虚拟化概述
将底层的计算机资源虚拟成多组彼此之间互相隔离的计算平台,并且每一个计算平台都应该有五大部件的所有设备(运算器,控制器,存储器,IO设备)。
虚拟化技术的分类
模拟:硬件+操作系统+模拟器软件,虚拟机的cpu架构和物理cpu的架构可以不一致。(模拟器模拟出来的CPU指令集和底层物理CPU的指令集不同,就需要虚拟机监视器将模拟的CPU指令集转化为真正物理CPU的指令集,这个过程需要软件参与而且性能差)
常用的模拟又:PearPC, Bochs, QEMU
完全虚拟化:虚拟CPU和物理CPU的架构完全相同。(虚拟CPU和物理CPU的架构完全相同,对虚拟机而言只要不是调用到特权指令或敏感指令,普通指令就能直接在底层物理CPU上执行,无需进行转化。如果虚拟机调用到特权指令,特权指令由虚拟机监视器捕获后进行翻译后转化成宿主机的指令集 或者 虚拟机向虚拟机监视器(VMM)通过调用hypersor call的方式来实现,这取决于是完全虚拟化还是半虚拟化。完全虚拟化可以借助于HVM技术省略指令转换的过程)
常见的完全虚拟化有:VMware Workstation, VMware Server, Parallels Desktop, KVM, Xen
半虚拟化:para-virtualization
在硬件之上运行hypervisor,hypervisor将底层功能通过hypervisor call向上输出,要开发能够运行在hypervisor上的操作系统时,内核需要调用hypervisor call进行开发(称为API),运行时也需要调用hypervisor call运行(称为ABI)。所以各个虚拟机的内核是经过修改的,这样虚拟机自身就知道自身是运行在虚拟化环境中。所以在半虚拟化环境中需要修改guest os的内核。(通常IO半虚拟化无需修改内核,只需安装特定驱动即可。CPU半虚拟化需要修改内核)
常见的半虚拟化有:xen, uml(user-mode linux)。
早期的xen只支持半虚拟化,后面也支持完全虚拟化。kvm一开始设计就是完全虚拟化。所以kvm性能比xen好;半虚拟化需要修改客户机操作系统内核、完全虚拟化不需要改客户机操作系统内核。
OS级别的虚拟化:容器级虚拟化
上述的虚拟化方式中的每个虚拟机都有自身独立的用户空间和内核空间,而底层对虚拟机管理的方式是通过hypervisor或host上的VMM(虚拟机监视器)实现,创建虚拟机的目的提供用户空间来提供服务,内核空间无意义,所以操作系统虚拟化就是将虚拟化向下推了一层即在底层硬件之上运行一个内核,在内核运行一个虚拟化管理器,虚拟化管理器上只提供用户空间,而没有提供内核空间,每个用户空间共享使用内核,这样就实现将用户空间分隔为多个,彼此间互相隔离。(稳定性低,但是性能好)
常用的容器级虚拟化由:OpenVZ、LXC
库虚拟化:虚拟出一个程序运行所依赖的库环境。
wine,实现在linux运行windows程序。
应用程序虚拟化:
jvm
实现虚拟化的两种实现方式
Type-I:在硬件上没有安装操作系统,而是直接安装hyper,hyper就是一个虚拟化软件,可以直接控制硬件。
xen, vmware ESX/ESXi
Type-II:在硬件上安装操作系统,在操作系统上安装虚拟化软件,在虚拟化软件上创建虚拟机。
kvm, vmware workstation, virtualbox
基础理论
cpu结构:
