型 | 命令 | 命令说明 |
| 字符串替换 | sed -i 's/str_reg/str_rep/' filename | 将文件每一行第一个str_reg字符组替换为str_rep |
| 字符串替换 | sed -i 's/str_reg/str_rep/g' filename | 将文件每一行所有str_reg字符组替换为str_rep |
| 行删除 | sed -i '2d' filename | 将文件当前的第二行删除 |
| 行删除 | sed -i '2,5d' filename | 将文件当前的第二到第五行删除 |
| 行删除 | sed -i '/str_reg/d' filename | 将文件有字符串匹配str_reg的行删除 |
| 行前插 | sed -i '2istr_insert' filename | 在文件当前的第二行前新插入一行,内容为str_insert |
| 行前插 | sed -i '2,5istr_insert' filename | 在文件当前的第二到第五行前都 新插入一行,内容为str_insert |
| 行前插 | sed -i '/str_reg/istr_insert' filename | 在文件有字符串匹配str_reg的行前插入一行,内容为str_insert |
| 行后插 | sed -i '2astr_insert' filename | 在文件当前的第二行后新插入一行,内容为str_insert |
| 行后插 | sed -i '2,5astr_insert' filename | 在文件当前的第二到第五行后都新插入一行,内容为str_insert |
| 行后插 | sed -i '/str_reg/astr_insert' filename | 在文件有字符串匹配str_reg的行后插入一行,内容为str_insert |
三、awk--报表生成
awk [-F:] '[BEGIN{ commands }] [{ commands }] [END{ commands }]' filename
-F指定分割符的标志,默认为空格(连续多个空格按一个算,tab等也算空格)
BEGIN语句块在读取第一行前执行
中间语句块在读取每行后都执行
END语句块在全部读取完后执行
各语句块中的命令一般都只是print语句和简单的加减运算
四、cut--文字节选
cut [-d ":"] [-f 1,2] filename
-d指定分格符
-f指定打印出的区域,注意不像awk那样有0域
五、uniq--文字去重(以行为单位)
uniq [-c] filename
-c统计该行重复次数
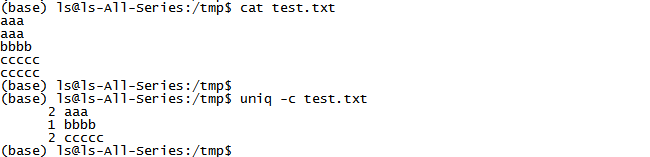
六、sort--文字排序(以行为单位)
sort [-u] filename
-u--使用uniq去除重复行(注意,uniq只能去除相临的重复行,不相临的重复行是不能去除的,所以uniq通常要sort配合使用)