cpu分割成4个环,环3上运行普通指令,环0上运行特权指令(包括直接操作硬件的指令、操作cpu中与硬件管控相关的寄存器,都必须使用环0中的指令才能运行),环1环2未使用。操作系统在研发时就明确指定了内核空间中的指令在环0上执行,用户空间中的指令在环3上执行。用户空间的进程运行时只要不是特权指令直接在cpu上执行;如果是特权指令,该指令由内核捕获,由内核基于系统调用的方式来帮进程在环0上执行特权执行,执行后再将结果返回给进程。
当一个操作系统启动后,操作系统本身不执行任何生产任务,真正的生产功能由进程提供,因此操作系统运行时为了能够协调多任务,操作系统被分割成了两段用户空间和内核空间
内核空间:能够操作硬件,具有特权权限,运行在环0上;
用户空间:进程运行在用户空间,运行在环3上;
当用户空间中的进程要想执行特权指令或使用硬件时,需要通过系统调用来实现。
概念
宿主机:通常称为vm monotor即虚拟机监控器又称为hypervisor ,hypervisor直接管理硬件(一般只管理cpu 内存,IO设备不归hypervisor管理),相当于内核。hypervisor将CPU和内存的使用、分配过程虚拟成hyper call;对内核的调用称为系统调用;对hypervisor的调用称为hyper调用。
引入虚拟化后的问题
虚拟机是完整的主机,也由内核空间和用户空间组成,理论上虚拟机上的内核能够控制所有资源,这样也可以影响其它的虚拟机,导致了虚拟机之间可以互相影响,为了避免这种情况的产生,虚拟机上的cpu是通过软件模拟的,模拟出来的cpu也有环0、环1、环2、环3,同样内核空间运行在环0上,用户空间运行在环3上;当虚拟架构和物理架构一致时,虚拟机上用户空间的进程依然可以直接运行在cpu的环3上,这时只要特权指令由宿主机的虚拟机管理器捕获,将特权指令进行转换,转换后在物理cpu的环0上执行,执行后再将结果返回给虚拟机;如果虚拟架构和物理架构不一样,虚拟架构(ppc)、物理架构(x86),很显然虚拟架构用户空间的指令集和物理架构用户空间的指令集不同,这时用户空间的指令也要通过转化成宿主机的指令集,这样效率低。
cpu虚拟化:将CPU按时间切割,实现物理CPU资源的分时复用
cpu虚拟化可以通过模拟和虚拟两种方式实现。
模拟:emulation,物理架构和虚拟机架构可以不一致,通过纯软件方式实现,效率低;模拟通过软件方式实现cpu时,需要模拟ring0 1 2 3。
虚拟:virtulization,物理架构和虚拟机架构保持一致。
基于二进制翻译的全虚拟化(full-virtulization):VMM完全虚拟出一个虚拟平台,guest甚至不知道自己是运行在虚拟平台上;
VMM运行在ring 0,Guess OS的内核空间运行在ring 1,Guess OS上的用户空间运行在ring 3。Guess OS会在ring 1上执行特权指令,这种在非特权级别上执行特权级别的指令会产生异常(trap),VMM可以捕捉到该异常,VMM发现拦截到的是特权指令就会转化成对虚拟机操作的虚拟化指令进行执行。ring 3上执行的非特权指令不会被VMM拦截,直接在物理CPU上的ring 3上执行。(x86架构存在虚拟化漏洞,在X86架构下存在19条非特权指令能够影响系统状态,这19条非特权指令不会被VMM拦截。所以在x86虚拟化架构中需要将这19条非特权指令转变成对系统无威胁的指令去执行。将19条非特权指令称为临界指令,我们将特权指令和临界指令统称为敏感指令。在全虚拟化的场景下虚拟机无法感知自身是运行在虚拟化环境中,由VMM对敏感指令做BT即二进制翻译成对虚拟机操作的虚拟化指令,这种通过BT的方式无需虚拟机通过修改内核的方式来弥补虚拟化漏洞,但是性能低下。)
半虚拟化(para-virtulization)
CPU半虚拟化需要修改guess os的内核,使得guest的内核是明确知道自身是运行在虚拟化环境中的,所以当guest需要运行敏感指令时不是直接调用敏感指令而是通过hypervisor call将指令发送给VMM,因此guest对敏感指令的调用就被简化成了简单的对于宿主机VMM中某些敏感指令的请求,这种方式就无需VMM捕获异常和BT技术,这就使得guest内核和host相交互的过程大大被简化了。
硬件辅助的全虚拟化:完全虚拟化和半虚拟化适用于物理CPU不支持虚拟化或者在BIOS中没有打开VT功能的场景(KVM只能运行在硬件辅助虚拟化场景中)
物理CPU支持虚拟化,即在BIOS中打开VT-X功能。CPU工作在两种模式下:root模式和non-root模式,VMM工作在root模式,guess os工作在non-root模式。root模式有ring 0 1 2 3,VMM运行在ring 0;non-root模式也有ring 0 1 2 3,guess os运行在ring 0。当guess os发送敏感指令时,指令会被CPU的non-root模式进行处理,non-root模式会发现该指令为敏感指令会切换至root模式让VMM进行翻译将敏感指令转化成对相应虚拟机操作的虚拟化指令。其它非特权指令直接在物理CPU的ring 3上直接执行。
模拟和虚拟化的区别:
模拟:虚拟机所有的硬件设备使用软件来模拟,物理架构和虚拟机架构可以不一致;
虚拟化:底层硬件平台架构与虚拟机的平台架构相同。
CPU虚拟化性能计算

VCPU个数计算:

复用率建议:
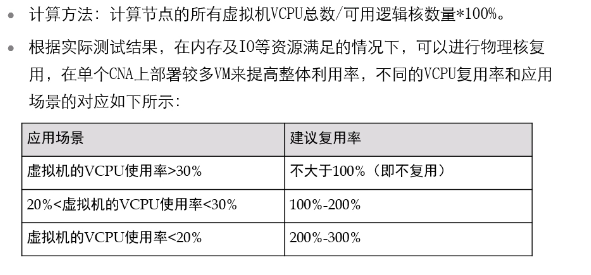
内存虚拟化:将内存按空间切割
内存本身就是虚拟化的,每个进程识别到的是线性地址空间,内核是物理地址空间。在简单的单机场景中,安装完操作系统后,内核能够分配使用整段物理内存空间。在虚拟化环境中,通过hyper来管理物理内存,在hyper中内存被分成内存页后划分给各虚拟机即虚拟机拿到的内存是离散的。
虚拟机上的一个进程访问某一内存空间中的数据时:
进程运行在虚拟机的cpu上,进程向cpu发出了对某一线性地址空间(称为GVA)中数据的访问,cpu会将该地址空间转给MMU(内存管理单元),MMU根据内核为每一个进程维护的内存映射表找出该线性地址空间对应的虚拟物理地址(称为GPA),在hyper上还需通过软件将GPA的调用再次转换至物理地址(HPA)。经过了两次虚拟地址的转换。在转换时,会将GVA和HPA的对应关系缓存至TLB,当多个虚拟机的操作系统在cpu上切换时会造成混乱,所以每次虚拟机切换时都要清空TLB。所以这种会造成TLB命中底下,为了解决这种问题,在硬件级别使用MMU 虚拟化。
MMU Virtulization:Intel: EPT, Extended Page Table和AMD: NTP, Nested Page Table
实现虚拟内存和物理内存的映射。
当vm中的进程向虚拟cpu调用线性地址空间,MMU将GVA转化为GPA的同时,MMU虚拟化会自动完成GVA和HPA的转化(即拥有两层MMU)。所以在虚拟化技术中,虚拟机中的每一个进程依然是从GVA转化成GPA;只不过借助于CPU上MMU的虚拟化技术,同时将GPA直接映射成HPA,省略了GPA到HPA的转化(通过硬件方式),从而提升了虚拟化性能。
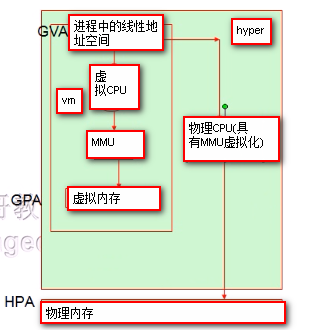
问题:上述借助于CPU上MMU的虚拟化技术,提升了虚拟化性能,但是TLB的命中率仍然无法提高,TLB中缓存的仍然是GVA到HPA的映射关系,虚拟机切换时仍然要清空TLB。为了提高TLB的命中率,于是有了TLB虚拟化。
TLB virtulization:tagged TLB
默认TLB中缓存的是GVA到HPA的映射关系,在TLB virtulization技术中增加了一个字段,即虚拟机的标识符。
内存技术:
大内存页
GPA到HPA的映射关系即内存映射表保存在内存中,为了优化性能会将内存映射表存放在CPU的寄存器中即TLB(页面缓冲寄存器),但是寄存器是比较小的,所有只能存放部分内存映射表。于是就有命中率的问题。当GPA到HPA的映射关系在TLB中可以查找到的话,则cache命中,性能就好;当GPA到HPA的映射关系在TLB查找不到时就会到内存中查找,性能就不太好(因为CPU到寄存器中查找的速度快于到内存中查找的速度)。为了提高cache的命中率,就修改TLB表,比如将虚拟内存所对应的物理内存从1k变成4k,这样就能提高cache命中率。
NUMA架构
早先的服务器都是单CPU,性能无法满足需求,于是就有了多CPU的服务器,如何在一台服务器内放置多个CPU:
1.SMP架构
能够在一台服务器上放置多个CPU,多个CPU共享内存,但会有内存冲突的问题。
2.MPP架构
多个节点,每个节点可以设置为SMP,也可以设置非SMP。多个节点之间不会共享内存。
3.NUMA架构
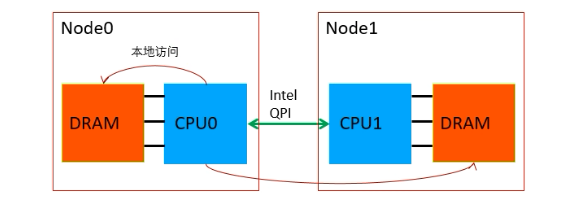
多个节点,每个节点拥有一个CPU和自己的内存,多个节点之间可以共享内存。CPU使用内存的时候,如果访问本节点的内存速度快,跨节点访问内存速度慢。基于该特点有两种技术:
1.host NUMA
在宿主机BIOS上启用MUMA,开启host NUMA后,宿主机操作系统能够识别主机内部的NUMA架构。好处是:1.当宿主机创建虚拟机时,优先使用同个node的CPU、内存。2.当宿主机创建虚拟机时,会查看哪个node的CPU、内存资源较空闲,将虚拟机创建在该node上。
2.guest NUMA
在集群中启用guest NUMA,开启guest NUMA后,集群集群下的虚拟机能够识别宿主机内部的NUMA架构,当虚拟机上的应用程序使用内存的时候,优先使用本节点的内存。
主机内存超分配

内存复用技术
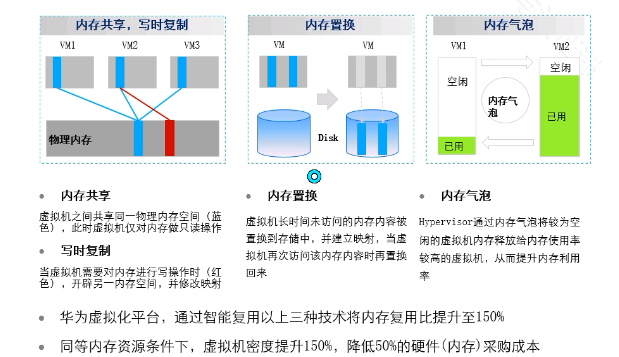
内存复用技术和guest NUMA冲突:因为在内存复用中存在内存置换,会将内存中的内存置换到硬盘,guest NUMA技术无法访问硬盘上的数据。优先使用内存复用技术。
I/O虚拟化(硬件要支持VT-D)
外存:硬盘、光盘、U盘
网络设备:网卡
显示设备:VGA: frame buffer机制
键盘鼠标:通过模拟实现
ps/2, usb
I/O虚拟化的方式:
全虚拟化IO设备:workstation、kvm、xen
VMM通过软件(QEMU)模拟出IO设备,VMM捕获Guess os对物理IO设备的访问请求,然后将IO请求转化成对底层硬件设备的操作;
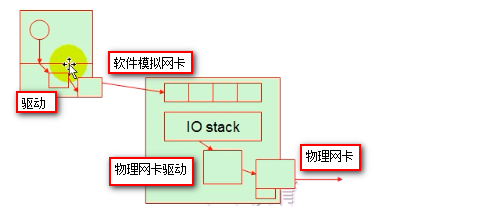
半虚拟化
在完全虚拟化的IO设备的情况下,虚拟机上有内核空间和用户空间,虚拟机某个程序要向发送一个网路包,程序无法直接和网卡打交道,程序向内核发起对网卡设备的系统调用,此时内核要通过驱动程序驱动网卡设备,这个网卡设备由软件模拟的,所以驱动后的结果依然不是能够向外发送报文的网卡设备,所以这个模拟的网络设备还要转化为对hyper的调用,最终转化为在hyper上的一个软件模拟网卡设备,在hyper上虚拟网卡可能存在多个,但是物理网卡只能存在有限个,所以hyper上的虚拟网卡要想向外发送网络报文都要转化成真正的物理网卡向外发送网络报文,IO路径长,性能差。
在以上的过程中在左边的驱动过程是没有意义的。在半虚拟化中虚拟机内核明确知道自身的网卡设备是虚拟的,所以就不会在本地通过驱动的方式调用该虚拟设备,而是在本地通过前端驱动的方式即对虚拟设备的调用直接转换到后端去,减少了IO路径,提高性能。如下图:
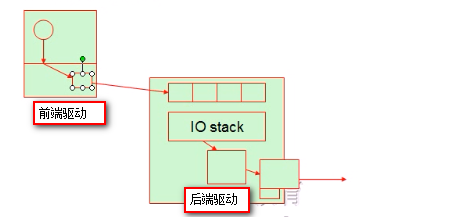
IO半虚拟化通常由virtio实现,分成两段,virtio架构如下图:
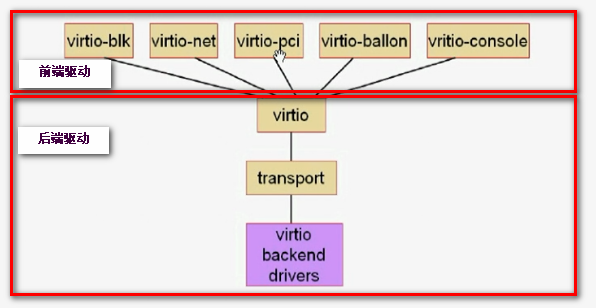
前端驱动:virtio前半段,virtio前半段在虚拟机实例中即创建虚拟机时内核已经加载了这些驱动模块,virtio前半段主要由virtio-blk,virtio-net,virtio-pci,virtio-balloon,virtio-console驱动组成。在CentOS 4.8+,5.3+,6.0+,7.0+内核中都直接支持前端驱动;windows系统中需要安装专用的程序才能实现;
virtio-balloon:让kvm中运行的GuestOS动态调整其内存大小
启用方式:
#qemu-kvm -balloon virtio
手动查看GuestOS的内存用量:
#info balloon
#balloon N
virtio-net:实现网络半虚拟化
其依赖于GuestOS中的前端驱动,及Qemu中的后端驱动
前端驱动:virtio_net.ko
后端驱动:qemu-kvm -net nic,model=?
启用方式:
#qemu-kvm -net nic,model=virtio
vhost-net:用于取代工作于用户空间的qemu中为virtio-net实现的后端驱动以实现性能提升的驱动(后端处理程序在qemu中实现即后端驱动是依赖qemu软件模拟实现,使用
vhost-net驱动可以提升性能)
#qemu-kvm -net tap,vnet_hdr=on,vhost=on
virtio-blk:实现块设备半虚拟化
其依赖于GuestOS中的前端驱动,及Qemu中的后端驱动。
启用方式“
-drive file=/path/to/some_image_file,if=virtio
virtio:虚拟队列。所有虚拟机的io请求都将发往该队列,相应的后端处理程序从队列中取出请求并响应请求;
transport:传输层,即将前端驱动发来的任何队列由transport发往后端处理程序;
后端驱动(virtio backend drivers):后端驱动在qemu中实现即后端驱动是依赖qemu软件模拟实现,后端处理程序驱动相应的物理设备处理请求。
IO-through: IO透传,需要硬件支持VFIO(实现USB,PCI and SCSI passthrough)
让虚拟机直接使用物理设备(需要在虚拟机上安装对应硬件的驱动程序)。仍然需要hyper去协调,可以接近于硬件性能。但是无法实现虚拟机迁移,虽然性能提升明显,但是应用范围不大。
IO虚拟化总结:
完全虚拟化场景中,虚拟机对IO的请求被VMM捕获,由VMM分时的调用底层硬件资源;半虚拟化场景中,虚拟机对IO的请求发给后端驱动,由后端驱动直接调用底层硬件资源;硬件辅助虚拟化场景中,虚拟机对IO的请求直接调用底层硬件资源。
总结:
完全虚拟化和半虚拟化的区别是:虚拟机是否要协助VMM完成虚拟机所需要的虚拟化环境。虚拟机无感知,即无需修改guest os内核,就是完全虚拟化;让虚拟机感知自身运行在虚拟化环境中,就要修改guest os内核,就是半虚拟化。注意:kvm只要完全虚拟化和硬件辅助虚拟化,没有半虚拟化。